 Hadoop 伪分布式及集群
Hadoop 伪分布式及集群
本文及后续所有文章都以 3.1.3 做为版本讲解和入门学习
在开始做 hadoop 的时候,首先要做以下几点:1. 修改 hostname 2. 修改机器之间免密登录
目前我有三台机器,node103,node104,node113。先用 node113 搭建一台伪分布式学习用,如果是为了 集群,跳过这里就行。
# Hadoop 伪分布式
下载连接 http://www.apache.org/dyn/closer.cgi/hadoop/common/ 可以自己选择版本进行下载。解压完成后看如下操作:
- 进入 /hadoop-3.1.3/etc/hadoop 目录,配置 hadoop-env.sh
# 进入目录
cd /opt/software/hadoop-3.1.3/etc/hadoop
# 编辑文件
vim hadoop-env.sh
# 修改jdk安装位置
export JAVA_HOME=/opt/software/java8
# 修改hadoop安装位置
export HADOOP_CONF_DIR=/opt/software/hadoop-3.1.3/etc/hadoop
2
3
4
5
6
7
8
- 修改 core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node113:9000</value>
</property>
<!-- 指定Hadoop运行时产生元数据文件的存储目录,改目录需要自己手动创建 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop-3.1.3/data/tmp</value>
</property>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
- 修改 hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
- 修改 workers 文件
hadoop3.0 以后 slaves 更名为 workers
node113
- 检查配置
# 进入bin目录
cd /opt/software/hadoop-3.1.3/bin
# 启动检查命令
./hadoop namenode -format
# 查输出信息有以下代表配置正确
successfully formatted.
2
3
4
5
6
- 启动
# 进入目录
cd /opt/software/hadoop-3.1.3/sbin
# 启动
./start-dfs.sh
# 如果启动报错,修改start-dfs.sh 和 stop-dfs.sh,并添加如下
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2
3
4
5
6
7
8
9
- 查看启动是否正确
# jps 查看,如果包含以下进程则启动正确
# 存放元数据信息
NameNode
# 管理 NameNode 的 edit logs 和 fsimage,定时把 edit logs 写道 fsimage 然后copy到 NameNode
# edit logs 是 NameNode 重启后的写日志信息,fsimage是重启前读取的快照数据
SecondaryNameNode
# 存储数据块
DataNode
2
3
4
5
6
7
8
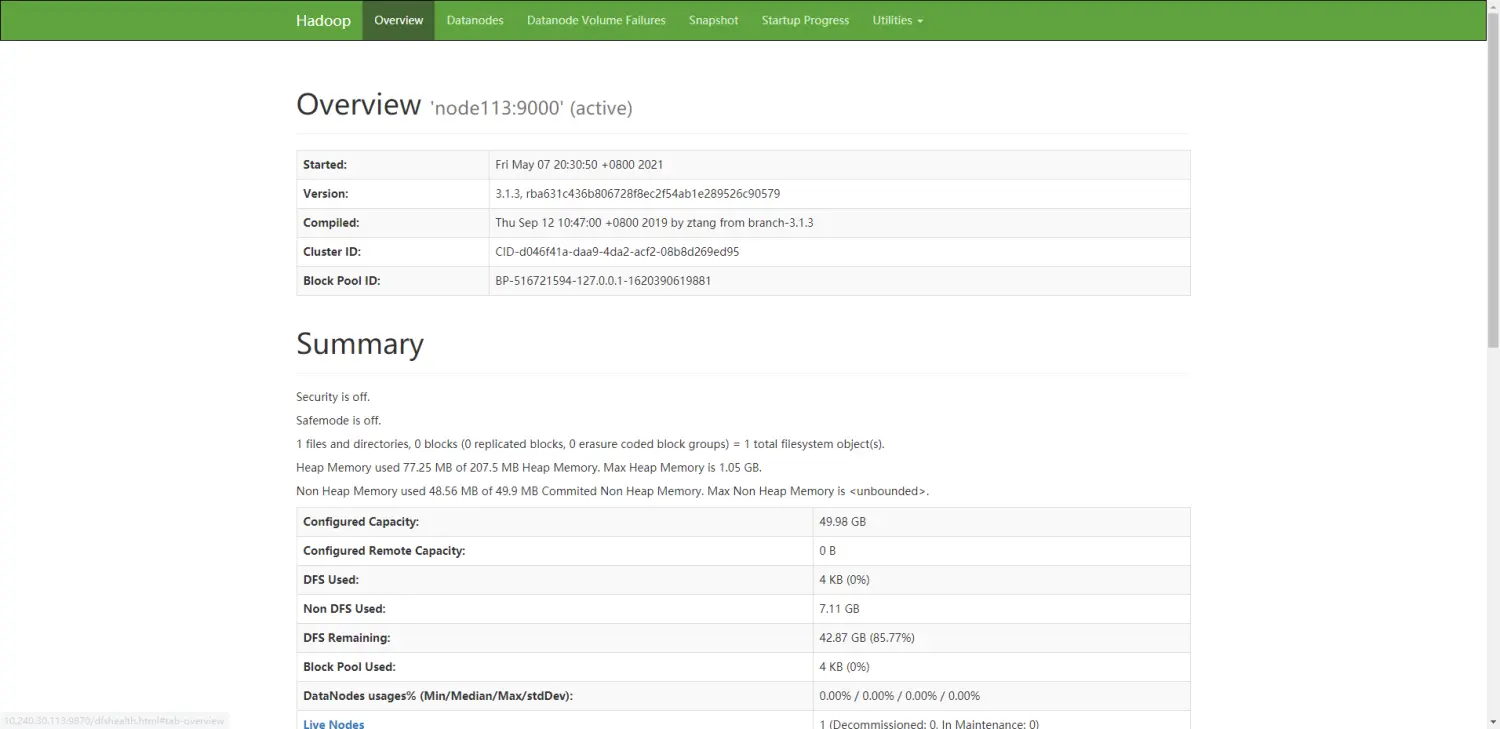
- 也可以访问浏览器来验证启动正确性
# hadoop 3.x 及以上 50070 改为了 9870
http://10.240.30.113:9870/dfshealth.html#tab-overview
# 允许端口访问
/sbin/iptables -I INPUT -p tcp --dport 9870 -j ACCEPT
2
3
4
- 把 hadoop 放到环境变量中
vim /etc/profile
export HADOOP_HOME=/opt/software/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH JAVA_HOME HADOOP_HOME
source /etc/profile
2
3
4
5
# Hadoop 集群
# hadoop 集群试图
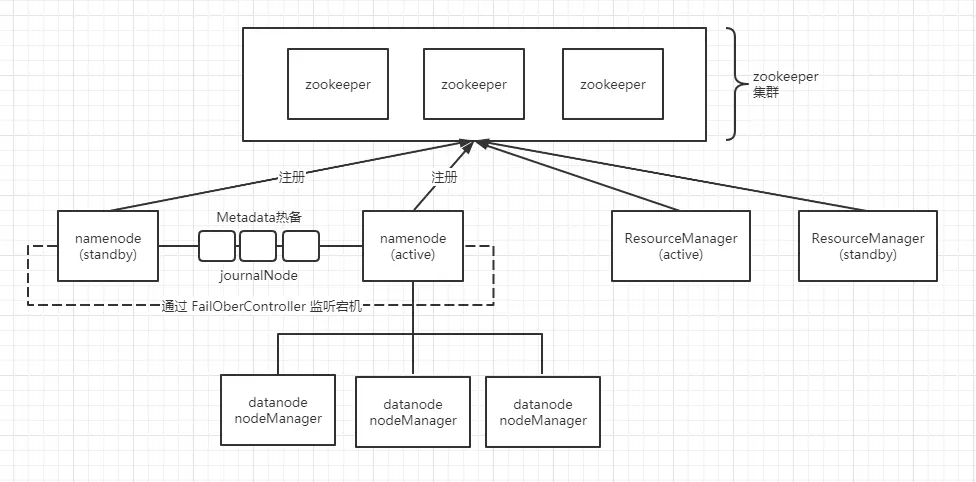
# hadoop 集群搭建
| hostname | zookeeper | nameNode | ResourceManager | journalNode | dataNode/nodeManager |
|---|---|---|---|---|---|
| node103 | 1 | 1 active | 1 | 1 | 1 |
| node104 | 1 | 1 standby | 1 | 1 | |
| node113 | 1 | 1 | 1 | 1 |
把之前伪分布式全部停掉,copy 之前的伪分布式配置为以后切换伪分布式提供便利
- 修改 node103 的 hadoop-env.sh 文件,和以上伪分布式一致就行
- 修改 node103 的 core-site.xml 文件
<configuration>
<!-- 为整个分布式系统起一个别名 ns=nameService-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop-3.1.3/data/tmp</value>
</property>
<!-- 执行zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node103:2181,node104:2181,node113:2181</value>
</property>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 修改 node103 的 hdfs-site.xml 文件
<configuration>
<!-- 执行hdfs的nameservices为ns,和core-site.xml 保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下有两台namenode,分别是 n103,n104(别名) -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>n103,n104</value>
</property>
<!-- n103的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.n103</name>
<value>node103:9000</value>
</property>
<!-- n103的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.n103</name>
<value>node103:9870</value>
</property>
<!-- n104的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.n104</name>
<value>node104:9000</value>
</property>
<!-- n104的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.n104</name>
<value>node104:9870</value>
</property>
<!-- 指定namenode的元数据在JournalNode上哪些机器上存放,主要从namenode获取最新信息,达到热备 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node103:8485;node104:8485;node113:8485/ns</value>
</property>
<!-- 指定JournalNode存放数据的位置,需要手动创建 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/software/hadoop-3.1.3/data/journal</value>
</property>
<!-- 开启namenode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置切换的实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 配置隔离机制的ssh登录密钥所在的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置namenode数据存放的位置,可以不配置,如果不配置,默认使用得时core-site.xml里配置的hadoop.tmp.dir的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/software/hadoop-3.1.3/data/namenode</value>
</property>
<!-- 配置datanode数据存放的位置,可以不配置,如果不配置,默认使用的是core-site.xml里配置的hadoop.tmp.dir的路径 -->
<property>
<name>dfs.datanode.name.dir</name>
<value>file:///opt/software/hadoop-3.1.3/data/datanode</value>
</property>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
- 修改 node103 的 mapred-site.xml 文件,和以上伪分布式一致就行
- 修改 node103 的 yarn-site.xml 文件
<configuration>
<!-- 开启YARN HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定两个resourcemanager的名称 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置rm1的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node103</value>
</property>
<!-- 配置rm2的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node113</value>
</property>
<!-- 开启yarn恢复机制 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 执行rm恢复机制实现类 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置zookeeper的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node103:2181,node104:2181,node113:2181</value>
<description>For multiple zk services, separate them with comma</description>
</property>
<!-- 指定YARN HA的名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
<!-- 指定yarn 主 resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node103</value>
</property>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
- 修改 node103 的 workers 文件,该文件会指定启动 dataNode,nodeManager
node103
node104
node113
2
3
把以上配置 copy 到其他 hadoop 里覆盖配置,删除之前 data/ 下的所有文件,并新建 tmp、journal、namenode、databode。完成之后记得所有机器上的环境变量统一修改。
- 启动 zookeeper 集群
- 格式化 zookeeper,在 zookeeper 的 Leader 节点上执行:hdfs zkfc -formatZK,在 zookeeper 集群上会生成 hadoop-ha 节点(ns 节点)
当 namenode 启动,会在 ns 节点下注册自己 - 启动每台的 journalnode 进程,启动成功后用 jps 查看是否有该进程
hadoop-daemon.sh start journalnode
[root@node103 bin]# hadoop-daemon.sh start journalnode
[root@node103 bin]# jps
109297 JournalNode
2
3
- 启动 namenode 进程
# node103 active 先格式化一遍,该命令只能对active使用,
# standby使用就会报错,说你的文件不是空文件
hadoop namenode -format
# node103 active 启动 namenode
hadoop-daemon.sh start namenode
# node104 设置为 standby
hdfs namenode -bootstrapStandby
# node104 standby 启动 namenode
hadoop-daemon.sh start namenode
2
3
4
5
6
7
8
9
- 每台启动 datanode
hadoop-daemon.sh start datanode
出现该错误 ERROR: Cannot set priority of datanode process 12297 ,需要找到 /hadoop-3.1.3/bin/hdfs 注释 HADOOP_SHELL_EXECNAME="hdfs",并在环境变量添加 export HADOOP_SHELL_EXECNAME = 用户
- 启动 zkfc(FalioverControllerActive)故障监听转移及恢复
# 只在node103和node104启动
hadoop-daemon.sh start zkfc
# 启动成功会有以下进程
111060 DFSZKFailoverController
2
3
4
- 启动 nodemanager 以及 resourceManager
# 在 node103 active 启动,会启动其余的 nodemanager
start-yarn.sh
# 在 node 104 启动
yarn-daemon.sh start resourcemanager
2
3
4
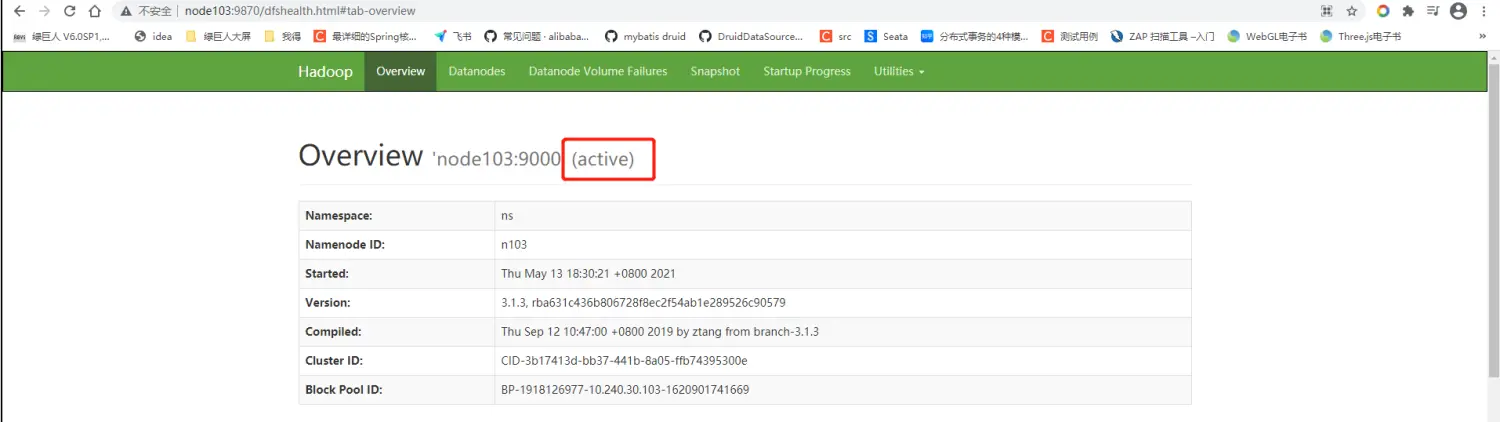
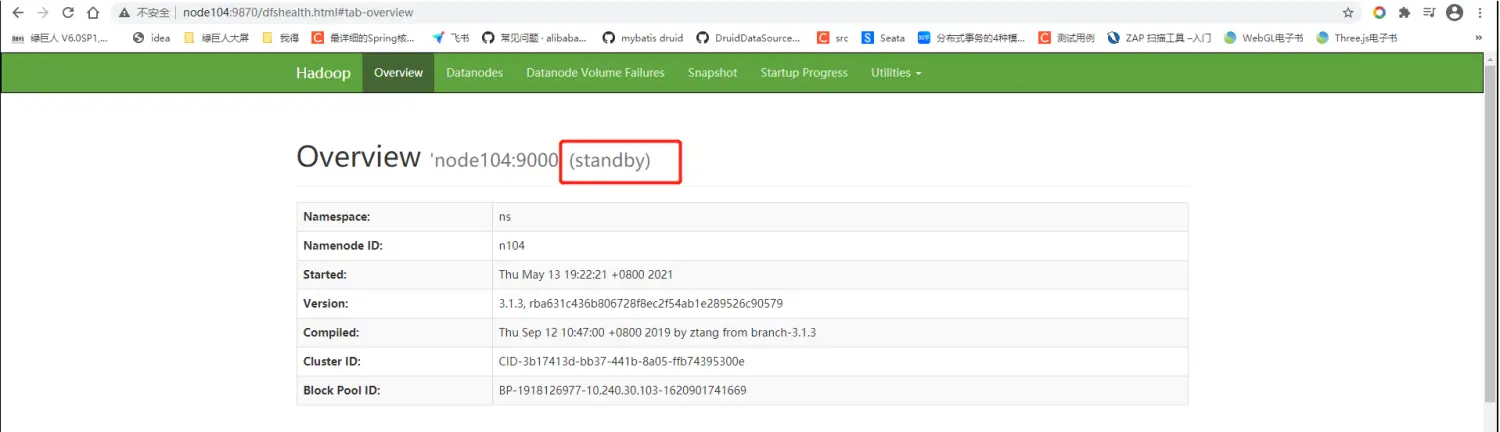
- 查看启动状态
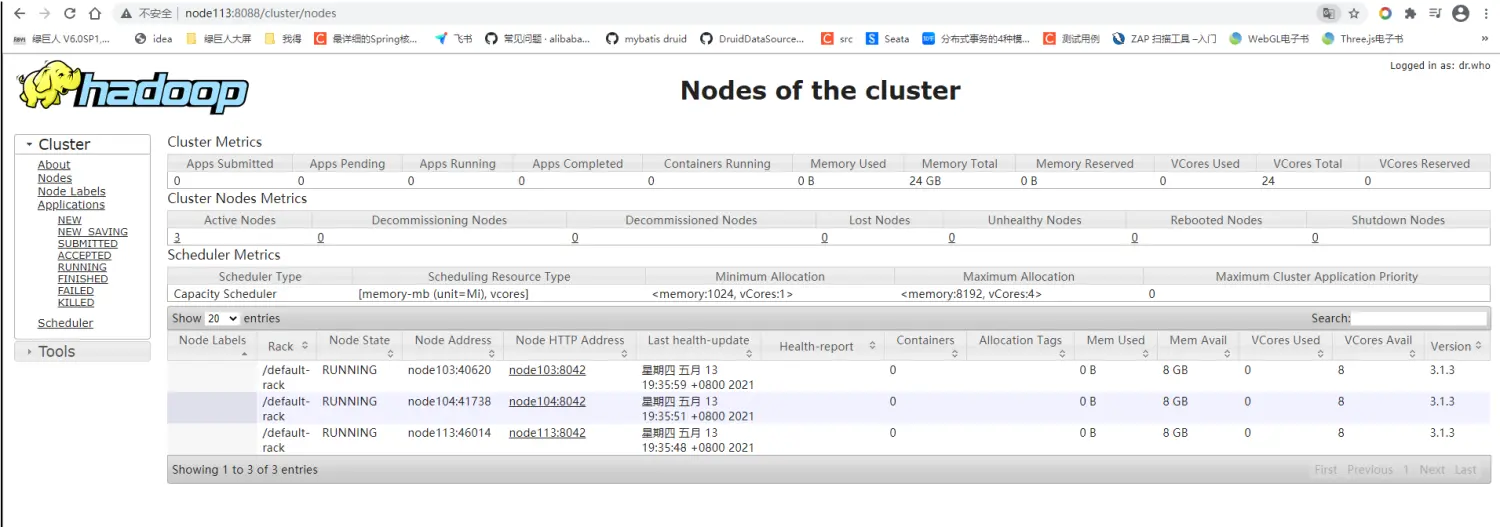
- 停止 / 再次启动 集群
# 在任意的节点,会停止所有节点的进程,除了手动启动的 resourcemanager
stop-all.sh
# 再次启动的话只需要
start-all.sh
# stop-all.sh 会找 stop-dfs.sh、hadoop-config.sh、stop-yarn.sh三个脚本文件,与启动脚本相似
# 如果在文件内配置了HDFS的相关账号,建议全部注释,写到 /etc/profile 里
# 以下两个是 stop-all.sh 需要的
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
2
3
4
5
6
7
8
9
10
- 不停机新加入节点 node114
- 修改其他机器的 workers
node103
node104
node113
node114
2
3
4
- node114 的配置可以 copy 其他机器任意一个
- 删除 node114 下的 tmp、journal、namenode、databode 文件下的所有数据
- 正确配置 hadoop 环境
- 启动 datanode
hadoop-daemon.sh start datanode
# Hadoop 特点
- 支持超大文件:一般来说,HDFS 存储的文件可以支持 TB 和 PB 级别的数据。
- 检测和快速应对硬件故障:在集群环境中,硬件故障是常见性问题。因为有上千台服务器连在一起,故障率高,因此故障检测和自动恢复 hdfs 文件系统的一个设计目标。假设某一个 datanode 节点挂掉之后,因为数据备份,还可以从其他节点里找到。namenode 通过心跳机制来检测 datanode 是否还存在
- 流式数据访问:HDFS 的数据处理规模比较大,应用一次需要大量的数据,同时这些应用一般都是批量处理,而不是用户交互式处理,应用程序能以流的形式访问数据库。主要的是数据的吞吐量,而不是访问速度。访问速度最终是要受制于网络和磁盘的速度,机器节点再多,也不能突破物理的局限,HDFS 不适合于低延迟的数据访问,HDFS 的是高吞吐量。
- 简化的一致性模型:对于外部使用用户,不需要了解 hadoop 底层细节,比如文件的切块,文件的存储,节点的管理。一个文件存储在 HDFS 上后,适合一次写入,多次写出的场景 once-write-read-many。因为存储在 HDFS 上的文件都是超大文件,当上传完这个文件到 hadoop 集群后,会进行文件切块,分发,复制等操作。如果文件被修改,会导致重新出发这个过程,而这个过程耗时是最长的。所以在 hadoop 里,不允许对上传到 HDFS 上文件做修改(随机写),在 2.0 版本时可以在后面追加数据。但不建议。
- 高容错性:数据自动保存多个副本,副本丢失后自动恢复。可构建在廉价机上,实现线性(横向)扩展,当集群增加新节点之后,namenode 也可以感知,将数据分发和备份到相应的节点上。
- 商用硬件:Hadoop 并不需要运行在昂贵且高可靠的硬件上,它是设计运行在商用硬件的集群上的,因此至少对于庞大的集群来说,节点故障的几率还是非常高的。HDFS 遇到上述故障时,被设计成能够继续运行且不让用户察觉到明显的中断。
# Hadoop 特性
- 高可靠性:采用冗余数据存贮方式,即使一个副本发生故障,其他副本也可以保证对外工作的正常进行。
- 高效性:作为并行分布式计算平台,hadoop 采用分布式存贮和分布式处理两大核心技术,能够高效的处理 PB 级别的数据
- 高可扩展性:hadoop 的设计目标是可以高效稳定的运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上。
- 高容错性:采用冗余数据存贮方式,自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 成本低:hadoop 采用廉价的计算机集群,普通的用户也可以 pc 机搭建环境
- 运行在 linux 平台上,hadoop 是基于 java 语言开发的,可以较好的运行在 linux 的平台上
# Haddop 注意
- 安全模式(1):当 HDFS 启动时,每个 datanode 会向 namenode 汇报自身的存储信息,比如存储了哪些文件快,块大小,块 id 等。namenode 收到这些信息之后,会做到汇总和检查,监测数据是否完整,副本数量是否达到要求,如果检测出现问题,HDFS 会进入安全模式,该模式只允许读,不允许写, 并自动做数据或副本的复制,直到修复完成后,自动退出安全模式。
- 安全模式(2):如果是伪分布模式,副本只能配置 1 个,大于 1 个会导致 HDFS 一直安全模式不能退出。
- HDFS 不适合存储海量小文件,每当上传一个文件,namenode 就会有一个元数据信息占用内存,一条元数据信息大约在 150 字节左右,海量小文件不值得。
- hadoop 不能并行写,hdfs 不能并发写指的是不能同时上传同位置同名文件。两个同名文件,一个文件成功上传,再用另一个客户端上传同名文件,会提示 File exists。防止文件写乱,底层加了锁,使用类似 Redssion 看门狗的概念。
- HDFS 不能做到低延迟的数据访问(毫秒级就内给出响应)。但是 Hadoop 的优势在于它的吞吐率(单位时间内产生的数据流 )。可以说 HDFS 的设计时牺牲了低延迟的数据访问,而获取的是数据的高吞吐率,如果想要获取低延迟的数据访问,可以通过 Hbase 框架来实现。
# Hadoop 回收站机制
开启回收站机制需要修改 core-site.xml 文件,添加如下:
<!-- 开启回收站机制,周期时间单位是分钟,0是不开启该机制 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
2
3
4
5
开启回收站模式后,删除的文件或目录会存储到另一个地方。
面对启动或停止指令,加到环境变量才是最好的选择
export HDFS_DATANODE_SECURE_USER=hdfs
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root