 Flume Sink支持的类型
Flume Sink支持的类型
本文及后续所有文章都以 1.8.0 做为版本讲解和入门学习
# Logger Sink
记录指定级别(比如 INFO,DEBUG,ERROR 等)的日志,通常用于测试,要求在 -c 参数指定的目录下有 logge4j 的配置文件。
根据设计,logger sink 将内容限制为 16 字节,从而避免屏幕充斥过多的内容。如果想要查看调试的完整内容,那么你应该使用其他的 sink,也许可以使用 file_roll_sink,它会将日志写到本地文件系统中。
# Logger Sink 配置
a1.sinks.s1.type=logger
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及对外开放的端口
a1.sources.r1.type=avro
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=logger
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# File Roll Sink
在本地系统中存储事件,每隔指定时长生成文件保存这段事件内收集到的日志信息。
a1.sinks.s1.type=file_roll
a1.sinks.s1.sink.dirextory=/home/tmp
a1.sinks.s1.sink.rollInterval=60
# File Roll Sink 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及对外开放的端口
a1.sources.r1.type=avro
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=file_roll
a1.sinks.s1.sink.dirextory=/home/tmp
# 单位 秒
a1.sinks.s1.sink.rollInterval=60
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# Avro Sink
是实现多级流动、扇出流 (1 到多)、扇入流 (多到 1) 的基础。
# Avro Sink 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及对外开放的端口
a1.sources.r1.type=avro
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=avro
# 指定为另一个 Flume 组成 多级流动,多级流动要求先启动下游Flume
a1.sinks.s1.hostname=node103
a1.sinks.s1.port=8888
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# HDFS Sink
此 sink 将事件写入到 Hadoop 分布式文件系统中。目前它支持创建文本文件和序列化文件。这两种格式都支持压缩。这些文件可以分卷,按照指定的时间或数量或事件的数量为基础。
HDFS 的目录路径可以包含将要由 HDFS 替换格式的转移序列用以生成存储事件的目录 / 文件名。
使用这个 sink 要求 hadoop 必须已经安装好,以便 Flume 可以通过 hadoop 提供的 jar 包与 HDFS 进行通信。
# HDFS Sink 配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1
a1.sinks=s1
# 指定source 的数据来源以及对外开放的端口
a1.sources.r1.type=avro
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 指定a1的channels基于内存
a1.channels.c1.type=memory
# 指定a1的sinks 输出到 hdfs
a1.sinks.s1.type=hdfs
# 输出地址 flume 会自动创建
a1.sinks.s1.hdfs.path=hdfs://node103:9000/flume
# 单位 秒,每隔1小时输出一次
a1.sinks.s1.hdfs.rollInterval=3600
# 根据文件大小来进行输出,0 不开启 单位 字节
a1.sinks.s1.hdfs.rollSize=0
# 根据内容行数来进行输出,0 不开启 单位 字节
a1.sinks.s1.hdfs.rollCount=0
# 输出文件的类型:SequenceFile(二进制) DataStream(文本)
a1.sinks.s1.hdfs.fileType=DataStream
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
出现此类错误,使用 find /-name guava* 名命令,找到 hadoop 的 guava jar,并覆盖 flume 的 guava jar
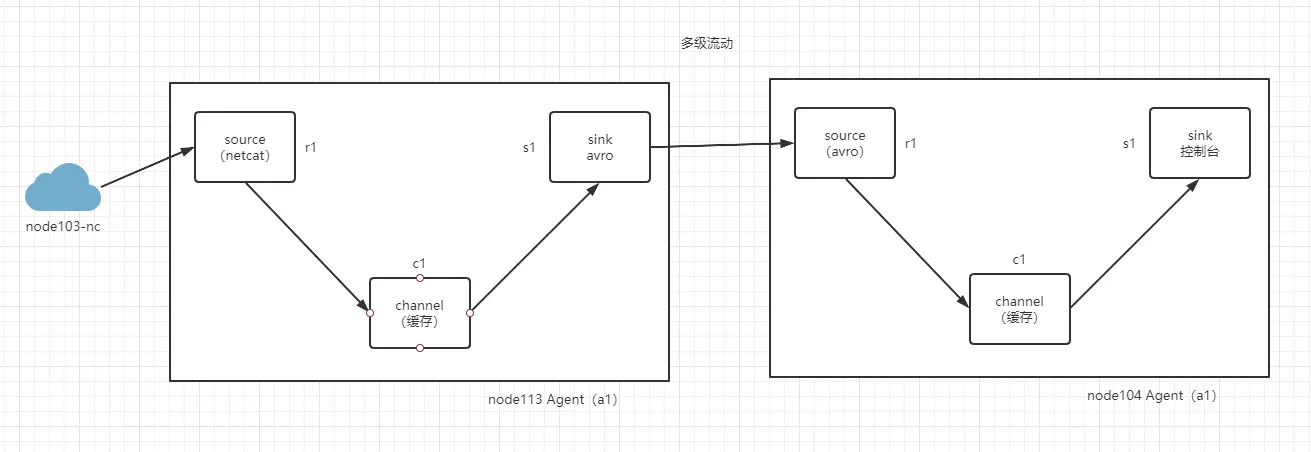
# 多级流动
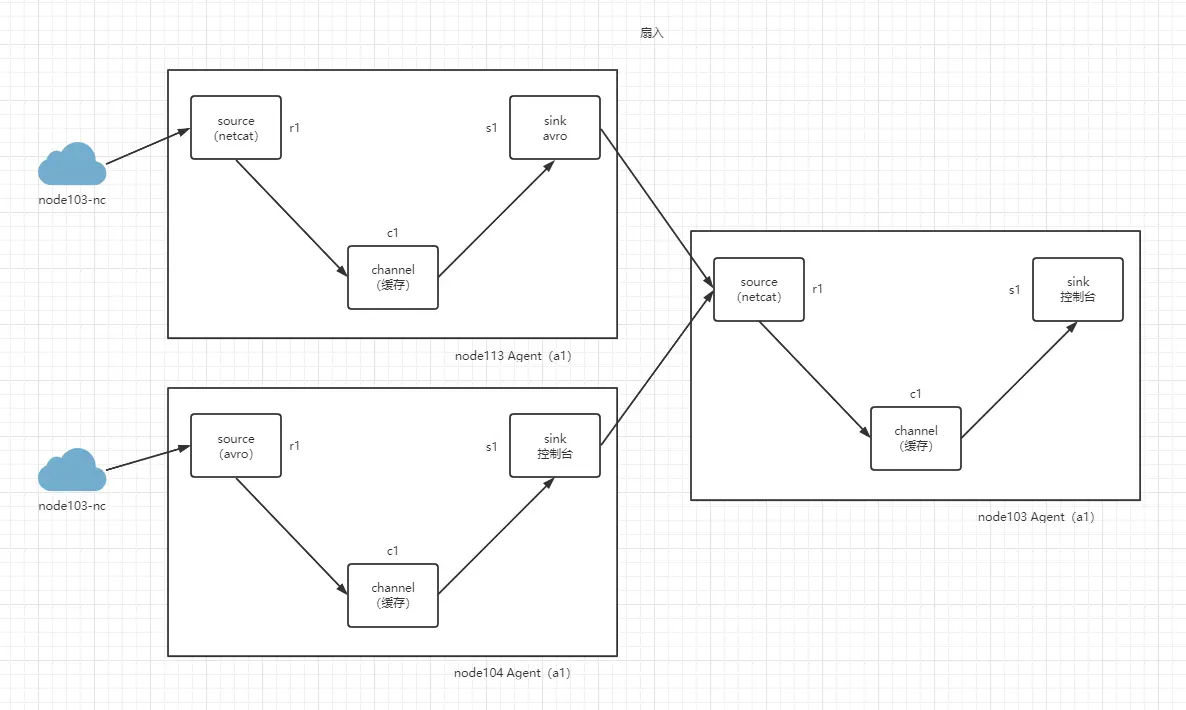
# 扇入流
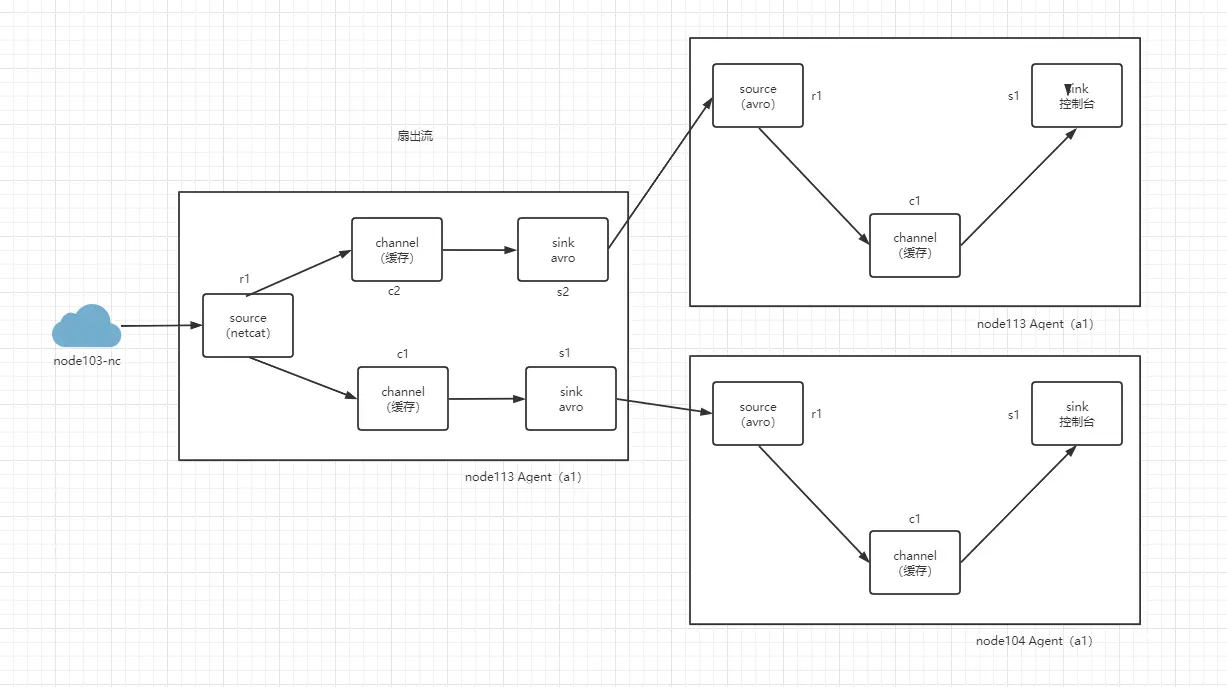
# 扇出流
# 核心配置
# a1 代表一个flume 给每个组件匿名
a1.sources=r1
a1.channels=c1 c2
a1.sinks=s1 s2
# 指定source 的数据来源以及对外开放的端口
a1.sources.r1.type=netcat
a1.sources.r1.bind=node113
a1.sources.r1.port=8888
# 指定a1的channels基于内存
a1.channels.c1.type=memory
a1.channels.c2.type=memory
# 指定a1的sinks 输出到控制台
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=node103
a1.sinks.s1.port=8888
a1.sinks.s2.type=avro
a1.sinks.s2.hostname=node104
a1.sinks.s2.port=8888
# 绑定a1 sources和channle 的关系
a1.sources.r1.channels=c1 c2
# 绑定a1 sinks 和 channel 的关系
a1.sinks.s1.channel=c1
a1.sinks.s2.channel=c2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28