 Hadoop 读写流程详解
Hadoop 读写流程详解
# 读文件流程
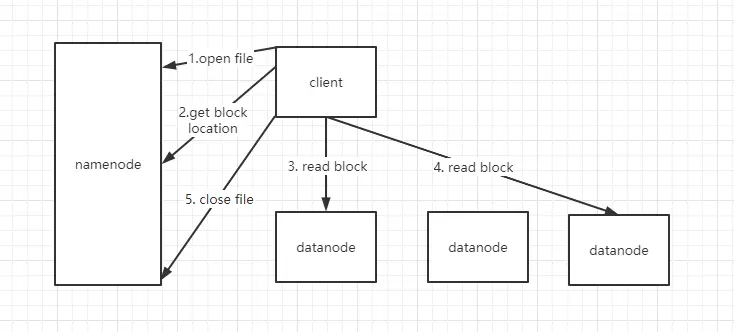
- 客户端向 namenode 发起 Open File 请求,目的是获取要下载文件的输入流。namenode 收到请求会后会检查路径的合法性,以及客户端的权限。
- 客户端发起 Open File 的同时,还会掉用 GetBlockLocation。当第一次的检验通过之后,namenode 会将文件的块信息 (元数据) 封装到输入流,交给客户端。
3.4. 客户端用输入流,根据元数据信息去找指定的 datanode 读取文件块 (按 blockid 顺序读取) - 文件下载完成后关闭。
# 上传文件流程
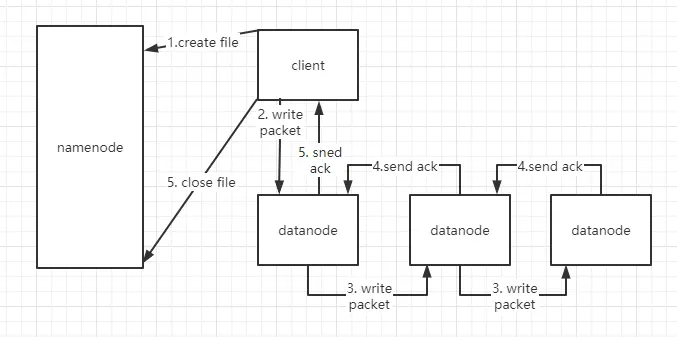
- 客户端发起 create file,目的是获取 HDFS 文件的输出流。namenode 收到请求后会检测路径的合法性,以及权限。原生 hadoop 管理是很不完善的,工作中中用的是 CDH (商业版 hadoop)。如果检测通过,namenode 会为这个文件生成块的元数据,比如:
- 为文件切块
- 分配块 id
- 分配每个块存在哪个 datanode 上
然后将元数据封装到输出流中,返回给客户端。
2.3. client 拿到输出流之后,采用 PipeLine(数据流管道)机制做数据的上传(发送),这样设计的目的在于利用每台服务器的带宽,最小化推送数据的延迟,减少 client 带宽的发送。线性模式下,每台机器所有的出口带宽用于以最快的速度传输数据,而不是在多个接收者之间分配带宽。packet,是客户端把文件块打散成一个个的数据包发送。用的是全双通信,边收边发。
4.5. 每台 datanode 收到 packet 后,会向上游 datanode 做 ack 确认,如果接收失败,会进行重发(重发机制)
- 当一个文件上传完之后,关闭流。
# 删除文件流程
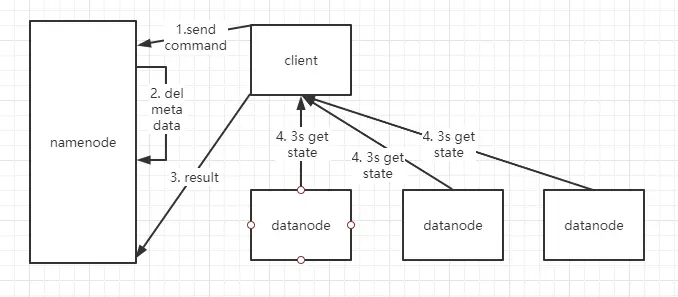
- 当客户端发起一个删除指令,这个指令会传给 namenode
- namenode 收到指令,做路径和权限校验,如果检验通过,会将对应的文件信息从内存里删除。此时,文件数据并不是马上就从集群被删除。
- datanode 向 namenode 发送心跳时 (默认时 3s 周期),会领取删除指令没然后从磁盘上将文件删除。
上次更新: 1/1/2026, 8:54:37 PM