 MySQL 高可用MGR(三) 测试
MySQL 高可用MGR(三) 测试
# 测试目的
根据 mysql 高可用方案并进行相关测试。方案如下:
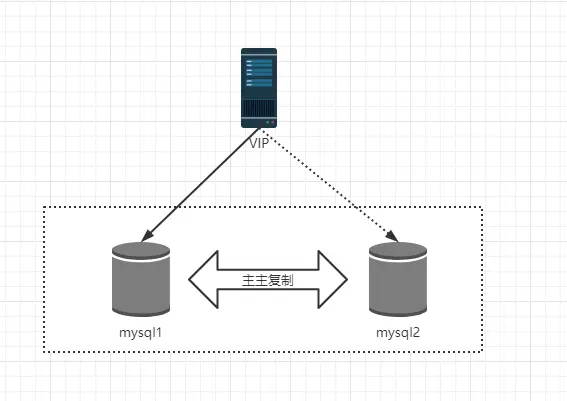
使用 keepalived 来做 MySQL1 和 MySQL2 的高可用技术方案,再 MySQL1 和 MySQL2 都需要部署 keepalived,然后虚拟一个 IP 即可。
# 测试环境
| ip | 描述 |
|---|---|
| 192.168.81.101 | mysql1 |
| 192.168.81.102 | mysql2 |
| 192.168.81.104 | VIP |
# 测试步骤
- mysql1 添加数据能否向 mysql2 在主主复制的情况下,达到数据同步。
2. mysql2 添加数据能否向 mysql1 在主主复制的情况下,达到数据同步。 - mysql1 挂起 mysql2 是否能立即顶上。
- mysql2 挂起,mysql1 添加数据,mysql2 启动是否能填补之前数据。
# 测试方案
针对测试步骤,本次测试将使用 SQLyog 工具 来作为客户端来进行测试,测试结果将为图文的方式。
# 测试结果
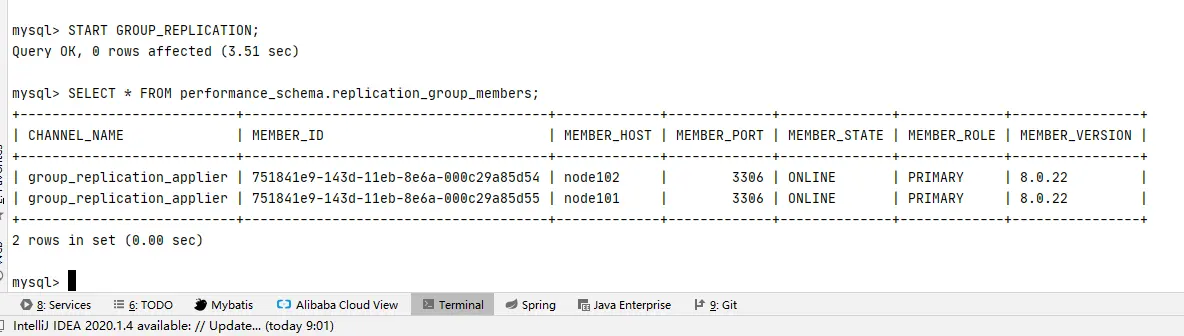
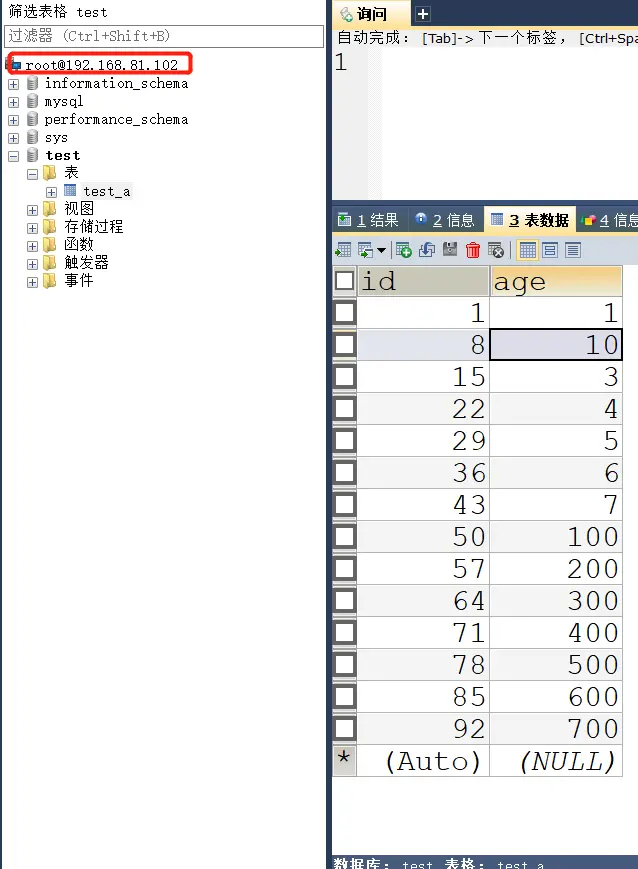
# 1、mysql1 添加数据能否向 mysql2 在主主复制的情况下,达到数据同步
先向 mysql1 创建一个 test 库,看 mysql2 能否同步,然后创建表查看能否同步,再进行数据插入,看能否同步。
# 库操作前


# 库操作后
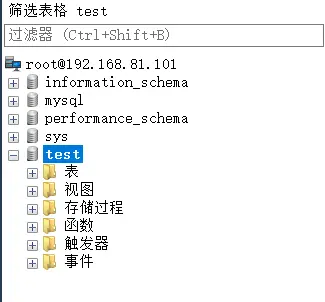
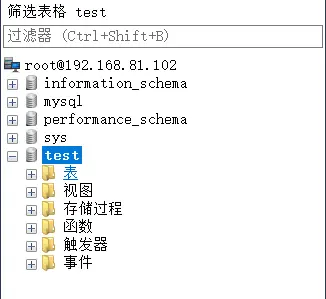
# 操作表
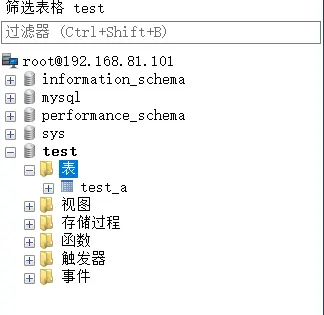
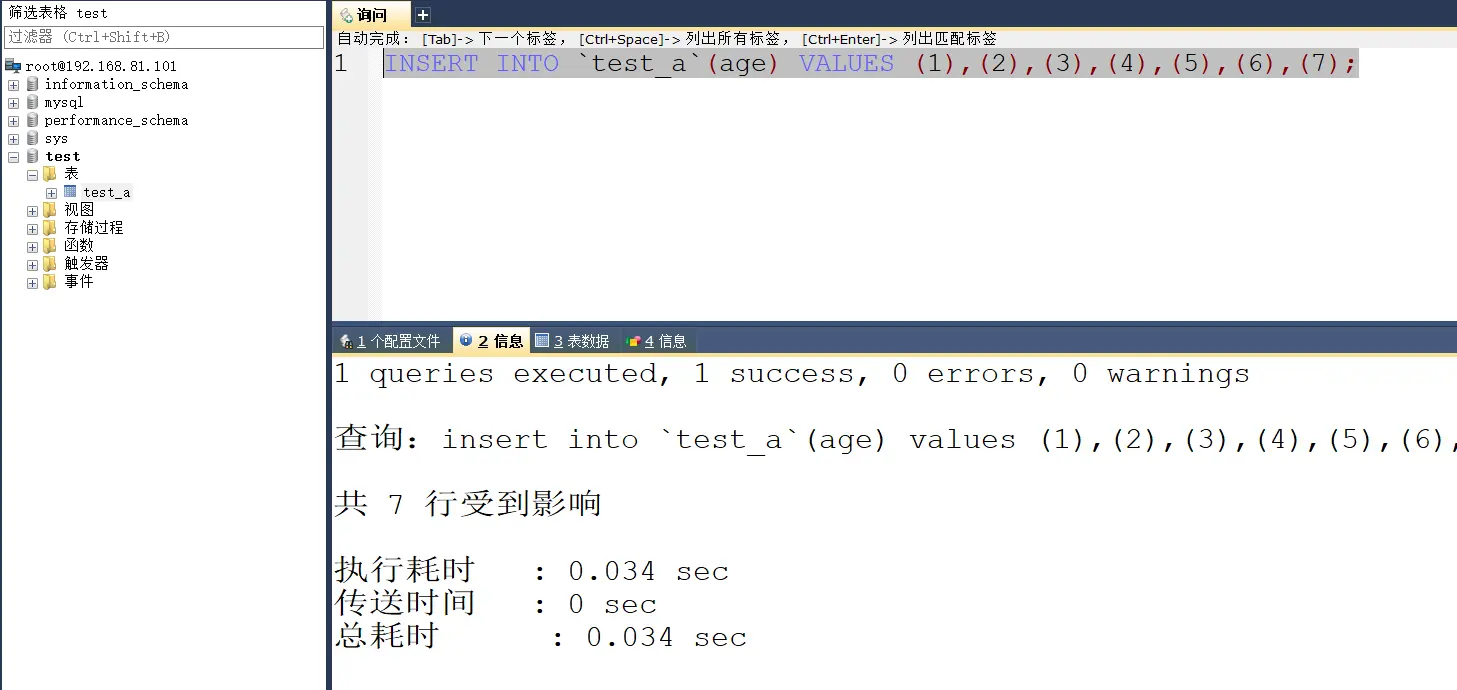
# 操作数据
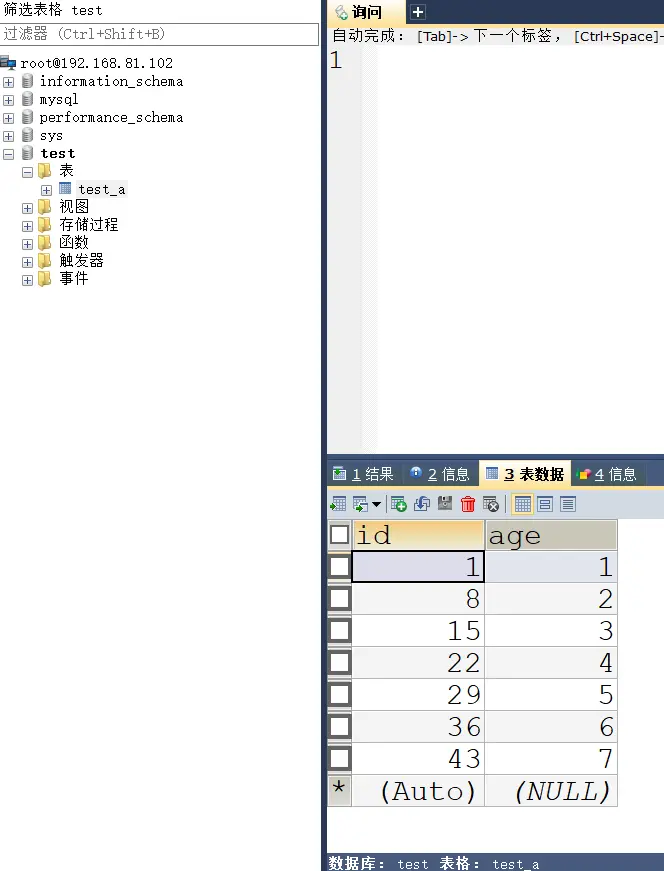
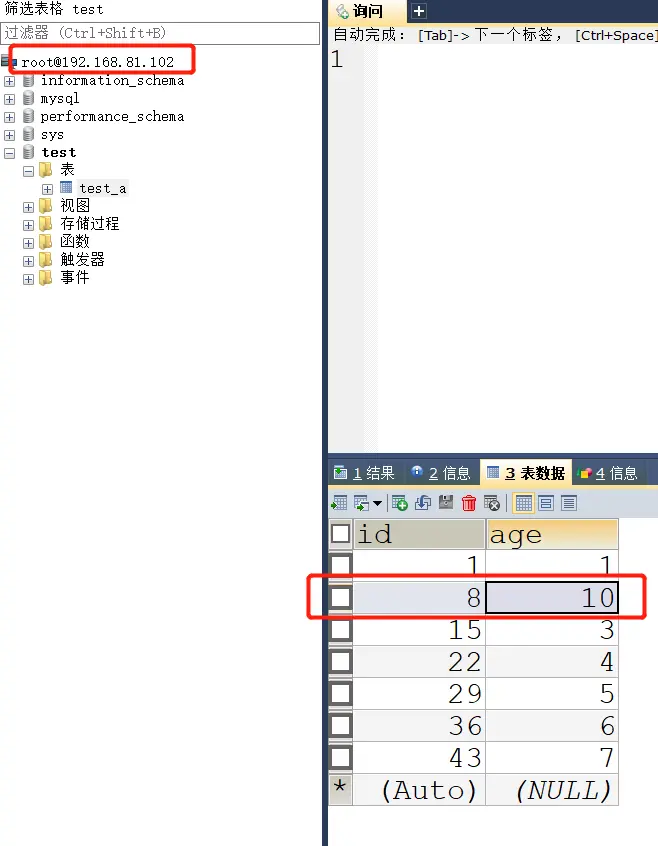
# 2、mysql2 添加数据能否向 mysql1 在主主复制的情况下,达到数据同步
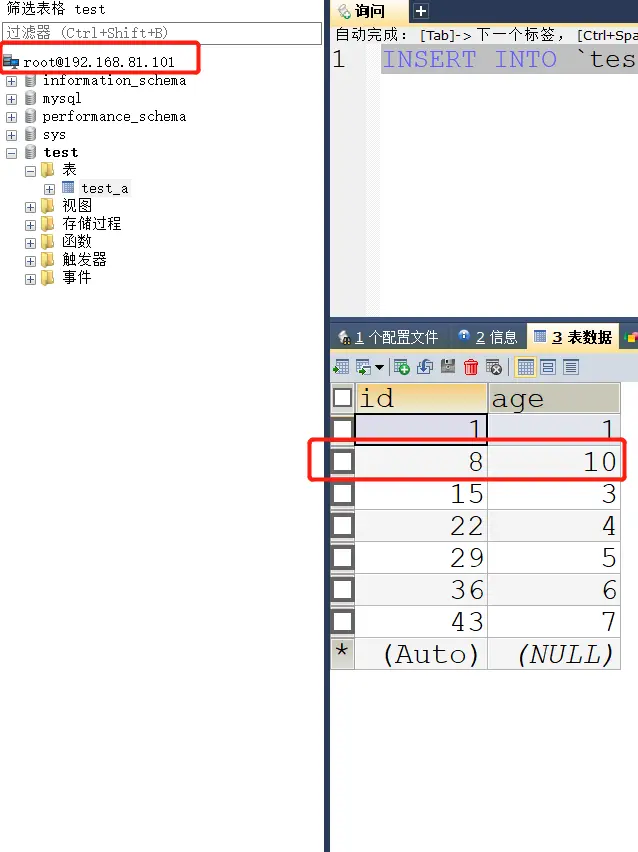
# 3、mysql1 挂起 mysql2 是否能立即顶上
通过连接虚拟 IP(VIP)104,然后停止 mysql1,看 104 是否依然能正常运行。
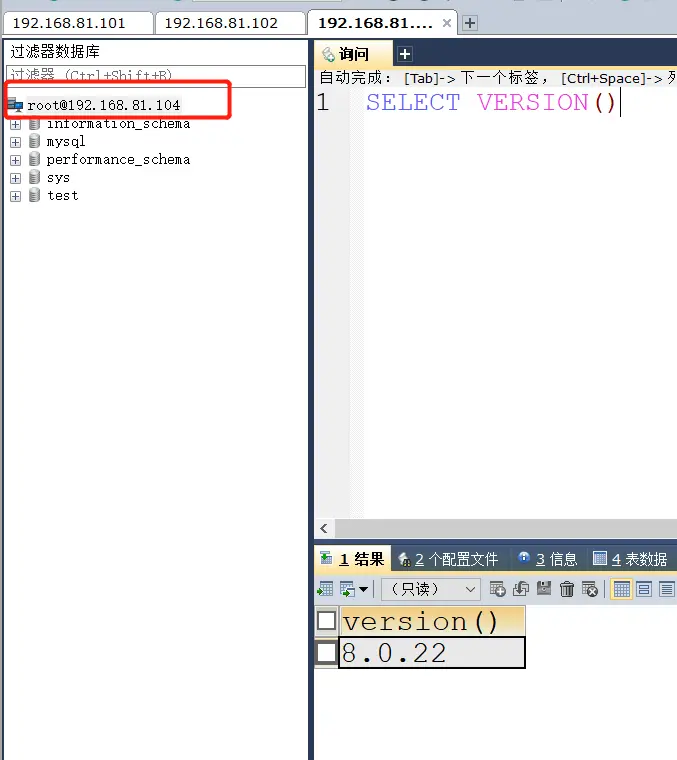

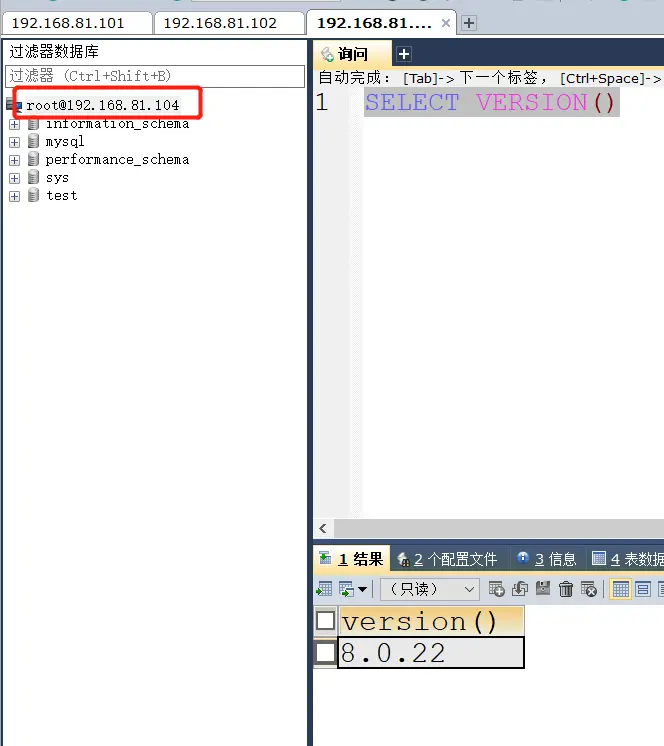
测试结果是依然额可以的。可以改为插入数据测试。
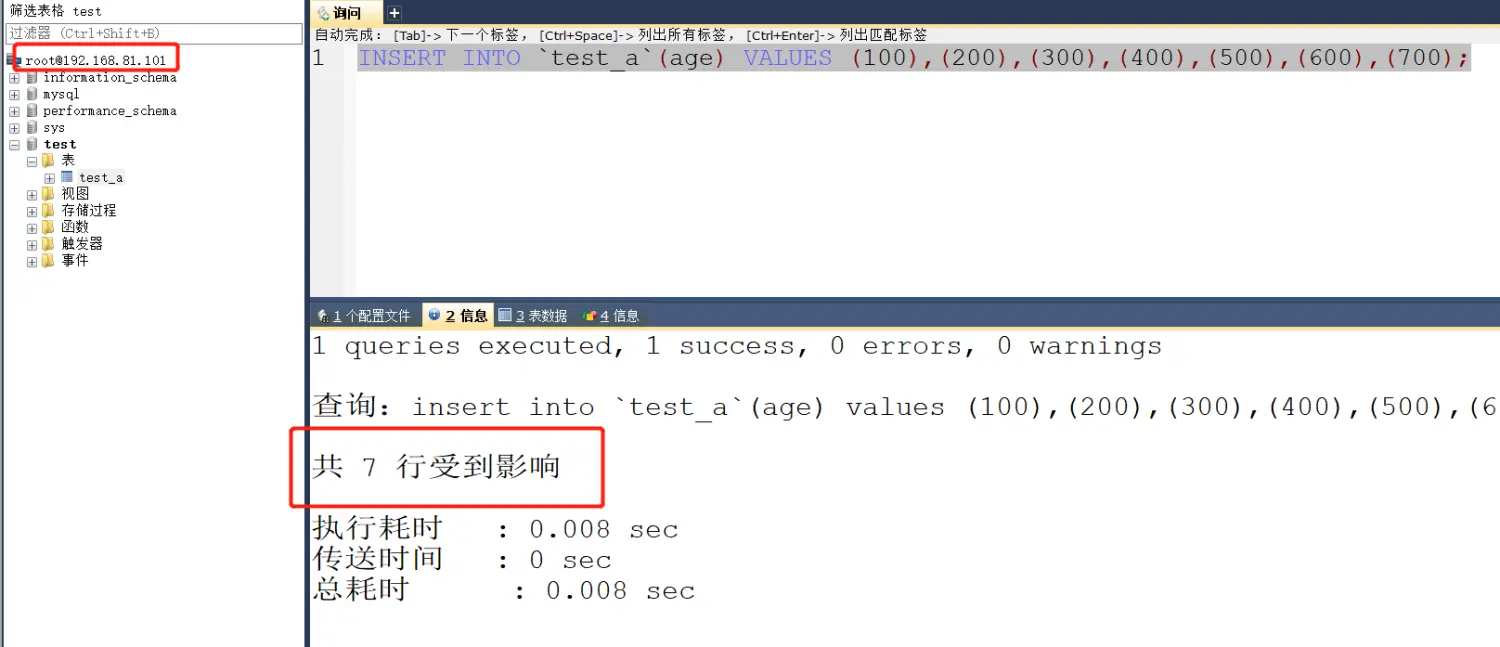
# 4、mysql2 挂起,mysql1 添加数据,mysql2 启动是否能填补之前数据。
关闭 mysql2,再 mysql1 插入数据,然后再启动 mysql2 看是否同步。


上次更新: 1/1/2026, 8:54:37 PM