 Hadoop MapReduce机制
Hadoop MapReduce机制
# MapReduce 简介
MapReduce 分布式并行计算框架是一种可用于数据处理的编程模型,可运行由个中语言编写的 MapReduce 程序:java、Ruby、Python、R、C++ 等语言。它用于处理超大规模数据的计算,同时具有可并行计算的特性,因此可以将大规模的数据分析任务交给任何一个拥有足够多机器的集群。并采用函数式编程的思想,在各函数之间串行计算(Map 执行完毕,才会开始执行 Reduce 任务)。
# hadoop1.x job 运行机制
在讲 YARN 后会说 hadoop2.0 job 运行机制
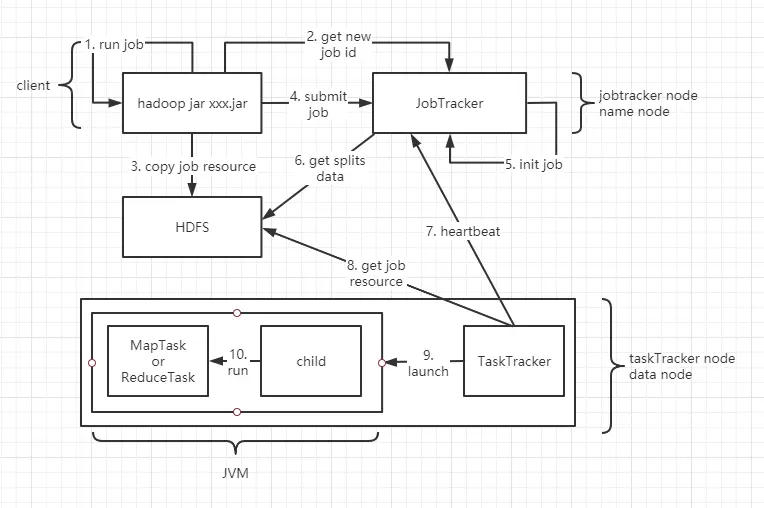
- run job 由客户端来完成,底层有一个 JobClient 类来做具体实现。run job 会做如下几件事
- 做 job 环境信息的收集,比如各个组件类,输出 KV 类型,检测是否合法。
- 检测输入路径的合法性,以及输出结果路径的合法性。
如果检测未通过,直接报错返回,不会做后续的 job 提交动作。
- run job 检测通过,JobClient 会向 JobTracker 为当前 job 申请 jobid,jobid 是全局唯一的,用于标识一个 Job。
- copy job resource 阶段,JobClient 把 Job 的运算资源上传到 HDFS。路径为 /tmp/hadoop-yarn/staging/ 用户 /* 。运算资源包括如下:
- jar 包
- 文件的切片信息
- job.xml 整个 job 的环境参数
- 当 jobClient 将运算资源上传到 HDFS 之后,提交 job(submit job)
5.6. 初始化 job 环境信息(init job)以及获取 job 的切片数量(get split data)目的是获取整个 Job 的 MapTask 任务数量和 ReduceTask 的任务数量。MapTask 任务数量 = 切片数量。ReduceTask 的任务数量在代码设置。 - TaskTracker 会根据心跳去 JobTracker 获取 job 任务。TaskTracker 在领取任务时,要满足数据本地话策略(TaskTracker 属于 datanode,datanode 存的是 块数据,JobTracker 属于 namenode,拥有块的切片信息,TaskTracker 去领取任务的时候最好领取块相对应的切片信息,可以节省带宽,否则还要去其他 datanode 找属于自己的切片信息)。切块包含的是数据(文件的真是数据),切片包含的是块的描述信息,如:
- Path 文件所在分布式文件系统路径
- Start 数据开始位置
- Length 数据的长度
- TaskTracker 去 HDFS 下载 job(xxx.jar) 的运算资源
9.10. 启动 JVM 进程
# 输入输出机制
以下是写一个 单词统计的 job 的输入和输出
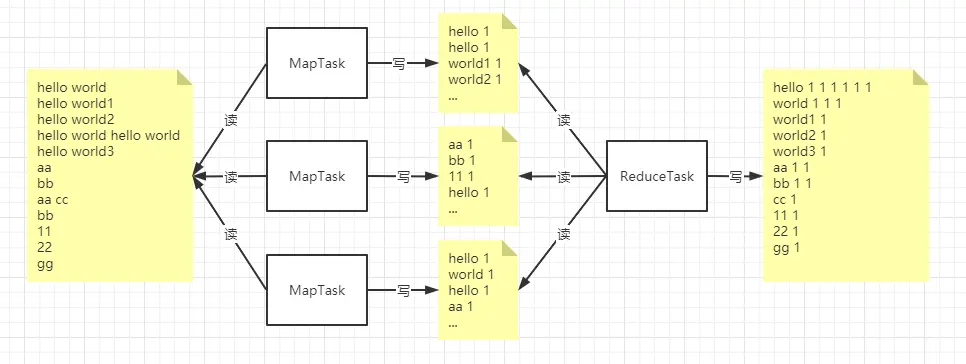
- MapTask 读取文件根据代码逻辑进行输出
- ReduceTask 读取 MapTask 的输出做为输入,会得到 一个迭代器,迭代器包含了相同单词的 value(最后图中的 hello 1 1 1 1 1 1),迭代器中包含 6 个元素,每个元素的值都是 1.
# 分区机制
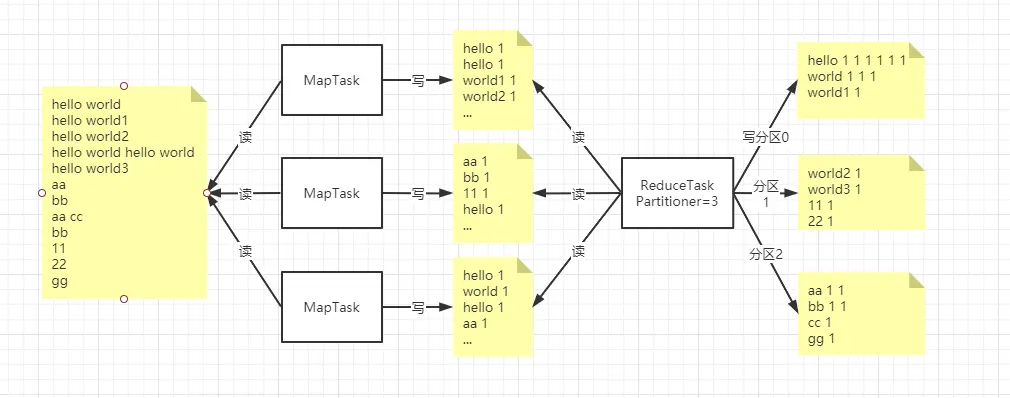
分区需要在代码中设置分几个区,并且可以控制分区条件
# 合并组件 (Combiner 机制)
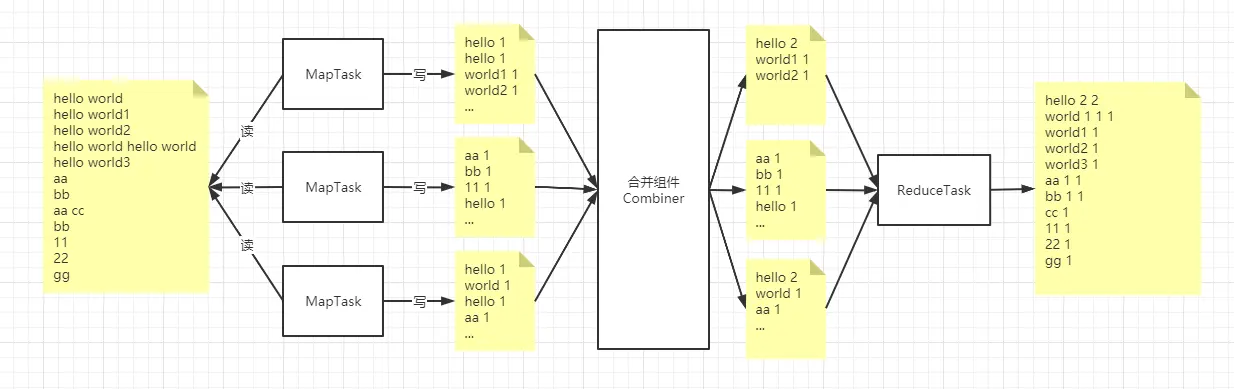
我们可以看到 合并组件 提前把 MapTask 的的输出做为输入合并后再输出,引入 Combiner 的作用就是为了降低 ReduceTask 的负载。
# MapTask 工作机制
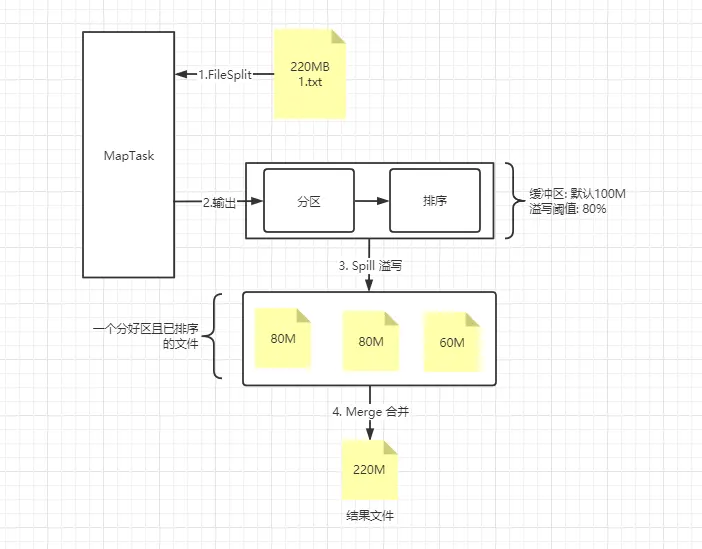
# 注意
- Spill 过程不一定会发生,当 MapTask 输出的数据流 < 溢写缓冲大小 * 溢写阈值
- 当发生了 Spill 过程,最后溢写缓冲区残留的数据会 flush 到最后生成的 Spill 文件中
- Spill 理论上是 80MB,但是需要考虑序列化的因素
- 不能凭一个 MapTask 处理的切片数据大小,来衡量输出数据的大小,这得取决于业务。
- 有一个 MapTask,就会有一个对应的溢写缓冲区
- 溢写缓冲区本质上就是一个字节数组,即内存中一块连续的地址空间
- 溢写缓冲区又叫环写(环形)缓冲区,可以重复利用同一块地址空间。
- Spill 因为是环形缓冲区,设置 80% 的写入,是为了不去阻塞后续的写入。
- Merge 过程不一定发生,原因是没有发送 Spill 或 发生 Spill 但只输出一个文件。
# 优化
- 适当调整 溢写缓冲 区大小,建议范围 250M~350M
- 加入 Combine(合并组件),会在缓冲区和 Merge 过程进行合并,减少 Spill 溢写次数,减少 IO 次数,减少网络数据传输。Merge 过程 Combine 不一定发生,当 Spill 文件 < 3
- 对最后的结果文件进行压缩
# ReduceTask 工作机制
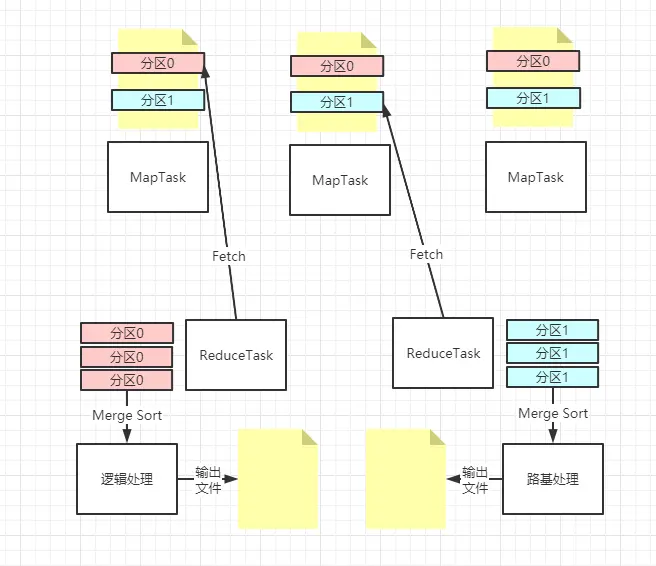
ReduceTask 会把 MapTask 输出的文件按分区读取再合并排序,该分区和 ReduceTask 的分区是两回事,MapTask 是对文件内容分区,ReduceTask 是对输出结果到不同的文件分区。
ReduceTask 在合并过程中,如果有大量的分区文件,按照一定的数量(可设置)合并,直到合并到少量文件到 ReduceTask 工作。
# 优化
- Fetch 线程数可调整,默认是 5 个。
- ReduceTask 启动阈值 5%,ReduceTask 不是等所有的 MapTask 完成才工作,而是根据 5% 的比例。
# Hadoop 常见参数调优
# hdfs-site.xml
namenode 是否允许被格式化,默认为 true,生产系统要设置 false,组织任何格式化操作再一个运行的 DFS 上。格式指令:hadoop namenode -format
dfs.namenode.support.allow.format=true
datamode 的心跳间隔,默认 3 秒,在集群网络状态不好的情况下,建议调大
dfs.heartbeat.interval=3
切块大小,默认是 128MB,必须得是 1024(page size)的整数倍。
dfs.blocksize=134217728
edits 和 fsimage 文件合并周期阈值,默认 1 小时
dfs.namenode.checkpoint.period=3600
文件流缓存大小。需要是硬件 page 大小的整数倍。在读写操作时,数据缓存大小,必须是 1024 整数倍
dfs.stream-buffer-size=4096
# maperd-site.xml
任务内部排序缓冲区大小,默认时 100MB,调大能减少 Spill 溢写次数,减少磁盘 IO,建议 250~400MB
mapreduce.task.io.sort.mb=100
Map 阶段溢写文件的阈值。不建议修改此值
mapreduce.map.sort.spill.percent=0.8
ReduceTask 启动的并发 copy 数据的线程数,建议尽可能等于或接近 Map 任务数量,达到并行抓取的效果
mapreduce.reduce.shuffle.parallelcopies=5
当 Map 任务数量完成率再 5% 时,Reduce 任务启动,这个参数不建议修改
mapreduce.job.reduce.slowstart.completedmaps=0,05
文件合并 (Merge) 影子,如果文件数量太多,可以适当调大,减少 IO 次数
io.sort.factor=10
是否对 Map 的输出结果文件进行压缩,开启后 CPU 利用率会提高,但节省带宽
mapred.compress.map.output=false
启动 map/reduce 任务的推测执行机制,对拖后腿的任务一种优化机制。当一个作业的某些任务运行速度明显慢于同作业的其他任务时,Hadoop 会在另一个节点上为慢任务启动一个备份任务,这样两个任务同时处理一份数据,而 Hadoop 最终会将优先完成的那个任务的结果做为最终结果,并将另一个任务杀掉。
mapred.map.tasks.speculative.execution=true
mapred.reduce.tasks.speculative.execution=true
2
# 注意
- 只会在被分配的 文件的 block 上启动 Map 任务
- 一个目录有多少个文件,就会分多少个 Map 任务
- Map 读文件默认是一行一行读取,该条件可以设置。
- Map 会按照 Key 做排序,自定义排序可以实现 WritableComparable 接口
- Reducer 主要做聚合操作
- Reduce 会把数据分区 (Hash),ReduceTask (1) 的数据不会 ReduceTask (2) 的结果中出现,输出的文件根据设置的工作数有关,可以使用 hadoop fs -getmerge / 目录 / 所有文件 / 目录 / 新得文件.txt 进行整合。
- ReduceTask 有分区的话会先分区再聚合。
- 分区可能会造成数据倾斜现象