Kafka-2.7.0 搭建及参数解析
Kafka-2.7.0 搭建及参数解析
# 搭建
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.0/kafka_2.13-2.7.0.tgz
tar -xzf kafka_2.13-2.7.0.tgz
cd kafka_2.13-2.7.0
2
3
4
下载的 kafka 自带有 ZooKeeper,但很快,ZooKeeper 将不再被 Apache Kafka 所需要。
# 文件介绍
kafka 安装好以后包含有以下文件
[root@localhost kafka_2.13-2.7.0]# ls
bin config libs LICENSE NOTICE site-docs
2
- bin 包含 kafka 的 topic 脚本、kafka 启动脚本、ZooKeeper 启动脚本、生产者脚本、消费者脚本等
- config 包含生产者配置、消费者配置、ZooKeeper 配置、kafka 配置以及一些 connect 配置
- libs 主要是一些 jar 文件
应用程序一般做为生产者和消费者,对于 kafka 服务配置只需要关心 ZooKeeper 和 kafka 本身配置即可,其余在应用本身可以控制
# 基础命令
创建 topic,--replication-factor 副本数量 ,--partitions 分区数量,副本数量最好小于集群数量
./kafka-topics.sh --create --zookeeper ip:2181 --replication-factor 1 --partitions 1 --topic topic_name
删除 topic
./kafka-topics.sh --delete --zookeeper ip:2181 --topic topic_name
查看所有的 topic
./kafka-topics.sh --list --zookeeper ip:2181
查看某一个 topic 的详情
./kafka-topics.sh --zookeeper ip:2181 --describe --topic topic_name
启动 producer
./kafka-console-producer.sh --broker-list ip:9092 --topic topic_name
启动 consumer,--from-beginning 从头开始消费,没有之前生产的数据会丢弃
./kafka-console-consumer.sh --bootstrap-server ip:9092 --topic topic_name --from-beginning
# 启动
启动 zookeeper
# 先修改配置
vim /config/zookeeper.properties
zookeeper.connect=192.168.81.62:2181
clientPortAddress=192.168.81.62
# 启动
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
2
3
4
5
6
7
配置 kafka,并启动,如果是集群模式的话,只需要改 broker.id 即可
# 先修改配置
vim /config/server.properties
# 集群模式下broker.id 必须唯一
broker.id=0
# 消息的存储位置(持久化位置)
log.dirs=/tmp/kafka-logs
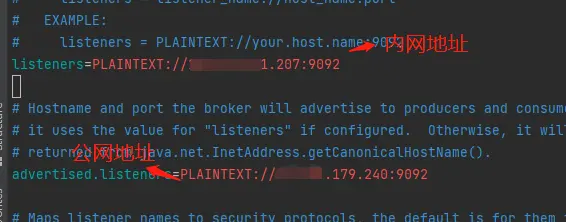
# 配置kafka允许被连接的ip和端口
listeners=PLAINTEXT://192.168.81.62:9092
# zookeeper连接 多台zookeeper ',' 逗号分割
zookeeper.connect=192.168.81.62:2181
# 启动
bin/kafka-server-start.sh -daemon config/server.properties
2
3
4
5
6
7
8
9
10
11
12
13
成功启动所有服务后,您将运行并可以使用基本的 Kafka 环境。
先关闭 kafka 再关闭 zookeeper,若先关闭了 zookeeper 导致 kafka 无法关闭,可以再启动 zookeeper 后关闭 kafka。
# kafka web UI
官方文档 (opens new window),我下载到了 window 本机,并没有在 linux 上操作,首先该 UI 要求有 java8 的环境配置中,然后把下载解压的文件也配置到环境变量中,否则会启动报错,而且变量必须叫 KE_HOME。
然后修改 D:\tools\kafka-eagle-web-2.0.4\conf\system-config.properties,复制以下配置到你的文件中就好了,很多的配置使用不到的,只需要修改 数据库连接 和 cluster1.zk.list 地址就好
######################################
# multi zookeeper & kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=192.168.81.62:2181
######################################
# zookeeper enable acl
######################################
cluster1.zk.acl.enable=false
######################################
# broker size online list
######################################
cluster1.kafka.eagle.broker.size=20
######################################
# zk client thread limit
######################################
kafka.zk.limit.size=32
######################################
# kafka eagle webui port
######################################
kafka.eagle.webui.port=8048
######################################
# kafka jmx acl and ssl authenticate
######################################
cluster1.kafka.eagle.jmx.acl=false
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
#cluster2.kafka.eagle.offset.storage=zk
######################################
# kafka jmx uri
######################################
#cluster1.kafka.eagle.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
######################################
# kafka metrics, 15 days by default
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.metrics.retain=15
######################################
# kafka sql topic records max
######################################
kafka.eagle.sql.topic.records.max=5000
######################################
# delete kafka topic token
######################################
kafka.eagle.topic.token=keadmin
######################################
# kafka mysql jdbc driver address
######################################
kafka.eagle.driver=com.mysql.cj.jdbc.Driver
kafka.eagle.url=jdbc:mysql://192.168.81.61:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=Admin@123
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
启动 D:\tools\kafka-eagle-web-2.0.4\bin\ke.bat
看到 tomcat 打印,需要多等待一些时间,如果等待太久可以先关闭 kafka 服务。
2021-02-20 16:44:06 INFO [ZooKeeper.Thread-236] - Initiating client connection, connectString=192.168.81.62:2181 sessionTimeout=30000 watcher=kafka.zookeeper.ZooKeeperClient$ZooKeeperClientWatcher$@7bac5016
2021-02-20 16:44:06 INFO [ZooKeeperClient.Thread-236] - [ZooKeeperClient] Waiting until connected.
2
常见的 web ui,安装方式:https://cloud.tencent.com/developer/article/1667262 下载地址:https://github.com/wolfogre/kafka-manager-docker/releases
# 参数解析
每个 broker 的唯一非负整数 id 的标识。
broker.id=0
kafka 存放数据的路径,路径并不是只可以写一个,可以写多个用逗号分割,
log.dirs=/tmp/kafka-logs
zookeeper 的连接
zookeeper.connect=host:port,host:port
topic 的默认分区数量,一般消费者的数量尽量和分区数保持一致 1:1,否则会造成多个 消费者消费一个分区,或者分区过大,消费者消费不即时 (1 条 1 条消费)
num.partitions=1
topic 分区里每个 log 文件的最大值
log.segment.bytes=1024*1024*1024
即使以上参数没有达到文件的最大值,当创建时间达(24*7 = 一周)到此属性值,就会创建文件。
log.roll.hours=24*7
每个 log index 的最大尺寸。如果 log index 尺寸达到这个数值,即使尺寸没有超过 log.segment.bytes 限制,也需要产生新得 log index
log.index.size.max.bytes
如果一个 follower 在这个时间内没有发送 fetch 请求,leader 将从 ISR 中移除这个 follower
replica.lag.time.max.ms=10000
备份时每次 fetch 的最大值
replica.lag.fetch.max.bytes=1024*1024
指明了是否能够使不在 ISR 中 replicas 设置用来做为 leader
unclean.leader.election.enable=true
是否能够删除 topic
delete.topic.enable=false
生产者设置 kafka 集群
boostrap.servers=host:port,host:port
生产者 ack 消息确定机制
acks=1
生产者批量发送消息 (以 16384 字节数为一批),此参数调整须是 1024 整数倍
batch.size=16384
生产者发送消息的间隔,0 代表有数据立马发送,如果要使用批处理,该值建议调在 1s 以内,根据实际数据量的大小计算。
linger.ms=0
# 阿里云中部署注意事项
阿里云中的端口开放需要如下方式,使用 iptables 根本无效
firewall-cmd --zone=public --add-port=2181/tcp --permanent
firewall-cmd --zone=public --add-port=9092/tcp --permanent
firewall-cmd --zone=public --add-port=3306/tcp --permanent
2
3
配置 IP 需要注意,zookeeper 可以直接走内网,加到 zookeeper 链接超时时间