 Flume Selector
Flume Selector
本文及后续所有文章都以 1.8.0 做为版本讲解和入门学习
# Selector 概念
选择器可以工作在复制、多路复用 (路由) 模式,selector 默认是复制模式(replicating),即把 source 复制,然后分发给多个 sink。路由模式就是根据 http 发送的消息头来区分消息发往那个 sink。
路由模式
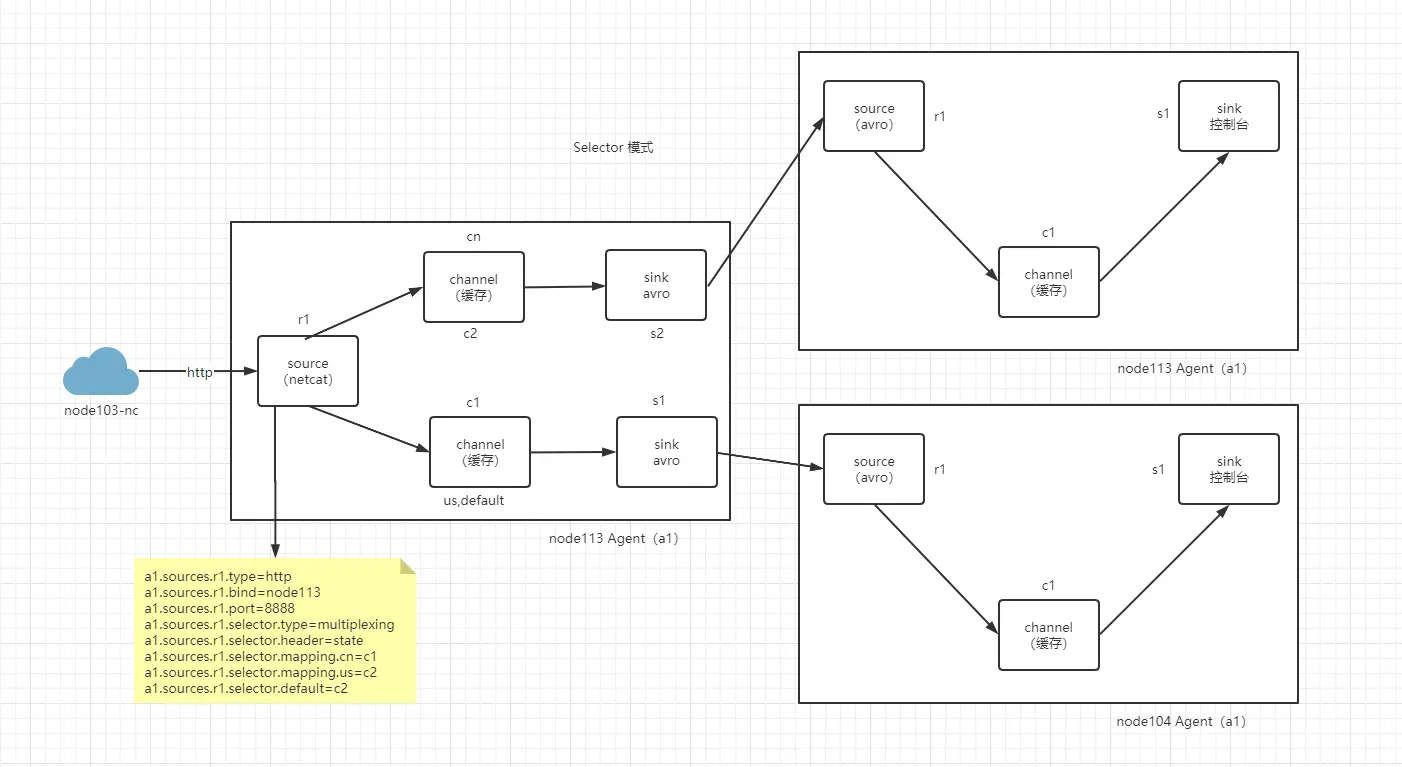
# 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1 c2
a1.sinks=s1 s2
# 指定source 的数据来源以及堆外开放的端口
a1.sources.r1.type=http
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
a1.sources.r1.selector.type=multiplexing
# 指定header路由的key
a1.sources.r1.selector.header=state
# 指定header路由的值
a1.sources.r1.selector.mapping.cn=c1
# 指定header路由的值
a1.sources.r1.selector.mapping.us=c2
a1.sources.r1.selector.default=c2
# 指定a1的channels基于内存
a1.channels.c1.type=memory
a1.channels.c2.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=node103
a1.sinks.s1.port=8888
a1.sinks.s2.type=avro
a1.sinks.s2.hostname=node104
a1.sinks.s2.port=8888
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1 c2
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
当 headers 的 key 为 state 值为 cn 发送给 c1
curl -X POST -d '[{"headers":{"state":"cn"},"body":"hello hello"}]' http://node113:8888
1
当 headers 的 key 为 state 值为 us 发送给 c2
curl -X POST -d '[{"headers":{"state":"us"},"body":"hello hello"}]' http://node113:8888
1
当 headers 的 key 为 state 值为 abc 发送给 c2,即默认的
curl -X POST -d '[{"headers":{"state":"abc"},"body":"hello hello"}]' http://node113:8888
1
上次更新: 1/1/2026, 8:54:37 PM