 Flume Process
Flume Process
本文及后续所有文章都以 1.8.0 做为版本讲解和入门学习
# Failover Sink Processor 故障恢复
Sink Group 允许用户将多个 Sink 组合成一个实体。Flume Sink Process 可以通过切换组内 Sink 用来实现负载均衡的效果,或在一个 Sink 故障时切换到另一个 Sink。
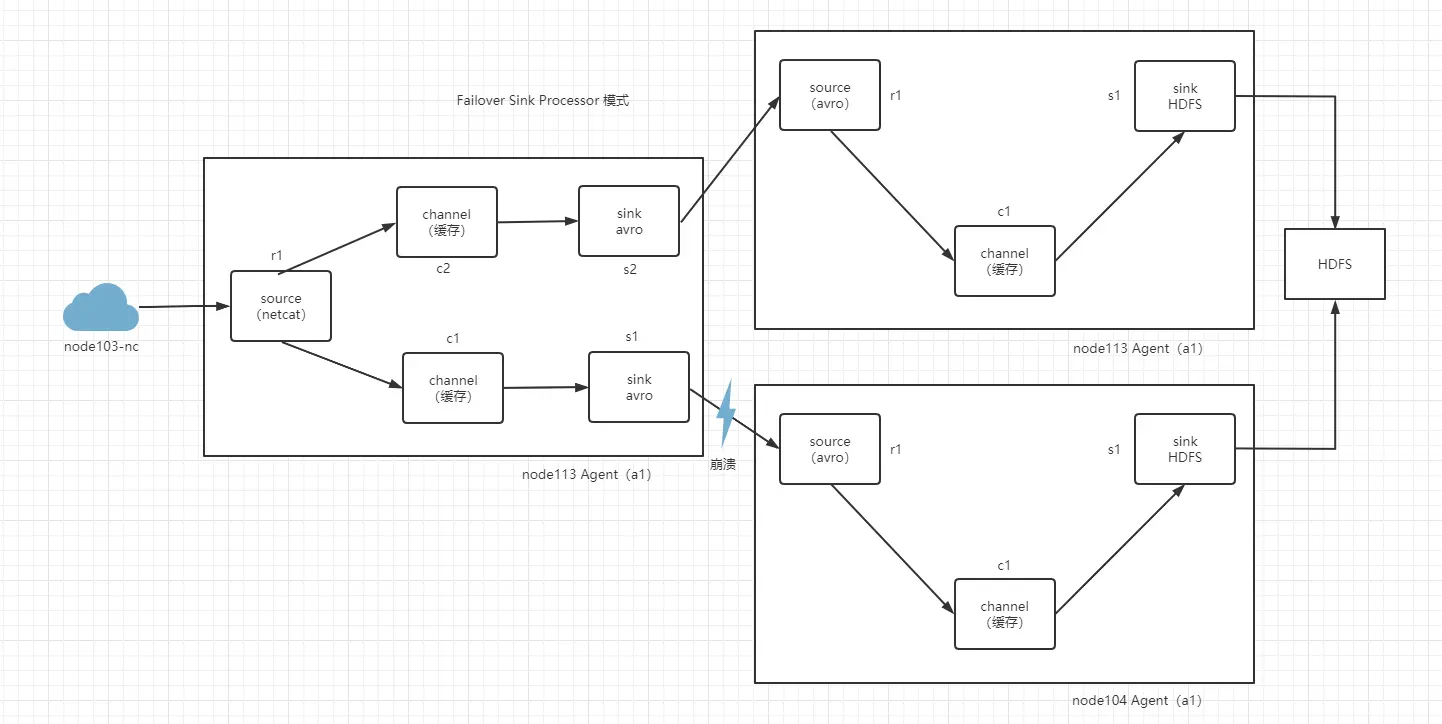
Failover Sink Processor 维护一个 sink 们的优先表。确保只要一个可用的,事件就可以被处理。失败处理原则是,为失效的 sink 指定一个冷却时间,在冷却时间达到后再重新使用,这里会有个问题就是重新启动的 flume 和备用的 flume 都会接收到信息。当 node104 宕机不在工作,node113 就会被执行工作。
sink 们可以被配置一个优先级,数字越大优先级越高。
如果 sink 们发送时间失败,则下一个最高优先级的 sink 奖会尝试接着发送事件。
如果没有指定优先级,则优先级顺序取决于 sink 们的配置顺序,先配置的默认优先级高于后配置的。
在配置过程中,设置一个 group processor,并且为每个 sink 指定一个优先级,优先级必须是唯一的。
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1 c2
a1.sinks=s1 s2
# 配置故障恢复
a1.sinkgroups=g1
a1.sinkgroups.g1.sinks=s1 s2
a1.sinkgroups.g1.processor.type=failover
a1.sinkgroups.g1.processor.priority.s1=5
a1.sinkgroups.g1.processor.priority.s2=10
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=netcat
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 指定a1的channels基于内存
a1.channels.c1.type=memory
a1.channels.c2.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=node103
a1.sinks.s1.port=8888
a1.sinks.s2.type=avro
a1.sinks.s2.hostname=node104
a1.sinks.s2.port=8888
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1 c2
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# Load balancing Sink Processor 负载均衡
Load balancing Sink Processor 提供了再多个 sink 之间实现负载均衡的能力。他维护了一个活动 sink 的索引列表。它支持轮询或所及方式的负载均衡,默认值是轮询方式,可以通过篇日志指定,也可以通过实现 AbstractSinkSelector 接口实现自定义的选择机制。
负载均衡的机制是通过 单个 channel 轮询或随机发送给某个 sink。
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1 s2
# 配置负载
a1.sinkgroups=g1
a1.sinkgroups.g1.sinks=s1 s2
a1.sinkgroups.g1.processor.type=load_balance
a1.sinkgroups.g1.processor.selector=round_robin
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=netcat
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=node103
a1.sinks.s1.port=8888
a1.sinks.s2.type=avro
a1.sinks.s2.hostname=node104
a1.sinks.s2.port=8888
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# flume 内存通道事务机制
flume 的事务机制与可靠性保证的实现,最核心的组件是 channel,如果没有 channel 组件,而仅靠 source 与 sink 组件是无从谈起的。
# put 事务
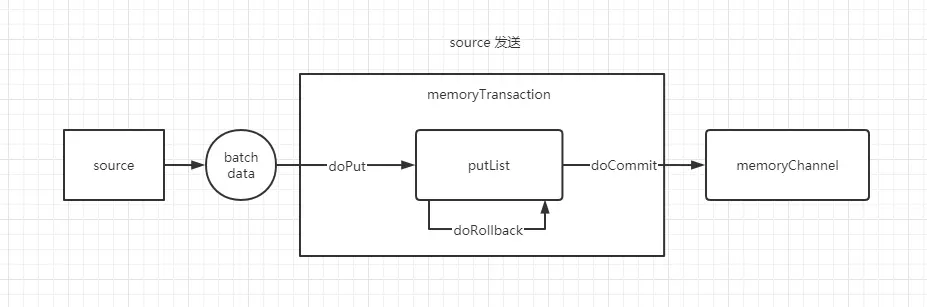
# put 事务流程
- doput 将批数据先写入临时缓冲区 putList(LinkedBlockingDequeue)链表结构组成的双向阻塞队列。
- doCommit 检查 memoryChannel 内存队列是否足够合并
- doRollback memoryChannel 内存队列空间不足,回滚,等待内存通道容量满足合并
putList 就是一个临时的缓冲区,数据会先 put 到 putList,最后由 commit 方法检查 memoryChannel 是否有足够的缓冲区,有则合并到 memoryChannel 的队列。
# take 事务
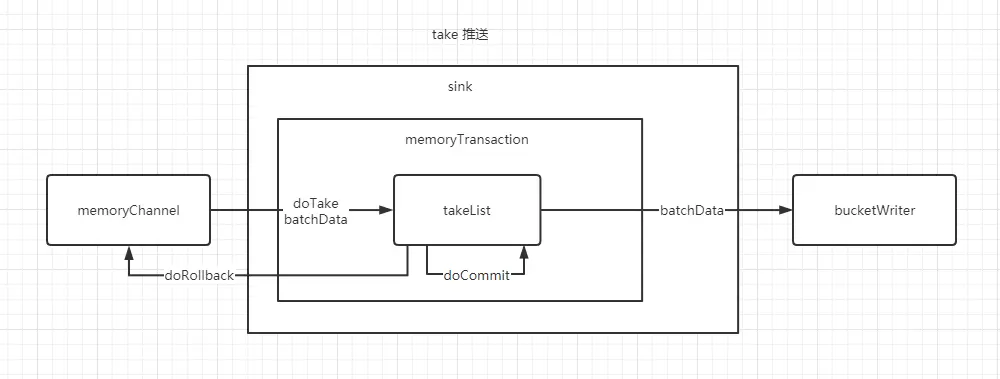
# take 事务流程
- doTake 先将数据发往临时缓冲区 takeList(LinkedBlockingDequeue)将输出发送到下一个节点
- doCimmit 如果数据全部发送成功,则清除临时缓冲区 takeList
- doRollback 数据发送过程中出现异常,rollback 将临时缓冲区 takeList 中的数据归还给 memoryChannel
- bucketWriter 类 会监听数据的发送成功或失败,并响应给 takeList