 MySQL 8.x新特性总结
MySQL 8.x新特性总结
# 账户与安全
# 用户创建和授权
MySQL8.0 创建用户和用户授权的命令需要分开执行:
# 创建用户
create user '账户'@'%' identified by '密码';
# 给用户授权
grant all privileges on *.* to '账户'@'%';
2
3
4
8.0 中默认的 user 表比 5.7 中多出一个 mysql.infoschema 用户,5.7 中可以使用一条语句及可以创建用户还可以授权
# 5.7 中的语句
grant all privileges on *.* to '账户'@'%' identified by '密码';
2
# 认证插件
MySQL8.0 中默认的身份认证插件是 caching_sha2_password ,替代了之前的 mysql_native_password 。我们可以通过 default_authentication_plugin 系统变量,或者是数据库中 mysql.user 表可以看到这个变化。
# 使用系统变量查看
show variables like 'default_authentication%';
# 使用mysql.user表查看,这种可以看到每个所创建的用户用的是什么加密方式
select user,host,plugin from mysql.user;
2
3
4
5
如果是旧版本的客户端在连接 MySQL8.0 可能会出现身份认证错误,即使你输入对的账号密码,如果想解决这个问题,可以升级客户端支持 MySQL8.0,或者修改 MySQL8.0 的身份认证方式。
# 修改mysql自带的 /etc/my.cnf,添加如下,并重启
default_authentication_plugin=mysql_native_password
# 如果不想重启,只想对某个用户做修改,可以使用如下方式
alter user '账户'@'%' identified with mysql_native_password by '密码';
2
3
4
5
# 密码管理
MySQL8.0 开始允许限制重复使用以前的密码,也就是我们在修改密码的时候,要求我们不能修改为我们以前使用过的一些密码。变量如下:
# 新密码不能和最近3次使用过的密码相同,0不启用
password_history=3
# 新密码不能喝最近90天内使用的密码相同,0不启用
password_reuse_interval=90
# 修改密码的时候需要提供用户的当前登录密码,off关闭
password_require_current=ON
2
3
4
5
6
查看默认变量
show variables like 'password%';
修改变量的方式
# 通过修改 /etc/my.cnf 文件,并重启
password_history=3
password_reuse_interval=90
password_require_current=ON
# 设置全局变量,这种方式只针对当前进程有效,服务器重启恢复之前
set global password_history=3;
# mysql8.0新添加一种方式,这种方式不仅当前进程有效,并且服务器重启任然会生效
set persist password_history=3;
# 如果只想更改某个用户的限制
alter user '账户'@'%' password history 3;
# 设置完成后可以查看表是否多Password_reuse_history、Password_reuse_time、Password_reuse_current
desc mysql.user;
# 以上没有问题,我们可以查看该针对某个用户设置的值,如果全局有设置,则没设置的默认使用全局设置的
select user,host,Password_reuse_history from mysql.user;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
set persist 方式其实是新添加了一个配置文件 /var/lib/mysql/mysql-auto.cnf
# 通过该语句可以查看文件内容
more /var/lib/mysql/mysql-auto.cnf
2
完成后设置后,我们可以通过修改密码来进行测试
alter user '账户'@'%' identified by '密码';
修改密码的记录存在于 mysql.password_history 表中
select * from mysql.password_history
password_require_current=ON 不受 root 用户进行管制,只限制非 root 用户修改的时候才生效。
password_require_current=ON 非 root 用户修改密码的时候,会提示使用 REPLACE 关键字,整体修改密码语句如下
# user() 为当前 '账户'@'%'
alter user user() identified by '新密码' replace '当前密码';
2
# 角色管理
MySQL8.0 提供了角色管理的新功能,角色是一组权限的集合。
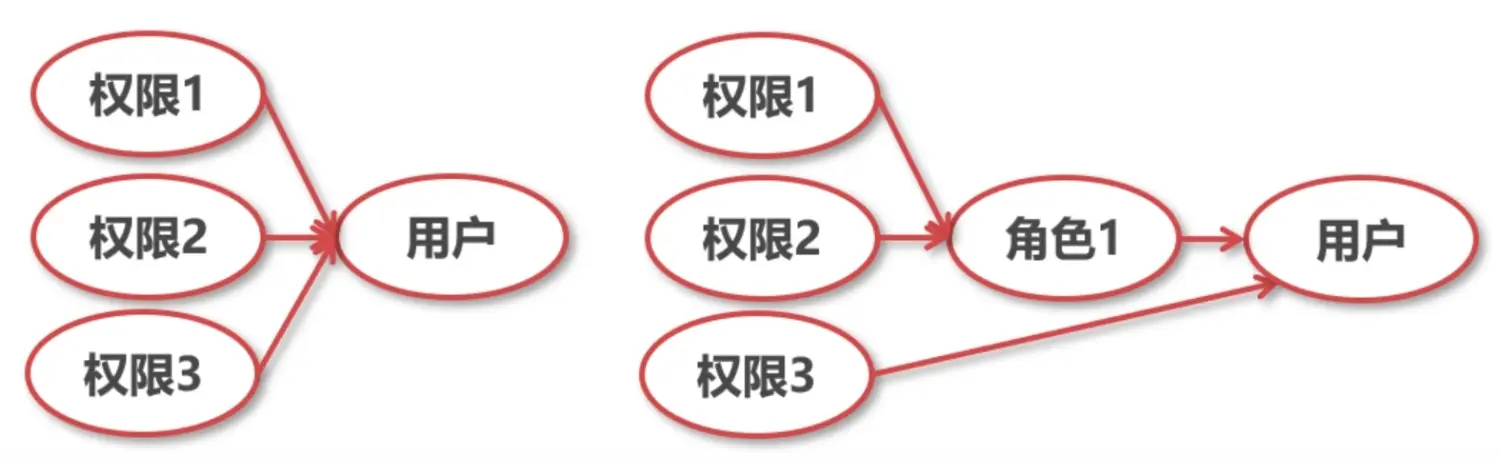
在 MySQL8.0 中创建角色,创建的角色会被对应的写到 mysql.user 表中,并且是没有密码的,所以角色相当于一个用户。
# 创建角色
create role '角色名称';
# 查看用户信息
select host,user,authentication_string from mysql.user;
2
3
4
角色授权,授权可以授权对应的操作权限(),并指定给哪个库,哪些表,* 代表所有表,然后给具体某个角色授权。
grant select,insert,update,delete on testdb.* to '角色名称'
用户授权
# 赋予用户权限
grant '角色名称' to '账户';
# 查看用户拥有哪些角色
show grants for '账户';
# 查看用户拥有哪些角色和具体的权限
show grants for '账户' using '角色名称';
2
3
4
5
6
用户授权后,我们可以更换用户进行登录,来对我们授权的用户和库进行操作。当被授权用户登录的时候,可能还是没有权限对库进行操作,需要当前用户给自己设置角色才行,类似于启用这个角色。
# 查看当前用户所拥有的的角色,没有则为 NONE
select currnt_role();
# 当前用户给自己设置角色
set role '角色名称';
2
3
4
当然每次给用户设置角色后,用户登录都需要自己启用这个角色是相当麻烦的,那我们可以设置默认角色。
# 如果要取消,则可角色名称可以为NONE
set default role '角色名称' to '账户';
# 如果有多个角色想要给某个账户设置
set default role all to '账户';
2
3
4
如果想要查询 mysql 中关于角色相关的一些信息,可以通过 mysql 库中的 default_roles 和 role_edges;
# 会查出有哪些已被设置默认的角色和用户
select * from mysql.default_roles;
# 角色授予的信息表,知道那个角色授予哪个用户(角色在mysql中是一种特殊的用户)
select * from mysql.role_edges;
2
3
4
对于角色来说,可以赋予角色相关的动作权限,当然也可以移除动作权限
# 移除角色对于testdb库的所有表的增删改权限
revoke insert,update,delete on testdb.* from '角色名称';
# 查看角色动作
show grants for '角色名称';
# 查看用户对应角色和动作权限
show grants for '账户名称' using '角色名称';
2
3
4
5
6
# 优化器索引
# 隐藏索引
MySQL8.0 开始支持隐藏索引(invisible index),不可见索引。隐藏索引不会被优化器使用,但任然需要进行维护,也就是数据的修改任然需要在后台进行索引的维护,依然有维护成本。隐藏索引多用于以下两个场景:
- 软删除,索引是需要维护成本的,如果某些表不需要索引可以直接删掉,但后期又要加索引,在数据量比较大的时候成本比较高,所以软删除提供隐藏索引,把索引设置为隐藏,这个时候查询优化器并不会使用索引,但依然会进行维护,当最终确定删除的时候,我们在将索引彻底删除。
- 灰度发布,这种方式通常用来做索引测试,在设计之初加上并设置为隐藏,当后期如果索引实际用到,我们则可以打开(加索引也需要成本,尤其数据量大)
隐藏缩影的创建语句
# 普通索引创建
create index '索引名称' on 表名(字段);
# 隐藏索引则是多了一个关键字 invisible
create index '索引名称' on 表名(字段) invisible;
# 我们可以通过语句来看索引是否可见,查看关键字 Visible
show index from 表名\G
2
3
4
5
6
7
我们可以实际测试,并使用 explain select ... 语句来验证。
通过语句也可以改变索引的可见和不可见。
# 设置为可见索引
alter table 表名 alter index '索引名' visible;
# 设置为隐藏索引
alter table 表名 alter index '索引名' invisible;
2
3
4
主键是不能设置隐藏索引的
# 降序索引
MySQL8.0 之前也可以使用降序索引的定义,但实际上 MySQL 服务会忽略我们这个定义,创建的还是升序索引,但是从 MySQL8.0 开始真正的支持了降序索引(descending index),但目前来说只有 innoDB 存储引擎支持降序索引,只支持 BTREE 降序索引。并且由于降序索引的引入,MySQL8.0 不再对 group by 操作进行隐式排序。
创建表并构建降序索引
# 创建 test表 并未c1和c2字段添加升序和降序索引
create table test(
c1 int ,
c2 int,
index idx1(c1 asc,c2 desc)
);
# 查看创建表的索引,发现 c2 后面会多一个 desc 降序索引,asc 升序索引默认不显示
show create table test\G
2
3
4
5
6
7
8
# 函数索引
具体的函数索引是在 MySQL8.0.13 开始支持在索引中使用函数(表达式)的值,新的函数索引支持降序索引,支持 JSON 数据的索引。函数索引是基于虚拟列功能实现的。
# 将列名的大写转换作为索引的值
create index '索引名称' on 表名( (UPPER(列名)) );
# 通过语句查看,可以通过关键字 Expression 查看
show index from 表名\G
2
3
4
触发优化器函数索引的语句
explain select * from 表名 where upeer(列名) = 'C';
函数索引对 JSON 进行索引,先要创建索引
# 创建一个表,字段data为JSON类型,并为其创建一个索引,CAST做类型转换。取json中name节点的值,并把数据转换成char(30)。
create table test(
data json,
index( (CAST(data ->>'$.name' as char(30))) )
)
# 查看该表索引情况
show index from 表名\G
# 触发索引语句
explain select * from test where CAST(data ->>'$.name' as char(30) = 'aaa';
2
3
4
5
6
7
8
9
如上所说函数索引是基于虚拟列功能实现的,可以理解成一下几步
# 1. 改变表添加一个新字段,值是以旧字段的值并转大写为结果
alter table 表名 add column 新字段 varchar(10) generated always as (upper(旧字段))
# 2. 建立索引
create index 索引名称 on 表名(新字段)
# 触发索引,会发现走的是新字段的索引
explain select * from 表名 where upper(旧字段)='AAA';
2
3
4
5
6
7
我们还可以把 JSON 里面的某个属性提取为一个虚拟列,当 JSON 里该属性的值发生变化,则虚拟列也会更新,然后对虚拟列做上索引,这样就会对查询速度有所提升。
ALTER TABLE 表名 ADD COLUMN '虚拟列名称' VARCHAR(32) generated always AS (
json_unquote(
json_extract(
'json字段名',_utf8mb4'$.属性'
)
)
) virtual NULL;
2
3
4
5
6
7
# 通用表表达式
# 非递归 CTE
MySQL8.0 开始支持通用表表达式(CTE),即 WITH 字句。简单示例如下:
# 以前子查询或派生表
select * from (select 1) as dd;
# 通用表表达式
with dd as (select 1) select * from dd;
# 通用表表达式
with dd(id) as (select 1),
dd2(id) as (select id+1 from dd)
select * from dd join dd2;
2
3
4
5
6
7
8
9
10
# 递归 CTE
递归 CTE 在查询中引用自己的定义,使用 recursive 表示,示例:
with recursive dd(n) as(
select 1
union all
select n+1 from dd where n < 5
) select * from dd;
2
3
4
5
递归限制,递归表达式的查询中需要包含个终止递归的条件
- cte_max_recursion_depth:最大递归的深度,如果没有条件终止,达到这个条件系统会提示错误
- max_execution_time:SQL 语句的最多执行时间,如果执行语句超过这个时间也会提示错误
查看参数
# 查看系统默认深度
show variables like 'cte_max%';
# 可以修改这个参数,session 为当前会话有效
set session cte_max_recursion_depth=10;
# 查看系统默认SQl执行时间,默认是0,没有限制,单位s
show variables like 'max_execution%';
set session max_execution_time=1000;
2
3
4
5
6
7
8
9
10
CTE 支持 select,insert,update,delete 等语句。
# 窗口函数
MySQL8.0 支持窗口函数(Window Function),也称为分析函数。窗口函数与分组聚合函数类似,但是每一行数据都生成一个结果。聚合窗口函数:sum/avg/count/max/min 等等都可以作为窗口函数来使用。
# 创建表
CREATE TABLE `sales` (
`year` int DEFAULT NULL,
`country` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`product` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`profit` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
# 表数据
INSERT INTO `sales` VALUES(2000,'F','C',1500),
(2001,'U','C',1200),
(2001,'F','P',10),
(2000,'I','Ca',75),
(2000,'U','T',150),
(2001,'I','C',1200),
(2000,'U','Ca',5),
(2000,'U','C',1500),
(2000,'F','p',100),
(2001,'U','Ca',50),
(2001,'U','C',1500),
(2000,'I','Ca',75),
(2001,'U','T',100);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
我们查询每个国家的利润总和,先用聚合函数实现:
SELECT country,SUM(profit) AS country_profit FROM sales
GROUP BY country ORDER BY country
country country_profit
------- ----------------
F 1610
I 1350
U 4505
2
3
4
5
6
7
8
我们用分析函数的写法
SELECT YEAR,country,product,profit,
# 按照国家分区
SUM(profit) over (PARTITION BY country) AS country_profit
FROM sales
ORDER BY country,YEAR,product,profit
year country product profit country_profit
------ ------- ------- ------ ----------------
2000 F C 1500 1610
2000 F p 100 1610
2001 F P 10 1610
2000 I Ca 75 1350
2000 I Ca 75 1350
2001 I C 1200 1350
2000 U C 1500 4505
2000 U Ca 5 4505
2000 U T 150 4505
2001 U C 1200 4505
2001 U C 1500 4505
2001 U Ca 50 4505
2001 U T 100 4505
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 专用窗口函数
除以上聚合函数也可以用来做窗口函数外,还提供了一些专用窗口函数。
- ROW_NUMBER () 用于数据排名的排名函数;
- RANK()
- DENSE_RANK()
- PERCENT_RANK()
- FIRST_VALUE () 用于获取窗口分组内的第一名;
- LAST_VALUE (),用于获取窗口分组内的最后一名;
- LEAD () 用于获取当前的后几名数据;
- LAG () 用于获取当前的前几名数据;
- CUME_DIST (),累计分布,数据累计到现在占了多少;
- NTH_VALUE (),排名第几名的函数;
- NTILE (Num),传入一个整数,把数据级按照整数分组(分为多少个组);
创建示例表和数据
# 表
CREATE TABLE `numbers` (
`val` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
# 插入语句
INSERT INTO `numbers`
VALUES(1),(1),(2),(3),(3),(3),(3),(4),(4),(5);
2
3
4
5
6
7
8
对 numbers 表数据进行排名
SELECT val,row_number() over (ORDER BY val) AS 'row_number'
FROM `numbers`
val row_number
------ ------------
1 1
1 2
2 3
3 4
3 5
3 6
3 7
4 8
4 9
5 10
2
3
4
5
6
7
8
9
10
11
12
13
14
15
SELECT val,
first_value(val) over (ORDER BY val) AS 'first',
lead(val,1) over (ORDER BY val) AS 'lead'
FROM `numbers`
val first lead
------ ------ --------
1 1 1
1 1 2
2 1 3
3 1 3
3 1 3
3 1 3
3 1 4
4 1 4
4 1 5
5 1 (NULL)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
SELECT val,
ntile(3) over (ORDER BY val) AS 'ntile3'
FROM `numbers`
val ntile3
------ --------
1 1
1 1
2 1
3 1
3 2
3 2
3 2
4 3
4 3
5 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 窗口定义
窗口和其他函数最大的区别是 over 关键字,over 中可以有多个条件
window_function(expr) over(
# 会对数据先进行分组
partition by ...
# 对于数据排序
order by ...
# 会进一步限定窗口
frame_clause...
)
2
3
4
5
6
7
8
frame_clause 定义了一些常用的关键字,如:
- current_row,当前行
- m preceding,如 1 preceding,则表示和当前行的上一行,也就是已经处理过的行,进行计算
- n following,如 2 following,则表示和当前行往下的两行,还没有被处理的行
- unbounded preceding,从分区中的第一行开始,延续往下处理所有数据,直到分区最后一行
- unbounded following,表示分区的最后一行
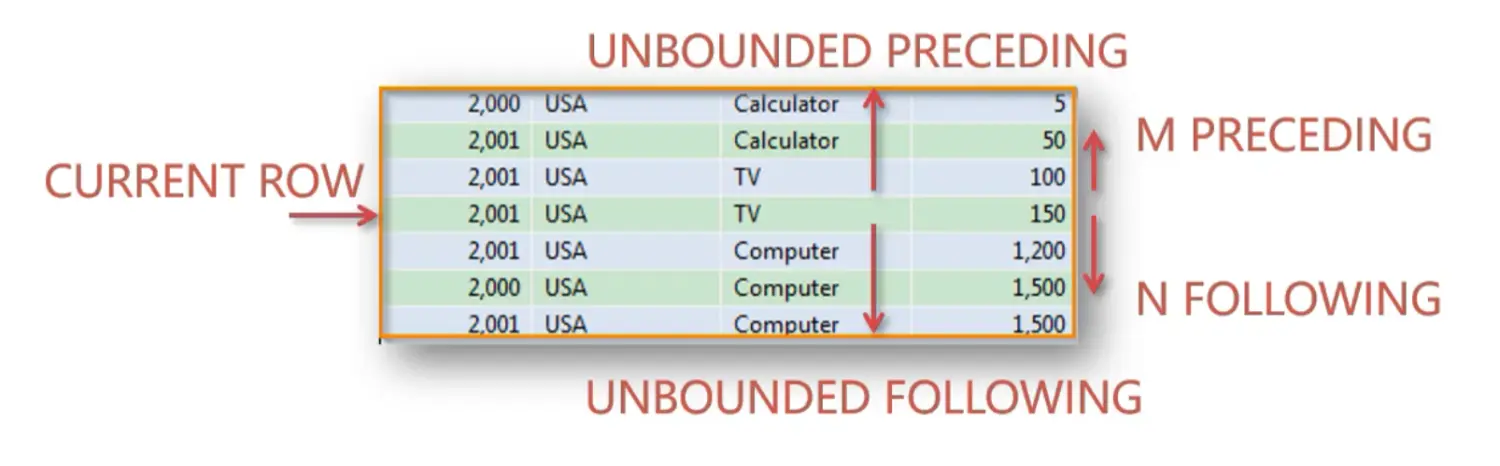
如图,当前行为 | 2,001 | USA | TV | 150 |,对于当前行的 unbounded preceding 来说是当前行以上的所有数据,对于当前行的 unbounded following 来说是当前行以下的所有数据,而 1 preceding,为当前行的上一行,2 following,则为当前行的下一行。
针对以上的 sales 表,按国家进行分区计算利润总和,按照分组内的产品进行排序,并在分区内计算利润累计和
SELECT *,
SUM(profit) over (
PARTITION BY country
ORDER BY product
ROWS unbounded preceding
) AS 'sum profit'
FROM `sales`
year country product profit sum profit
------ ------- ------- ------ ------------
2000 F C 1500 1500
2001 F P 10 1510
2000 F p 100 1610
2001 I C 1200 1200
2000 I Ca 75 1275
2000 I Ca 75 1350
2001 U C 1200 1200
2000 U C 1500 2700
2001 U C 1500 4200
2000 U Ca 5 4205
2001 U Ca 50 4255
2000 U T 150 4405
2001 U T 100 4505
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
针对以上的 sales 表,按国家进行分区计算利润总和,按照分组内的产品进行排序,并在分区内计算上一行和当前行以及下一行进行利润加和计算
SELECT *,
SUM(profit) over (
PARTITION BY country
ORDER BY product
ROWS BETWEEN 1 preceding AND 1 following
) AS 'sum profit'
FROM `sales`
year country product profit sum profit
------ ------- ------- ------ ------------
2000 F C 1500 1510
2001 F P 10 1610
2000 F p 100 110
2001 I C 1200 1275
2000 I Ca 75 1350
2000 I Ca 75 150
2001 U C 1200 2700
2000 U C 1500 4200
2001 U C 1500 3005
2000 U Ca 5 1555
2001 U Ca 50 205
2000 U T 150 300
2001 U T 100 250
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
SELECT *,
first_value(profit) over w AS 'first',
last_value(profit) over w AS 'last'
FROM `sales`
window w AS (
PARTITION BY country
ORDER BY profit
ROWS unbounded preceding
)
year country product profit first last
------ ------- ------- ------ ------ --------
2001 F P 10 10 10
2000 F p 100 10 100
2000 F C 1500 10 1500
2001 I C 1200 1200 1200
2000 I Ca 75 1200 75
2000 I Ca 75 1200 75
2001 U T 100 100 100
2001 U C 1200 100 1200
2000 U T 150 100 150
2000 U C 1500 100 1500
2001 U C 1500 100 1500
2000 U Ca 5 100 5
2001 U Ca 50 100 50
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# InnoDB 增强
# 集成数据字典
MySQL8.0 删除了之前版本的元数据文件,例如 .frm,.opt,关于触发器的一些 trigger 文件等,我们可以在新老版本的 /var/lib/mysql/mysql 下查看文件信息。
将系统表(mysql 数据库)和数据字典全部改为 InnoDB 存储引擎,从 8.0 之后,所有的数据字典信息都是用 innoDB 存储引擎进行统一的存储。
简化了 information_schema 的实现,提高了访问性能。
# 原子 DDL 操作
MySQL8.0 开始支持原子 DDL 操作,其中与表相关的原子 DDL 只支持 InnoDB 引擎。一个原子 DDL 操作内容包括:更新数据字典,存储引擎层的操作,在 binlog 中记录 DDL 操作,有了这几个步骤后,如果我们在这个操作出现了服务器崩溃,可以通过相应的恢复机制进行数据的重做或者是数据的回滚来保证我们 DDL 操作的事务原子性。
支持与表相关的 DDL:数据库、表空间、表、索引的 create、alter、drop 以及 truncate table。
支持其他的 DDL:存储程序、触发器、视图、UDF 的 create、drop 以及 alter 语句。
支持账户管理相关的 DDL:用户和用户角色的 create、alter、drop 以及适用的 rename,以及 grant 和 revoke 语句。
可以在 5.7 和 8 中使用以下方式进行测试,在 5.7 中删除语句会报错,但 t1 表依然会删除成功,在 8 中,删除失败,但表 t1 依然存在。
# 创建表
create table t1(id int);
# 删除表t1,t2
drop table t1,t2;
2
3
4
# 自增列持久化
MySQL5.7 以及早期版本,InnoDB 自增列计数器(auto_invcrement)的值只存储在内存中,当服务器故障或重启,mysql 会扫描自增列,找到当前的最大值,然后基于该值往上自增,在某些场景,初始化的值有可能是以前使用过的值,有可能会重复,通常来说我们使用自增配合主键一起使用,不允许有重复的列。
基于以上原因,MySQL8.0 每次变化时将自增计数器的最大值写入 redo log,同时在每次检查点将其写入引擎私有的系统表,如果系统下次重启恢复的时候,他可以通过写入的记录找到我们曾经使用或可能使用过的最大值,避免我们新生成的值和我们之前使用过的值重复的情况。
在 5.7 问题存在的演示
# 创建测试表
create table t(
id int auto_increment primary key,
c1 varchar(10)
)
# 数据插入
insert into t(c1) values('a'),('b'),('c');
id c1
------ -------
1 a
2 b
3 c
# 删除数据
delete from t where id = 3;
id c1
------ -------
1 a
2 b
# 重启数据库,并插入数据
insert into t(c1) values('d');
id c1
------ -------
1 a
2 b
3 d
# 更新值
update t set id=5 where c1 = 'a';
id c1
------ -------
2 b
3 d
5 a
# 插入新数据
insert into t(c1) values('e');
id c1
------ -------
2 b
3 d
4 e
5 a
# 再次插入数据,会报错 Duplicate entry '5' from key 'PRIMARY'
insert into t(c1) values('f');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
以上步骤如果使用 MySQL8.0 操作,你会发现在删除数据后重新启动并插入数据,此时 ID 为以前没被使用过的。如果像以上 update,再生成一条新的记录,则也不会出现主键重复的错误。
我们可以通过查看 innodb_autoinc_lock_mode 参数来发现他们的区别,在 5.7 中该值为 1(连续模式),在 8.0 中该值为 2(交叉模式),如果你使用基于语句的复制模式,要使用 1,如果是基于行的复制,使用 2,该方式可以提高性能。
show variables like 'innodb_autoinc%';
# 死锁检查控制
死锁是两个事务,它都需要进行一些数据的修改,而在修改的过程中,他们都需要等待对方释放某一些数据上的资源,因为他们互相之间没有感知,如果没有外界系统的介入的情况下,他们会一直等待下去,也就是这两个事务形成了一个死锁。
在 MySQL8.0 中,在后台会有一个实时监测的程序,它如果发现这种情况,它会让一个事务失败,而让另一个事务能够进行下去。当然,这个死锁检查它需要一定的代价,需要占用一定的系统资源。
MySQL8.0(5.7.15)增加了一个新的动态变量(innodb_deadlock_detect),用于控制系统是否执行 InnoDB 死锁检查。对于高并发的系统,禁用死锁检查可以带来性能的提高。
show variables like 'innodb_deadlock_detect';
以下提供了测试语句,当发生死锁的时候,会让一个事务进行报错,另一个成功。
# 开启第一个窗口
# 创建测试表
create table t(
item int
)
# 数据插入
insert into t(item) values(1);
# 开启事务
start transaction;
# 获取记录上的共享锁
select * from t where item = 1 for share;
# 切换到第二个窗口,同样开启事务并删除数据,删除数据记录需要相应的排他锁,但第一个窗口已经占用了共享锁,所以下面删除语句会进行等待
delete from t where item = 1;
# 切换到第一个窗口,也键入删除语句,此时这条语句需要以上释放锁才能继续进行下去,固然形成了死锁。
delete from t where item = 1;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
当我们关闭死锁检查的时候,还有个参数会帮我们进行限制,锁等待超时(innodb_lock_wait_timeout)
# 关闭死锁检查
set global innodb_deadlock_detect=off;
# 查看innodb_lock_wait_timeout默认时间,默认50s
show variables like 'innodb_lock_wait%';
# 可以把锁超时时间设置短一些
set global innodb_lock_wait_timeout=5;
2
3
4
5
6
进行设置完毕后,我们可以重复上面事务的死锁案例,它会报出如下错误
Lock wait timeout exceeded;try restarting transaction
# 锁定语句选项
在 MySQL 中的有两个可以对执行语句加锁的选项,select ... for share(共享锁 - 读锁) 和 select ...for update(排他锁 - 写锁) ,如果所查询的数据在其他事务中已经占用了相应的锁,那我们的语句需要做相应的等待,直到相应的事务释放锁,如果一直没有等待到,它会在等待超时后执行报错。
新的 8.0 对对两条加锁语句进行了两个选项
- nowait 如果请求的行被其他事务锁定时,语句立即返回
- skip locked 如果对查询的数据有些已经被锁定,跳过这些锁定的行,只返回没有被锁定的数据
# 开第一个会话窗口
# 创建测试表
create table t(
item int
)
# 数据插入
insert into t(item) values(1),(2),(3);
# 开启事务
start transaction;
# 修改语句,会自动添加排他锁,这里不进行commit不会释放锁
update t set iitem=0 where item = 2;
# 切换到第二个窗口,同样开启事务,并执行语句,该语句会被阻塞等待超时
select * from t where i=2 for update;
# 切换到第三个窗口,同样开启事务,并执行语句,该语句会立即返回报错
select * from t where i=2 for update nowait;
Statement aborted because lock(s) could not be acquired immediately and nowait is set.
# 切换到第四个窗口,同样开启事务,并执行语句,该语句会立即返回结果.
select * from t where i=2 for update skip locked;
item
------
1
3
# 切换到第一个窗口,也键入删除语句,此时这条语句需要以上释放锁才能继续进行下去,固然形成了死锁。
delete from t where item = 1;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# JSON 增强
JSON 的数据类型在 MySQL5.7 就已经出了,只是到 8.0 得到了一些增强
- 内联路径操作符 -> 它主要是用于获取 JSON 对象在某一些节点或者某些路径上面的一些数据值
- JSON 的聚合函数 -> 他可以将我们这种表中的列数据聚合成对应的 JSON 数组或者是 JSON 的对象
- JSON 实用函数 -> json 的实用函数主要是用于美观我们 JSON 对象输出,或是获取 JSON 对象所占用的存储空间
- JSON 的合并函数 -> 主要是将两个 JSON 对象合并成一个
- JSON 表函数 -> 它和聚合函数执行相反的操作,是将 JSON 的对象扩展成我们关系型数据库表,按照行和列方式组织数据
# 内联路径操作符
MySQL8.0 增加了 JSON 操作字符 column ->> path ,等价于:之前版本 JSON_UNQUOTE(column -> path) , JSON_UNQUOTE(JSON_EXTRACT(column,path)) 。
# 方式一 JSON_UNQUOTE使用方式
WITH doc(json) AS (SELECT json_object('id',3,'name','zs'))
SELECT json_unquote(json -> '$.name') FROM doc;
json_unquote(json -> '$.name')
--------------------------------
zs
# 方式二 JSON_UNQUOTE(json_extract())使用方式
WITH doc(json) AS (SELECT json_object('id',3,'name','zs'))
SELECT json_unquote(json_extract(json,'$.name')) FROM doc;
json_unquote(json_extract(json,'$.name'))
-------------------------------------------
zs
# 方式三 ->>
WITH doc(json) AS (SELECT json_object('id',3,'name','zs'))
SELECT json ->> '$.name' FROM doc;
json ->> '$.name'
-------------------
zs
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
MySQL8.0 内联路径操作符还扩展了范围操作
# 以前版本
SELECT json_extract('["a","b","c"]','$[1]');
json_extract('["a","b","c"]','$[1]')
--------------------------------------
"b"
# 现在版本 支持范围
WITH dd(json) AS (SELECT '["a","b","c"]')
SELECT json ->> '$[1 to 3]' FROM dd;
json ->> '$[last-2 to last]'
------------------------------
["a", "b", "c"]
WITH dd(json) AS (SELECT '["a","b","c"]')
SELECT json ->> '$[last-2 to last]' FROM dd;
json ->> '$[last-2 to last]'
------------------------------
["a", "b", "c"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# JSON 的聚合函数
MySQL8.0 增加了 2 个用于聚合的函数:
- JSON_ARRAYAGG () -> 用于将多行数据组合成一个 JSON 数组
- JSON_OBJECTAGG () -> 用于生成一个 JSON 对象
# 创建表
CREATE TABLE `t` (
`id` int DEFAULT NULL,
`att` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`value` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
# 新增数据
INSERT INTO t(id,att,VALUE)VALUES
(2,'color','red'),
(2,'fabric','silk'),
(3,'color','green'),
(3,'shape','square')
# 转成数组
SELECT id,json_arrayagg(att) AS attributes
FROM t GROUP BY id
id attributes
------ ---------------------
2 ["color", "fabric"]
3 ["color", "shape"]
# 转成对象
SELECT id,json_objectagg(att,VALUE) AS attributes
FROM t GROUP BY id
id attributes
------ ---------------------------------------
2 {"color": "red", "fabric": "silk"}
3 {"color": "green", "shape": "square"}
# 如果有相同属性,只会读取最后一个重复属性的值
INSERT INTO t(id,att,VALUE)VALUES (3,'color','yellow');
id attributes
------ ---------------------------------------
2 {"color": "red", "fabric": "silk"}
3 {"color": "yellow", "shape": "square"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# JSON 实用函数
- (5.7.22 加入了该函数) JSON_PRETTY (),在我们输出 JSON 对象内容的时候做一个格式化,一个美化的输出
- (5.7.22 加入了该函数) JSON_STORAGE_SIZE (),返回 JSON 数据所占用的存储空间
- JSON_STORAGE_FREE (),在更新某些 JSON 的列,计算出字段释放出来的存储空间
# 默认情况下的JSON格式
SELECT json_object('id','3','name','zs')
json_object('id','3','name','zs')
-----------------------------------
{"id": "3", "name": "zs"}
#美化后的JSON输出
SELECT json_pretty(json_object('id','3','name','zs'));
json_pretty(json_object('id','3','name','zs'))
------------------------------------------------
{
"id": "3",
"name": "zs"
}
#查看JSON占用大小,默认字节(B)
WITH dd(json) AS (SELECT json_pretty(json_object('id','3','name','zs')))
SELECT json,json_storage_size(json) FROM dd;
json json_storage_size(json)
------------------------------- -------------------------
{ 30
"id": "3",
"name": "zs"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# json 的合并函数
- JSON_MERGE_PATCH (),将两个 JSON 对象合并成一个对象,如果两个对象当中有相同的节点,它会使用第二个对象中的节点覆盖第一个节点
- JSON_MERGE_PRESERV (),将两个 JSON 对象合并成一个对象,如果存在两个相同的节点,会保留两个节点的值
- JSON_MERGE (),这个函数和上一个函数相似,但在 8.0 中已经被废弃
SELECT json_merge_patch('{"a":1,"b":2}','{"a":3,"c":4}');
json_merge_patch('{"a":1,"b":2}','{"a":3,"c":4}')
---------------------------------------------------
{"a": 3, "b": 2, "c": 4}
SELECT json_merge_preserve('{"a":1,"b":2}','{"a":3,"c":4}');
json_merge_preserve('{"a":1,"b":2}','{"a":3,"c":4}')
------------------------------------------------------
{"a": [1, 3], "b": 2, "c": 4}
2
3
4
5
6
7
8
9
10
11
# JSON 表函数
8.0 新增 JSON_TABLE (),将 JSON 格式的数据转换为关系表格式,返回的结果可以当做一个普通标,使用 SQL 进行查询。
SELECT * FROM json_table(
# 模拟数据,或某个表的数据
'[{"a":"1"},{"a":2},{"b":3},{"a":2},{"a":[1,2,3,4]}]',
# 指定json中的那元数据作为一个转换,这里可以通过数组下表匹配,*表示所有数据
"$[*]" COLUMNS(
# 指定关系表结构列的定义
# id列,生成一个数字序列
id FOR ordinality,
# 定义一个a字段,取json中a这个属性的值,当转换错无的时候显示 -1,当没有相应的属性显示为 -2,这里错误默认值一定不能是字符串
a VARCHAR(100) path "$.a" DEFAULT '-1' ON error DEFAULT '-2' ON empty,
# 定义a属性的JSON字段,为空则显示默认JSON
a_j json path "$.a" DEFAULT '{"a":333}' ON empty,
# 定义一个b字段,用于判断路径是否存在b这个属性
b INT EXISTS path "$.b"
)
) AS t;
id a a_j b
------ ------ ------------ --------
1 1 "1" 0
2 2 2 0
3 -2 {"a": 333} 1
4 2 2 0
5 -1 [1, 2, 3, 4] 0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24