 Hbase LSM-TREE
Hbase LSM-TREE
本文及后续所有文章都以 2.4.2 做为版本讲解和入门学习
LSM-Tree 全称是 Log Structured Merge Tree(日志合并树),是一种分层,有序,面向磁盘的数据结构,其核心思想是充分了利用了,磁盘批量的顺序写要远比随机写性能高出很多,围绕这一原理进行设计和优化,以此让写性能达到最优,正如我们普通的 Log 的写入方式,这种结构的写入,全部都是以 Append 的模式追加,不存在删除和修改。当然有得就有舍,这种结构虽然大大提升了数据的写入能力,却是以牺牲部分读取性能为代价,故此这种结构通常适合于写多读少的场景。故 LSM 被设计来提供比传统的 B + 树或者 ISAM 更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标。这里面最典型的例子就属于 Kakfa 了,把磁盘顺序写发挥到了极致,故而在大数据领域成为了互联网公司标配的分布式消息中间件组件。
虽然这种结构的写非常简单高效,但其缺点是对读取,特别是随机读很不友好,这也是为什么日志通常用在下面的两种简单的场景:
- 数据是被整体访问的,大多数数据库的 WAL(write ahead log)也称预写 log,包括 mysql 的 Binlog 等
- 数据是通过文件的偏移量 offset 访问的,比如 Kafka。
想要支持更复杂和高效的读取,比如按 key 查询和按 range 查询,就得需要做一步的设计,这也是 LSM-Tree 结构,除了利用磁盘顺序写之外,还划分了内存 + 磁盘多层的合并结构的原因,正是基于这种结构再加上不同的优化实现,才造就了在这之上的各种独具特点的 NoSQL 数据库,如 Hbase,Cassandra,Leveldb,RocksDB,MongoDB,TiDB 等。
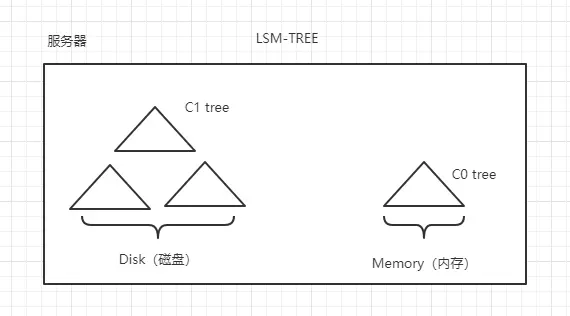
C0 Tree 和 C1 Tree 可能是某种结构树,如:二叉树,B-tree,B+tree,red-black tree,skipList。
LSM-TREE 最核心的思想是:做延迟的归并排序,会先把数据写入到日志里以追加的方式,然后写到内存中,并以 tree 的结构管理,当写入的数据在内存中达到一定的阀值,在以顺序方式映射到磁盘中,这种方式在磁盘中会有很多的小子树,每个树都会有自己的索引位置。当查询的时候会便利所有的小子树的索引文件,这种方式并没有一个整树读取的快,所以 LSM-TREE 牺牲了部分的读性能,换取更高的写性能(因为不需要在对以前的数据进行排序,只对内存的排序)。
当达子树达到一定量的时候可以进行合并,减少读性能的丢失。
C0 树不一定要具有一个类 B - 树的结构。Hbase 中采用了线程安全的 ConcurrentSkipListMap 数据结构。
Hbase 底层会为 Hbase 的 row-key 建立索引,索引在通过行键查询时,速度很快,在实际的应用场景中,一般也是按行键来查询。但是目前 Hbase 的短板在于没有为列建立索引机制。所以很多企业解决办法:通过 ES(全文检索引擎)为 Hbase 建立索引。这种模式称为 Hbase 的二级索引。