 Hadoop SpringBoot集成
Hadoop SpringBoot集成
# 配置环境
我使用的不是直接在 Hadoop 官网下载的和安装的 hadoop 对应 hadop 版本的解压包,我是用 winutils-master 的,包整个大小只有 6M 左右,里面提供了对 hadoop 在 windows 上的支持,3.x 以上使用 3.0.0 就行,下载可以在网上搜索 winutils-master 或 winutils。
windows 开发 HDFS 或使用 big data tools 插件 都一定要配置 HADOOP_HOME,把以上下载的配置到我们系统环境变量并名命 HADOOP_HOME=D:\tools\winutils-master\hadoop-3.0.0。然后在 path 上加 % HADOOP_HOME%\bin 即可。但配置完毕后我建议直接重启,有时候配置完不会直接生效。
# spring boot 集成
maven 需要的包
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--引入hadoop-client Jar包 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<!-- 引入hadoop-common Jar包 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<!-- 引入hadoop-hdfs Jar包 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<!-- mapreduce 核心jar包 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
配置类
package com.example.demo.config;
import lombok.Data;
/**
* @author big uncle
* @date 2021/5/10 19:53
* @module
**/
@Data
public class HDFSConfig {
/**
* hdfs 服务器地址
**/
private String hostname;
/**
* hdfs 服务器端口
**/
private String port;
/**
* hdfs 服务器账户
**/
private String username;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
具体实现
package com.example.demo.hdfs;
import com.example.demo.config.HDFSConfig;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.*;
import java.net.URI;
/**
* @author big uncle
* @date 2021/5/10 19:52
* @module
**/
public class HDFSService {
private static FileSystem fileSystem;
static {
HDFSConfig config = new HDFSConfig();
config.setHostname("node113");
config.setPort("9000");
config.setUsername("root");
try {
// 获得FileSystem对象,指定使用root用户上传
fileSystem = FileSystem.get(new URI(getHdfsUrl(config)), new Configuration(),
config.getUsername());
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 文件上传
* @author big uncle
* @date 2021/5/10 20:00
* @param source
* @param destination
* @return void
**/
public static void upload(String source, String destination) {
try {
// 创建输入流,参数指定文件输出地址
InputStream in = new FileInputStream(source);
// 调用create方法指定文件上传,参数HDFS上传路径
OutputStream out = fileSystem.create(new Path(destination));
// 使用Hadoop提供的IOUtils,将in的内容copy到out,设置buffSize大小,是否关闭流设置true
IOUtils.copyBytes(in, out, 4096, true);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 文件下载
* @author big uncle
* @date 2021/5/10 20:00
* @param source
* @param destination
* @return void
**/
public static void download(String source, String destination) {
try {
// 调用open方法进行下载,参数HDFS路径
InputStream in = fileSystem.open(new Path(source));
// 创建输出流,参数指定文件输出地址
OutputStream out = new FileOutputStream(destination);
IOUtils.copyBytes(in, out, 4096, true);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 删除文件
* @author big uncle
* @date 2021/5/10 20:00
* @param target
* @return boolean
**/
public static boolean delete(String target) {
boolean flag = false;
try {
// 调用delete方法,删除指定的文件。参数:false:表示是否递归删除
flag = fileSystem.delete(new Path(target), false);
} catch (Exception e) {
e.printStackTrace();
return false;
}
return flag;
}
/**
* 创建文件夹
* @author big uncle
* @date 2021/5/10 19:59
* @param directory
* @return boolean
**/
public static boolean mkdir(String directory) {
boolean flag = false;
try {
// 调用mkdirs方法,在HDFS文件服务器上创建文件夹。
flag = fileSystem.mkdirs(new Path(directory));
} catch (Exception e) {
e.printStackTrace();
return false;
};
return flag;
}
/**
* 拼接连接
* @author big uncle
* @date 2021/5/10 20:00
* @param config
* @return java.lang.String
**/
private static String getHdfsUrl(HDFSConfig config) {
StringBuilder builder = new StringBuilder();
builder.append("hdfs://").append(config.getHostname()).append(":").append(config.getPort());
return builder.toString();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
遇到如下报错: 先确定端口开放
Call From LAPTOP-9DN4GQON/192.168.xxx.xx to node113:9000 failed on connectio
使用命令 netstat -tpnl 查看 hadoop 是否是你的 IP 地址,如果是 127.0.0.1 那肯定连不上,或者直接在 core-site.xml 指定成 IP,或者修改 hosts。
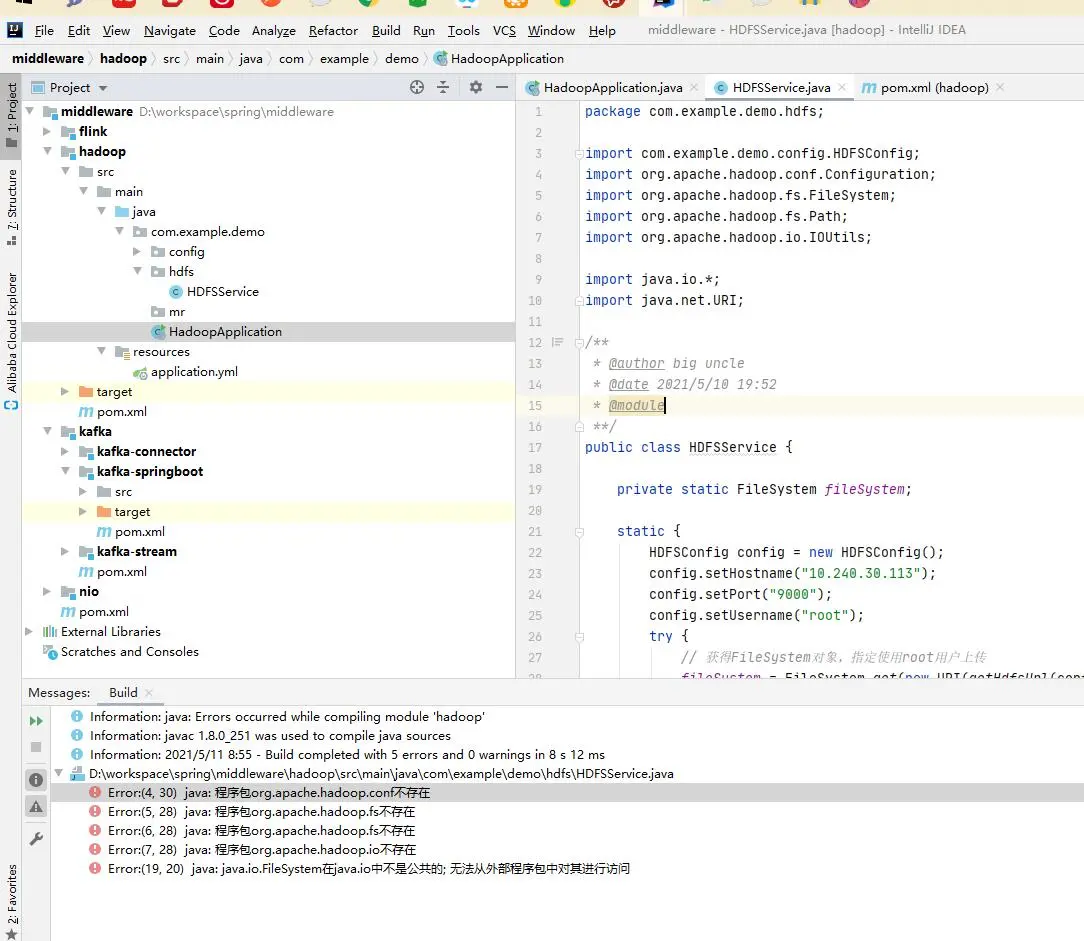
如果遇到 org.apache.hadoop.conf 或 fs 等包不存在问题
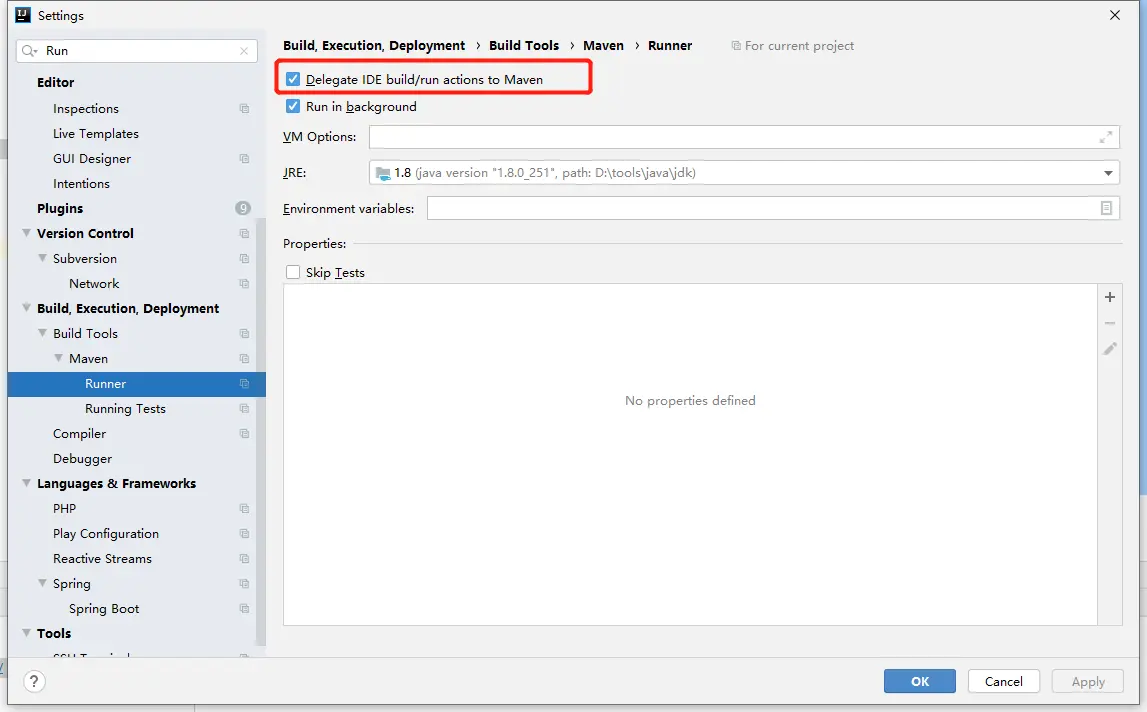
勾选如下即可
# big data tools 配置
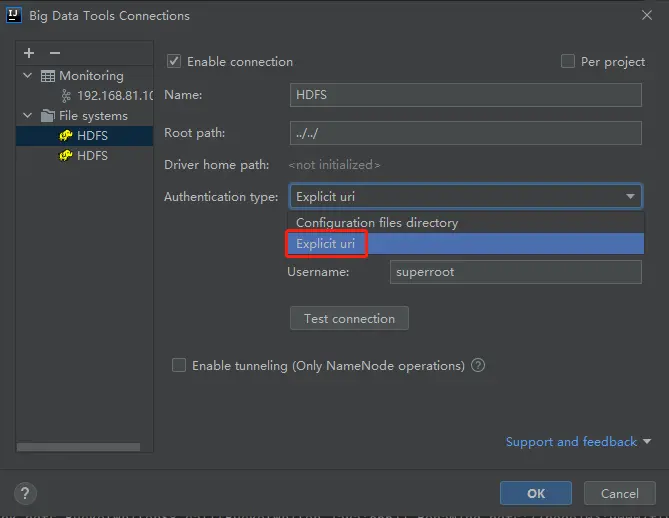
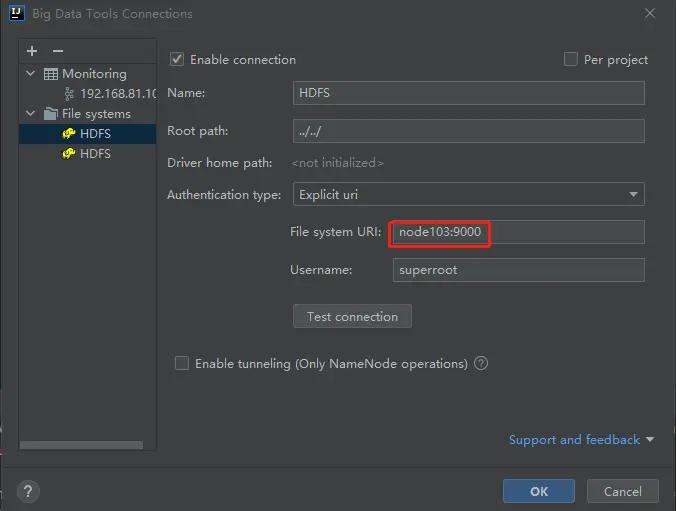
输入 active 的地址
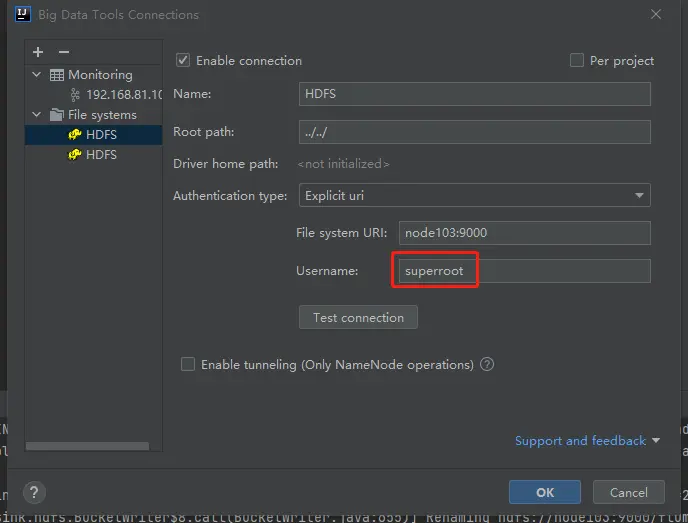
输入 linux 的用户
上次更新: 1/1/2026, 8:54:37 PM