 MySQL 高可用MGR(一) 理论
MySQL 高可用MGR(一) 理论
# 背景
主从复制,一主多从,主库提供读写功能,从库提供只读功能。当一个事务在 master 提交成功时,会把 binlog 文件同步到从库服务器上落地为 relay log 给 slave 端执行,这个过程主库是不考虑从库是否有接收到 binlog 文件,有可能出现这种情况,当主库 commit 一个事务后,数据库发生宕机,刚好它的 binlog 还没来得及传送到 slave 端,这个时候选任何一个 slave 端都会丢失这个事务,造成数据不一致情况。 为了避免出现主从数据不一致的情况,MySQL 引入了半同步复制,添加多了一个从库反馈机制,即半同步复制。这个有两种方式设置:
- 主库执行完事务后,同步 binlog 给从库,从库 ack 反馈接收到 binlog,主库提交 commit,反馈给客户端,释放会话;
- 主库执行完事务后,主库提交 commit ,同步 binlog 给从库,从库 ack 反馈接收到 binlog,反馈给客户端,释放会话;
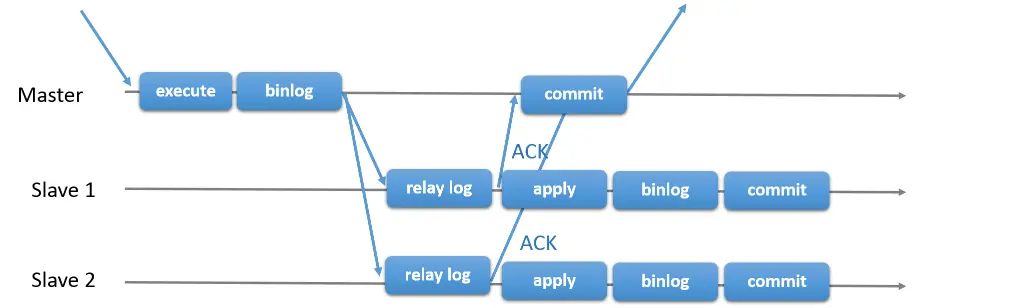
虽然满足了一主多从,读写分析,数据一致,但是,依旧有两个弊端:
- 写操作只能在 master 上;
- 如果 master 宕机,需要人为选择新主并重新给其他的 slave 端执行 change master;
为了解决一系列问题,官方推出了 MySQL Group Replication,从 group replication 发布以后,就有 3 种方法来实现 MySQL 的高可用集群:
- 异步复制
- 半同步复制
- group replication
# Group Replication 原理
MySQL Group Replication 有两种模式,单主模式 single-primary mode 和多主模式 multi-primary mode,在同一个 group 内,不允许两种模式同时存在,并且若要切换到不同模式,必须修改配置后重新启动集群。
# 1 单主模式
在单主模式下,只有一个节点可以读写,其他节点提供只读服务。单主模式下 ,当主节点宕掉,自动会根据服务器的 server_uuid 变量和 group_replication_member_weight 变量值,选择下一个 slave 谁作为主节点,group_replication_member_weight 的值最高的成员被选为新的主节点,该参数默认为 50,建议可以在节点上设置不同值;在 group_replication_member_weight 值相同的情况下,group 根据数据字典中 server_uuid 排序,排序在最前的被选择为主节点。
# 2 多主模式
在 mysql 多主模式下,在组复制中通过 Group Replication Protocol 协议及 Paxos 协议 (一致性算法) (opens new window),形成的整体高可用解决方案,同时增加了 certify (认证) 的概念,负责检查事务是否允许提交,是否与其它事务存在冲突,Group Replication 是由多个节点共同组成一个数据库集群,每个节点都可以单独执行事务,但是 read-write(rw)的操作只有在组内验证后才可以 commit,Read-only (RO) 事务是不需要验证可以立即执行,当一个事务在一个节点上提交之前,会在组内自动进行原子性的广播,告知其他节点变更了什么内容 / 执行了什么事务,然后为该事物建立一个全局的排序,最终,这意味着所有的服务器都以相同的顺序接收相同的事务集。因此,所有服务器都按照相同的顺序应用相同的变更集,因此它们在组中保持一致。 在多主模式下,该组的所有成员都设置为读写模式,在多主模式下,不支持 SERIALIZABLE (严格的) 事务隔离级别,且不能完全支持级联外键约束。
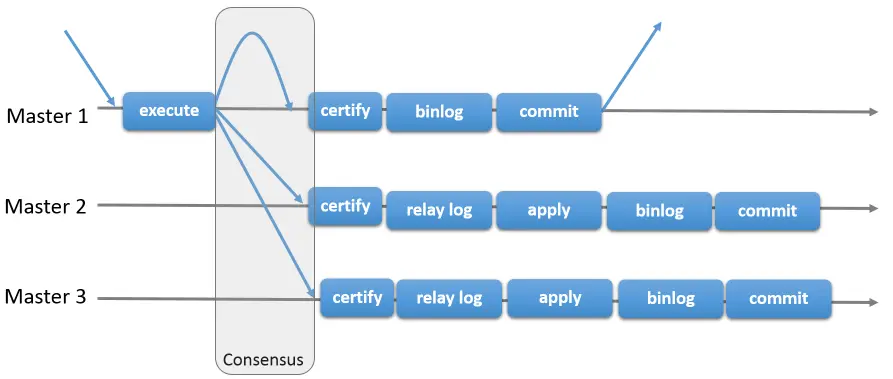
# 3 事物隔离级别补充
# Read Committed
在 Read Committed 隔离级别下,一个事务可能会遇到不可重复读(Non Repeatable Read)的问题。不可重复读是指,在一个事务内,多次读同一数据,在这个事务还没有结束时,如果另一个事务恰好修改了这个数据,那么,在第一个事务中,两次读取的数据就可能不一致。
我们先准备好 students 表的数据:
mysql> select * from students;
+----+-------+
| id | name |
+----+-------+
| 1 | Alice |
+----+-------+
1 row in set (0.00 sec)
2
3
4
5
6
7
然后,分别开启两个 MySQL 客户端连接,按顺序依次执行事务 A 和事务 B:
| 时刻 | 事务 A | 事务 B |
|---|---|---|
| 1 | SET TRANSACTION ISOLATION LEVEL READ COMMITTED; | SET TRANSACTION ISOLATION LEVEL READ COMMITTED; |
| 2 | BEGIN; | BEGIN; |
| 3 | SELECT * FROM students WHERE id = 1; | |
| 4 | UPDATE students SET name = 'Bob' WHERE id = 1; | |
| 5 | COMMIT; | |
| 6 | SELECT * FROM students WHERE id = 1; | |
| 7 | COMMIT; |
当事务 B 第一次执行第 3 步的查询时,得到的结果是 Alice,随后,由于事务 A 在第 4 步更新了这条记录并提交,所以,事务 B 在第 6 步再次执行同样的查询时,得到的结果就变成了 Bob,因此,在 Read Committed 隔离级别下,事务不可重复读同一条记录,因为很可能读到的结果不一致。
# Serializable
Serializable 是最严格的隔离级别。在 Serializable 隔离级别下,所有事务按照次序依次执行,因此,脏读、不可重复读、幻读都不会出现。
虽然 Serializable 隔离级别下的事务具有最高的安全性,但是,由于事务是串行执行,所以效率会大大下降,应用程序的性能会急剧降低。如果没有特别重要的情景,一般都不会使用 Serializable 隔离级别。
默认隔离级别
如果没有指定隔离级别,数据库就会使用默认的隔离级别。在 MySQL 中,如果使用 InnoDB,默认的隔离级别是 Repeatable Read。
# Repeatable Read
在 Repeatable Read 隔离级别下,一个事务可能会遇到幻读(Phantom Read)的问题。幻读是指,在一个事务中,第一次查询某条记录,发现没有,但是,当试图更新这条不存在的记录时,竟然能成功,并且,再次读取同一条记录,它就神奇地出现了。
mysql> select * from students;
+----+-------+
| id | name |
+----+-------+
| 1 | Alice |
+----+-------+
1 row in set (0.00 sec)
2
3
4
5
6
7
然后,分别开启两个 MySQL 客户端连接,按顺序依次执行事务 A 和事务 B:
| 时刻 | 事务 A | 事务 B |
|---|---|---|
| 1 | SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; | SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
| 2 | BEGIN; | BEGIN; |
| 3 | SELECT * FROM students WHERE id = 99; | |
| 4 | INSERT INTO students (id, name) VALUES (99, 'Bob'); | |
| 5 | COMMIT; | |
| 6 | SELECT * FROM students WHERE id = 99; | |
| 7 | UPDATE students SET name = 'Alice' WHERE id = 99; | |
| 8 | SELECT * FROM students WHERE id = 99; | |
| 9 | COMMIT; |
事务 B 在第 3 步第一次读取 id=99 的记录时,读到的记录为空,说明不存在 id=99 的记录。随后,事务 A 在第 4 步插入了一条 id=99 的记录并提交。事务 B 在第 6 步再次读取 id=99 的记录时,读到的记录仍然为空,但是,事务 B 在第 7 步试图更新这条不存在的记录时,竟然成功了,并且,事务 B 在第 8 步再次读取 id=99 的记录时,记录出现了。
可见,幻读就是没有读到的记录,以为不存在,但其实是可以更新成功的,并且,更新成功后,再次读取,就出现了。
# Read Uncommitted
Read Uncommitted 是隔离级别最低的一种事务级别。在这种隔离级别下,一个事务会读到另一个事务更新后但未提交的数据,如果另一个事务回滚,那么当前事务读到的数据就是脏数据,这就是脏读(Dirty Read)。
mysql> select * from students;
+----+-------+
| id | name |
+----+-------+
| 1 | Alice |
+----+-------+
1 row in set (0.00 sec)
2
3
4
5
6
7
然后,分别开启两个 MySQL 客户端连接,按顺序依次执行事务 A 和事务 B:
| 时刻 | 事务 A | 事务 B |
|---|---|---|
| 1 | SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; | SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; |
| 2 | BEGIN; | BEGIN; |
| 3 | UPDATE students SET name = 'Bob' WHERE id = 1; | |
| 4 | SELECT * FROM students WHERE id = 1; | |
| 5 | ROLLBACK; | |
| 6 | SELECT * FROM students WHERE id = 1; | |
| 7 | COMMIT; |
当事务 A 执行完第 3 步时,它更新了 id=1 的记录,但并未提交,而事务 B 在第 4 步读取到的数据就是未提交的数据。随后,事务 A 在第 5 步进行了回滚,事务 B 再次读取 id=1 的记录,发现和上一次读取到的数据不一致,这就是脏读。可见,在 Read Uncommitted 隔离级别下,一个事务可能读取到另一个事务更新但未提交的数据,这个数据有可能是脏数据。
# 配置要求 (opens new window)和限制 (opens new window)
- inndb 存储引擎;
- 每个表需要定义显式主键;
- 隔离级别:官网建议 READ COMMITTED 级别,不支持 SERIALIZABLE 隔离级别;
- 不建议使用级联外键;
- IPv4 网络;
- auto_increment_increment 和 auto_increment_offset 的配置;
- log-bin = ROW;
- log_slave_updates = ON;
- 开启 GTID;
- 安装引擎:group_replication.so;
# mysql 主从可以有多少个
可以成为一个复制组成员的 MySQL 服务器的最大数量为 9。如果其他成员尝试加入该组,则其请求将被拒绝。从测试和基准测试中可以确定此限制是安全的边界,在此范围内,组可以在稳定的局域网上可靠地运行。
# auto_increment_increment
在服务器上启动组复制时,auto_increment_increment 的值将更改为 group_replication_auto_increment_increment 的值(默认值为 7),而 auto_increment_offset 的值将更改为服务器 ID。 停止组复制时,将还原更改。 这些设置避免为组成员上的写入选择重复的自动增量值,这会导致事务回滚。 组复制的默认自动增量值为 7,表示可用值数与复制组的允许最大大小(9 个成员)之间的平衡。
仅当 auto_increment_increment 和 auto_increment_offset 各自的默认值均为 1 时,才进行更改并还原。如果已将其值从默认值修改,则组复制不会更改它们。 从 MySQL 8.0 开始,当组复制处于只有一个服务器写入的单主模式下时,系统变量也不会被修改。