 Hive 介绍及安装
Hive 介绍及安装
本文及后续所有文章都以 3.1.2 做为版本讲解和入门学习
# hive 简介
Hive 是一个数据仓库基础工具在 Hadoop 中用来处理结构化数据。它架构在 Hadoop 之上,总归为大数据,并使得查询和分析方便。它提供了一系列的工具,可以用来进行数据提取、转化、加载(ETL),这是一种可以存储、查询和分析存储再 hadoop 中的大规模数据的机制。hive 定义了简单的类 SQL 查询语言,称为 HiveQL,它允许熟悉 sql 的用户查询数据,可以将 sql 语句转换为 MapReduce 任务进行运行。
Hive 构建在基于静态(离线)批处理的 Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百 MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守 Hadoop MapReduce 的作业执行模型,Hive 将用户的 HiveQL 语句通过解释器转换为 MapReduce 作业提交到 Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的离线批处理作业,例如,网络日志分析,统计分析。
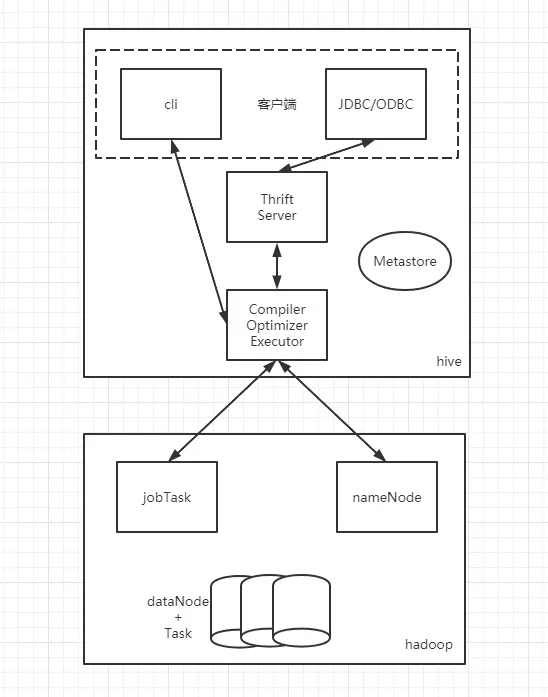
# 用户接口主要又三个:CLI、JDBC、WUI
- CLI 最长用的模式。实际上在 > hive 命令行下操作时,就是利用 CLI 用户接口。
- JDBC,通过 java 代码操作,需要启动 hiveserver,然后连接操作。
- webui 控制 hive
# Metastore
hive 将元素数据存储在数据库中,如 mysql、derby。hive 中的元数据包括表的名字,表的列喝分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
# 解释器(Complier)、优化器(optimizer)、执行器(executor)组件
这三个组件用于:HQL 语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 掉用执行。
# hadoop
hive 的数据存储在 HDFS 中,大部分的查询、计算由 MapReduce 完成。
# Hive 工作机制
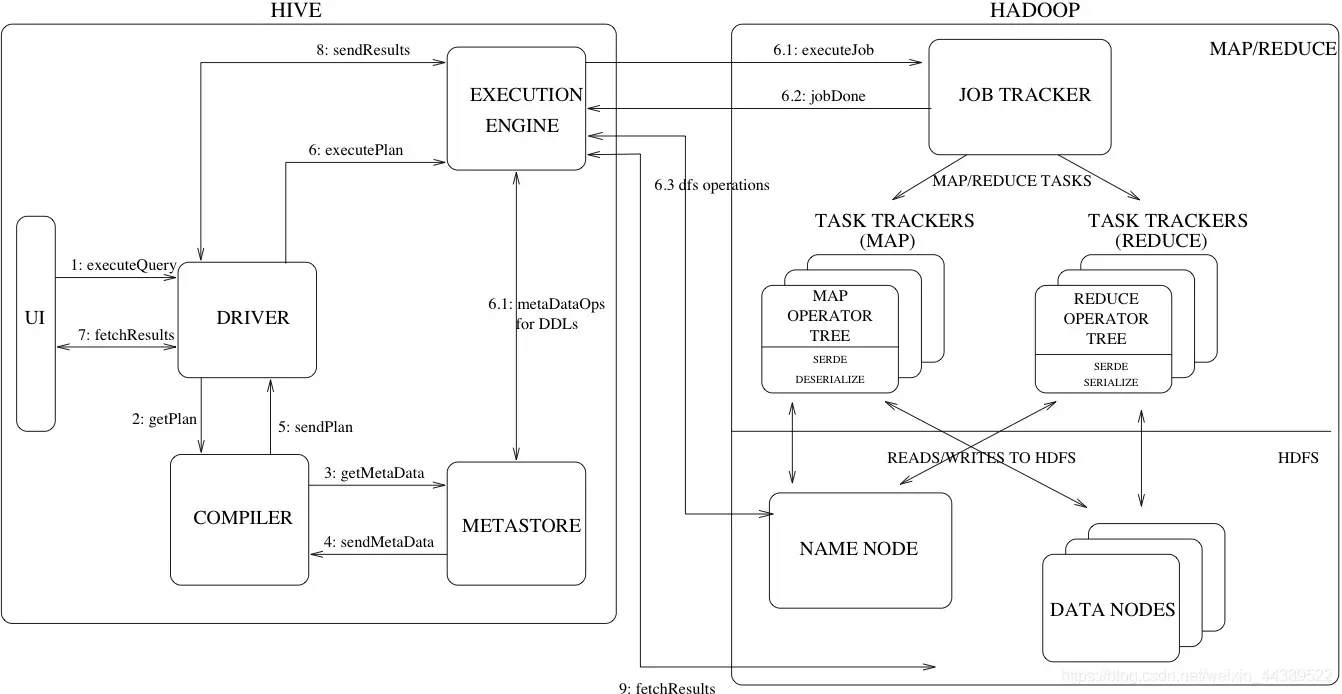
1.Execute Query:用户将 HQL 语句发送到 driver 来执行。
2.Get Plan:Driver 根据查询编译器解析 query 语句,验证 query 语句的语法,查询计划或者查询条件。
3.Get Metadata:编译器将元数据请求发送给 Metastore (数据库)。
4.Send Metadata:Metastore 将元数据作为响应发送给编译器。
5.Send Plan:编译器检查要求和重新发送 Driver 的计划。到这里,查询的解析和编译完成。
6.Execute Plan:Driver 将执行计划发送到执行引擎。
- 6.1)Execute Job:hadoop 内部执行的是 mapreduce 工作过程,任务执行引擎发送一个任务到资源管理节点 (resourcemanager),资源管理器分配该任务到任务节点,由任务节点上开始执行 mapreduce 任务。
- 6.2)Metadata Ops:在执行引擎发送任务的同时,对 hive 的元数据进行相应操作。
7.Fetch Result:执行引擎接收数据节点 (data node) 的结果。
8.Send Results:执行引擎发送这些合成值到 Driver。
9.Send Results:Driver 将结果发送到 hive 接口。
# 安装
该版本对应 hadoop 3.x
wget https://mirrors.bfsu.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
启动
[root@node113 bin]# pwd
/opt/software/hive-3.1.2/bin
[root@node113 bin]# ./hive
2
3
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
解决报错:
hadoop 和 hive 的两个 guava.jar 版本不一致。
两个位置分别位于下面两个目录:
/usr/local/hive/lib/
/usr/local/hadoop/share/hadoop/common/lib/
2
删除低版本的那个,将高版本的复制到低版本目录下,注意名字还是要以前的名字。
初始化数据库,使用的是 hive 自带的 derby 数据库,可以改成 mysql 等
[root@node113 bin]# pwd
/opt/software/hive-3.1.2/bin
[root@node113 bin]# rm -rf metastore_db
[root@node113 bin]# ./schematool -initSchema -dbType derby
2
3
4
初始化成功,执行
./hive
启动成功执行如下
hive> show databases;
OK
default
Time taken: 0.637 seconds, Fetched: 1 row(s)clear
2
3
4