 Hadoop YARN
Hadoop YARN
# YARN 概述
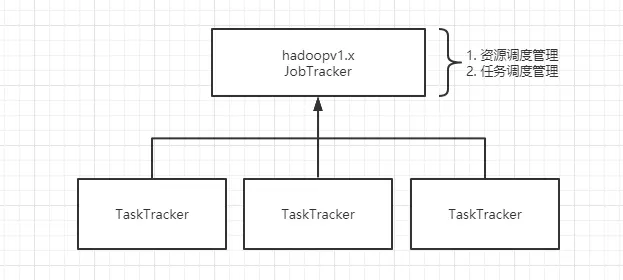
hadoop 1.x 中,一个 Job 任务使由 JobTracker 来分配资源和管理任务调度,虽说最终运行是在 TaskTracker,但对于 JobTracker 来说,当大量的 Job 任务要分配,JobTracker 也会面临忙不过来或受限的处境。
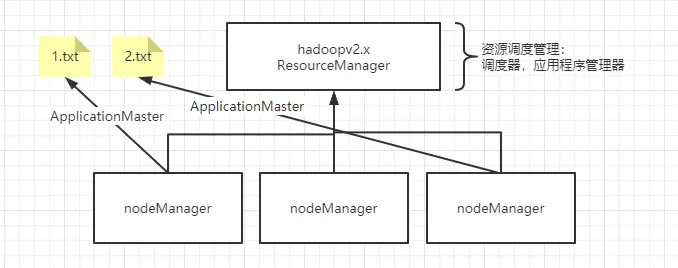
hadoop 2.x 中,改变了 JobTracker 的工作机制只负责资源的调度,这样的设计方式减了 JobTracker 的工作负载,从而可以更专注的处理资源分配和调度的工作,所以被称为 ResorceManager。ResorceManager 含有两个组件,一个是调度器(Scheduler),一个是应用程序管理器(Applications Manager,ASM)。
# YARN 工作机制
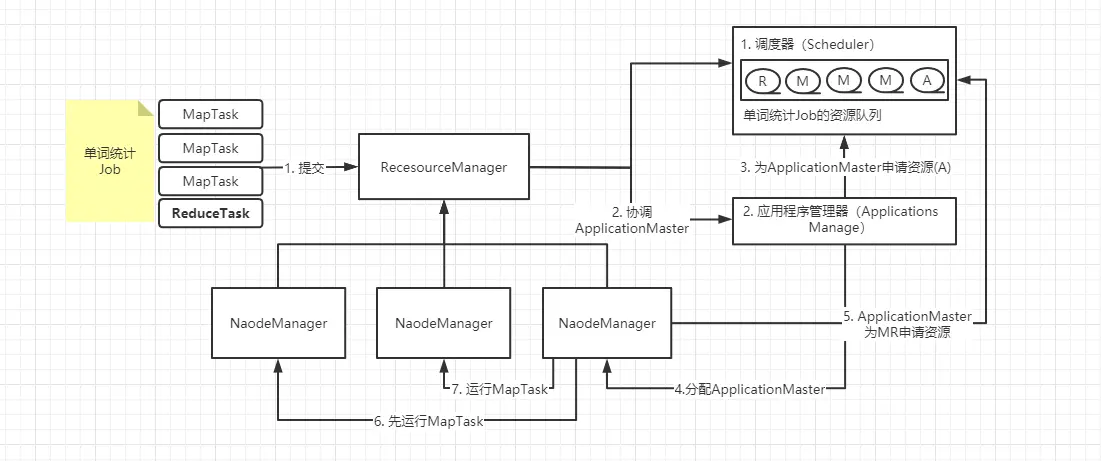
# Resourcemanager
ResourceManager 拥有系统所有资源分配的决定权,负责集群中所有应用程序的资源分配,拥有集群主要资源、全局视图。因此为用户提供公平的,基于容量的,本地化资源调度。根据程序的需求,调度优先级以及可用资源情况,动态分配特定节点运行应用程序。它与每个节点上的 NodeManager 和每一个应用程序的 ApplicationMaster 协调工作。
ResourceManager 的主要职责在于调度,即在竞争的应用程序之间分配系统中的可用资源,并不关注每个应用程序的状态管理。
ResourceManager 主要有两个组件:Scheduler 和 ApplicationManager:Scheduler 是一个资源调度器,它主要负责协调集群中各个应用的资源分配,保障整个集群的运行效率。Scheduler 的角色是一个纯调度器,它只负责调度 Containers,不会关心应用程序监控及其运行状态等信息。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。
# Scheduler
Scheduler 是一个可插拔的插件,负责各个运行中的应用的资源分配,受到资源容量,队列以及其他因素的影响。是一个纯粹的调度器,不负责应用程序的监控和状态追踪,不保证应用程序的失败或者硬件失败的情况对 task 重启,而是基于应用程序的资源需求执行其调度功能,使用了叫做资源 container 的概念,其中包括多种资源,比如,cpu,内存,磁盘,网络等。在 Hadoop 的 MapReduce 框架中主要有三种 Scheduler:FIFO Scheduler,Capacity Scheduler 和 Fair Scheduler。默认 Capacity Scheduler
FIFO Scheduler:先进先出,不考虑作业优先级和范围,适合低负载集群。
Capacity Scheduler:将资源分为多个队列,允许共享集群,有保证每个队列最小资源的使用。
Fair Scheduler:公平的将资源分给应用的方式,使得所有应用在平均情况下随着时间得到相同的资源份额。
# ApplicationManager
ApplicationManager 主要负责接收 job 的提交请求,为应用分配第一个 Container 来运行 ApplicationMaster,还有就是负责监控 ApplicationMaster,在遇到失败时重启 ApplicationMaster 运行的 Container
# NodeManager
NodeManager 是 yarn 节点的一个 “工作进程” 代理,管理 hadoop 集群中独立的计算节点,主要负责与 ResourceManager 通信,负责启动和管理应用程序的 container 的生命周期,监控它们的资源使用情况(cpu 和内存),跟踪节点的监控状态,管理日志等。并报告给 RM。
NodeManager 在启动时,NodeManager 向 ResourceManager 注册,然后发送心跳包来等待 ResourceManager 的指令,主要目的是管理 resourcemanager 分配给它的应用程序 container。NodeManager 只负责管理自身的 Container,它并不知道运行在它上面应用的信息。在运行期,通过 NodeManager 和 ResourceManager 协同工作,这些信息会不断被更新并保障整个集群发挥出最佳状态
主要职责:
1、接收 ResourceManager 的请求,分配 Container 给应用的某个任务
2、和 ResourceManager 交换信息以确保整个集群平稳运行。ResourceManager 就是通过收集每个 NodeManager 的报告信息来追踪整个集群健康状态的,而 NodeManager 负责监控自身的健康状态。
3、管理每个 Container 的生命周期
4、管理每个节点上的日志
5、执行 Yarn 上面应用的一些额外的服务,比如 MapReduce 的 shuffle 过程
# Container
Container 是 Yarn 框架的计算单元,是具体执行应用 task(如 map task、reduce task)的基本单位。Container 和集群节点的关系是:一个节点会运行多个 Container,但一个 Container 不会跨节点。
一个 Container 就是一组分配的系统资源,现阶段只包含两种系统资源(之后可能会增加磁盘、网络、GPU 等资源),由 NodeManager 监控,Resourcemanager 调度。
每一个应用程序从 ApplicationMaster 开始,它本身就是一个 container(第 0 个),一旦启动,ApplicationMaster 就会追加任务需求与 Resourcemanager 协商更多的 container,在运行过程中,可以动态释放和申请 container。
# ApplicationMaster
ApplicationMaster 负责与 scheduler 协商合适的 container,跟踪应用程序的状态,以及监控它们的进度,ApplicationMaster 是协调集群中应用程序执行的进程。每个应用程序都有自己的 ApplicationMaster,负责与 ResourceManager 协商资源(container)和 NodeManager 协同工作来执行和监控任务 。
当一个 ApplicationMaster 启动后,会周期性的向 resourcemanager 发送心跳报告来确认其健康和所需的资源情况,在建好的需求模型中,ApplicationMaster 在发往 resourcemanager 中的心跳信息中封装偏好和限制,在随后的心跳中,ApplicationMaster 会对收到集群中特定节点上绑定了一定的资源的 container 的租约,根据 Resourcemanager 发来的 container,ApplicationMaster 可以更新它的执行计划以适应资源不足或者过剩,container 可以动态的分配和释放资源。
# Hadoop2.x job 运行机制
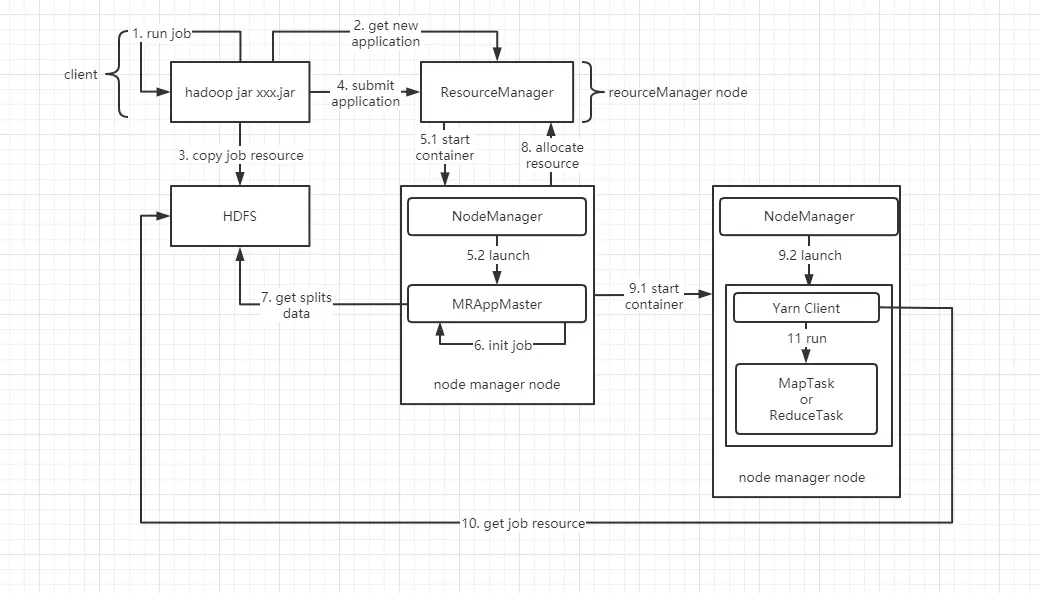
和 Hadoop1.x 不同的是多了 YARN 的工作机制,会为 job 的每个步骤(ApplicationMaster、MapTask、ReduceTask)都会申请一个 container 去工作。
# yarn-site.xml 相关配置
每台 nodemanager 服务器贡献的内存,默认 8192M。
yarn.nodemanager.resource.memory-mb=8192
每台 nodemanager 服务器贡献的 CPU 数量,默认 8 核
yarn.nodemanager.resource.cpu-vcores=8
每个 Container 最小的使用内存,默认 1024M
yarn.scheduler.minimum.allocation-mb=1024
每个 Container 最大的使用内存,默认 8192M
yarn.scheduler.maximum.allocation-mb=8192
每个 Container 最少使用 CPU,默认 1
yarn.scheduler.minimum.allocation-vcores=1
每个 Container 最大使用 CPU,默认 4
yarn.scheduler.maximum.allocation-vcores=4
每个 MapTask 运行所用的内存大小。此参数如果在 Container 的上限和下限之间,就用设置的参数值,如果超过上限或下限,就是用上限或下限做值。默认 1024M
maperduce.map.memory.mb=1024
每个 ReduceTask 运行所用的内存大小。此参数如果在 Container 的上限和下限之间,就用设置的参数值,如果超过上限或下限,就是用上限或下限做值。默认 1024M
maperduce.resuce.memory.mb=1024
配置 Yarn 的调度器类型,默认容器调度器,还有另外两种调度器:FIFO 调度器,Fair 调度器
yarn.resourcemanager.scheduler.class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
# uber JVM 重用
yarn 的默认配置会禁用 uber ,即不允许 JVM 重用。在以上 yarn 的工作机制中,当每一个 task 执行完毕后,container 便会被 nodemamager 收回,而 container 所拥有的 JVM 也相应地被退出。
开启 uber 即在同一个 container 里面一次执行多个 task,在 yarn-site.xml 文件中,改变以下几个参数的配置,即可启用 uber 的方法。
<!-- 开启uber模式(针对小作业的优化) -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 配置启动uber模式的最大map数-->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- 配置启动uber模式的最大reduce数-->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17