 Flume Interceptor拦截器类型
Flume Interceptor拦截器类型
本文及后续所有文章都以 1.8.0 做为版本讲解和入门学习
# Timestamp Interceptor
这个拦截器在事件 headers 中插入以毫秒为单位的处理时间。headers 的 key 为 timestamp,value 为当前处理的时间戳。如果在之前已经有这个时间戳,则保留原有的时间戳。
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=http
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 设置拦截器,名称
a1.sources.r1.interceptors=i1
# 时间戳拦截器
a1.sources.r1.interceptors.i1.type=timestamp
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=logger
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# Host Interceptor
这个拦截器插入当前处理 Agent 的主机名或 IP,headers 的 key 为 host 或配置的名称,value 是主机名或 ip 地址,基于配置。
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=http
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 设置拦截器,名称
a1.sources.r1.interceptors=i1 i2
# 时间戳拦截器
a1.sources.r1.interceptors.i1.type=timestamp
# host 拦截器
a1.sources.r1.interceptors.i2.type=host
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=logger
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# Static Interceptor
此拦截器允许用户增加静态头信息使用静态的值到所有事件,目前的实现中不允许一次指定多个头,如果需要增加多个静态头可以指定多个 static Interceptor
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=http
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 设置拦截器,名称
a1.sources.r1.interceptors=i1 i2 i3
# 时间戳拦截器
a1.sources.r1.interceptors.i1.type=timestamp
# host 拦截器
a1.sources.r1.interceptors.i2.type=host
# static 拦截器
a1.sources.r1.interceptors.i3.type=static
a1.sources.r1.interceptors.i3.key=addr
a1.sources.r1.interceptors.i3.type=bj
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=logger
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# UUID Interceptor
这个拦截器在所有事件头中增加一个全局一致性标志,其实就是 UUID。
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=http
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 设置拦截器,名称
a1.sources.r1.interceptors=i1 i2 i3 i4
# 时间戳拦截器
a1.sources.r1.interceptors.i1.type=timestamp
# host 拦截器
a1.sources.r1.interceptors.i2.type=host
# static 拦截器
a1.sources.r1.interceptors.i3.type=static
a1.sources.r1.interceptors.i3.key=addr
a1.sources.r1.interceptors.i3.type=bj
# UUID 拦截器
a1.sources.r1.interceptors.i4.type=org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=logger
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# Search and Replace Interceptor
这个拦截器提供了简单的基于字符串的正则搜索和替换功能。
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=http
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 设置拦截器,名称
a1.sources.r1.interceptors=i1 i2 i3 i4 i5
# 时间戳拦截器
a1.sources.r1.interceptors.i1.type=timestamp
# host 拦截器
a1.sources.r1.interceptors.i2.type=host
# static 拦截器
a1.sources.r1.interceptors.i3.type=static
a1.sources.r1.interceptors.i3.key=addr
a1.sources.r1.interceptors.i3.type=bj
# UUID 拦截器
a1.sources.r1.interceptors.i4.type=org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
# Search and Replace 拦截器,基于 body体去找
a1.sources.r1.interceptors.i5.type=search_replace
# 搜索和替换的正则表达式
a1.sources.r1.interceptors.i5.searchPattern=[0-9]
# 要替换的字符串
a1.sources.r1.interceptors.i5.replaceString=*
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=logger
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# Regex Filtering Interceptor
这个拦截器通过解析事件体去匹配给定正则表达式来筛选事件。所提供的正则表达式既可以用来包含或刨除 (丢弃) 事件。
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=http
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 设置拦截器,名称
a1.sources.r1.interceptors=i1 i2 i3 i4 i5 i6
# 时间戳拦截器
a1.sources.r1.interceptors.i1.type=timestamp
# host 拦截器
a1.sources.r1.interceptors.i2.type=host
# static 拦截器
a1.sources.r1.interceptors.i3.type=static
a1.sources.r1.interceptors.i3.key=addr
a1.sources.r1.interceptors.i3.type=bj
# UUID 拦截器
a1.sources.r1.interceptors.i4.type=org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
# Search and Replace 拦截器,基于 body体去找
a1.sources.r1.interceptors.i5.type=search_replace
# 搜索和替换的正则表达式
a1.sources.r1.interceptors.i5.searchPattern=[0-9]
# 要替换的字符串
a1.sources.r1.interceptors.i5.replaceString=*
# Search and Replace 拦截器,基于 body体去找
a1.sources.r1.interceptors.i6.type=regex_filter
# 所要匹配的正则表达式
a1.sources.r1.interceptors.i6.regex=^jp.*$
# 默认false,如果是true则刨除(丢弃)匹配的事件,false则包含匹配的事件。
a1.sources.r1.interceptors.i6.excludeEvents=true
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=logger
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
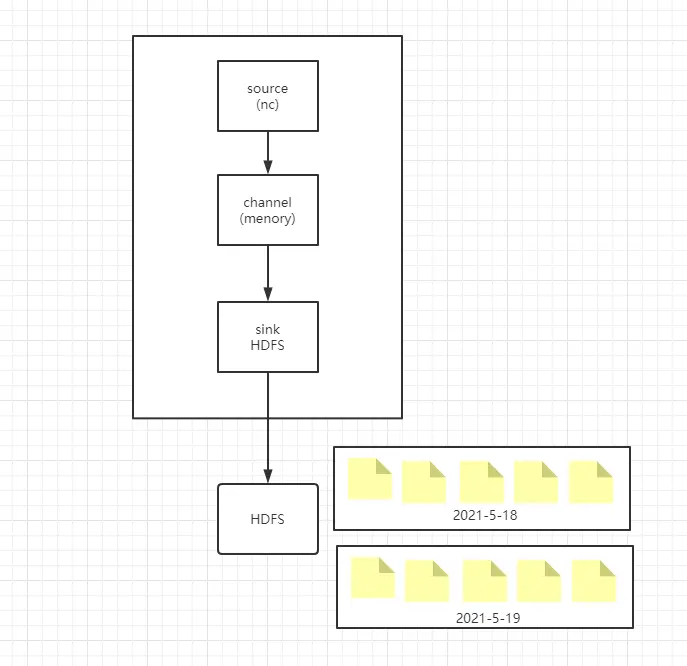
# Timestamp Interceptor 与 HDFS 实际使用
根据 Timestamp 拦截器,让在 HDFS 以事件生成的时间戳,查找当前时间戳以天为单位的文件夹,没有则新建文件夹,并把内容生成文件写到该文件夹,以此类推。
实际使用视图
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=netcat
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 设置拦截器,名称
a1.sources.r1.interceptors=i1
# 时间戳拦截器
a1.sources.r1.interceptors.i1.type=timestamp
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到 hdfs
a1.sinks.s1.type=hdfs
# 输出地址 flume 会自动创建
a1.sinks.s1.hdfs.path=hdfs://node103:9000/flume=%Y-%m-%d
# 一小时 单位 秒,每隔1小时输出一次
a1.sinks.s1.hdfs.rollInterval=3600
# 根据文件大小来进行输出,0 不开启 单位 字节
a1.sinks.s1.hdfs.rollSize=0
# 根据内容行数来进行输出,0 不开启 单位 字节
a1.sinks.s1.hdfs.rollCount=0
# 输出文件的类型:SequenceFile(二进制) DataStream(文本)
a1.sinks.s1.hdfs.fileType=DataStream
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
上次更新: 1/1/2026, 8:54:37 PM