 Flink Table API 和 Flink SQL
Flink Table API 和 Flink SQL
Table API 和 Flink SQL 是 flink 对批处理和流处理,提供了统一的上层 API。Table API 是一套内嵌在 Java 和 Scala 语言中的查询 API,它允许以非常直观的方式组合来自一些关系运算符的查询; Flink SQL 支持基于实现 SQL 标准的 Apache Calcite。
# 简单的用例
把一个流,转成 table api 来操作数据
依赖
<!-- table API -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.12.2</version>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
测试数据
1,1623051400,test data,1
2,1623051401,test data,1
3,1623051402,test data,1
1,1623051405,test data,3
2,1623051406,test data,3
3,1623051409,test data,3
1,1623051410,test data,5
2
3
4
5
6
7
用例代码
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1 读取数据
DataStream<String> dataStream = env.readTextFile("D:\\workspace\\spring\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt");
// 2 转换数据
DataStream<EventData> map = dataStream.map(i -> {
String[] strs = i.split(",");
return new EventData(
strs[0],
Long.valueOf(strs[1]),
String.valueOf((Long.valueOf(strs[1]) - 5)),
Integer.valueOf(strs[3])
);
});
// 3 创建表得执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 4 基于流创建一个table
Table table = tableEnv.fromDataStream(map);
// 5 调用table api进行转换操作
Table where = table
.filter($("id").isEqual("1"))
// 显示哪些列
.select($("id"),$("eventTime"));
// 6 执行sql
tableEnv.createTemporaryView("event_data",table); //基于table 创建一个匿名视图的表名 eventData
// 没有创建视图不能使用 表名称 eventData
String sql = "select id,eventTime from event_data where id = '2'";
Table sqlTable = tableEnv.sqlQuery(sql);
// 7 结果转换成行
tableEnv.toAppendStream(where, Row.class).print("where");
tableEnv.toAppendStream(sqlTable, Row.class).print("sql");
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
结果
where> 1,1623051400
sql> 2,1623051401
where> 1,1623051405
sql> 2,1623051406
where> 1,1623051410
2
3
4
5
# 基于批处理或流处理的环境配置
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 基于老版本流处理
EnvironmentSettings oldSettings = EnvironmentSettings.newInstance()
.inStreamingMode()// 流处理
//.inBatchMode()// 批处理
.useOldPlanner() // 老版本
//.useBlinkPlanner() // 新版本
.build();
StreamTableEnvironment oldStringTableEnv = StreamTableEnvironment.create(env, oldSettings);
// 基于老版本批处理
ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment oldBatchEnv = BatchTableEnvironment.create(batchEnv);
// 基于blink,blink 多了些功能以及架构上真正的批流统一,都是转换成了 DataStream,不像老版本还有 DateSet
EnvironmentSettings blinkSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment blinkStringTableEnv = StreamTableEnvironment.create(env, blinkSettings);
// 基于blink 批处理
EnvironmentSettings blinkBatchSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inBatchMode()
.build();
TableEnvironment blinkBatchTableEnv = TableEnvironment.create(blinkSettings);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 表(table)
TableEnvironment 可以注册目录 Catalog,并可以基于 Catalog 注册表,表是由一个 “标识符”(identifier)来指定的,由 3 部分组成: Catalog 名、数据库名、对象名。
表可以是常规的,也可以是虚拟的(视图,View),常规表一般可以用来描述外部数据,比如文件、数据库表或消息队列的数据,也可以直接从 DataStream 转换而来;视图(View)可以从现有的表中创建,通常是 table api 或者 sql 查询的一个结果集。
创建表的执行环境,需要将 flink 流处理的执行环境传入
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
TableEnvironment 是 flink 中集成 table api 和 sql 的核心概念,所有对表得操作都基于 TableEnvironment,包括注册 Catalog、在 Catalog 中注册表、执行 sql 查询、注册用户自定义函数(UDF)
# 优化用例
直接创建 TableEnvironment 来读取文件,并用 Table API 做查询。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 连接外部系统读取数据
String path = "D:\\workspace\\spring\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt";
// 类似于 source
tableEnv.connect(
new FileSystem().path(path)
// 类似于 split
).withFormat(
// 引入 flink csv 依赖,默认 , 分割
new Csv()
// 类似于 map 转换
).withSchema(
new Schema().field("id", DataTypes.STRING())
.field("eventTime", DataTypes.BIGINT())
.field("data", DataTypes.STRING())
.field("num", DataTypes.INT())
).createTemporaryTable("inputTable");
Table inputTable = tableEnv.from("inputTable");
inputTable.printSchema();
// 简单查询转换
Table resultTable = inputTable.select($("id"), $("eventTime"))
// 大于 1623051405
.filter($("eventTime").isGreater(1623051405))
// id = 1
.where($("id").isEqual("1"));
// 聚合统计
Table aggTable = inputTable.groupBy($("id"))
.select($("id").count().as("ct"),$("eventTime").avg().as("et"));
// sql写法
Table rt = tableEnv.sqlQuery("select id,eventTime from inputTable where eventTime > 1623051405 and id = '1'");
Table at = tableEnv.sqlQuery("select id,count(id) as ct,eventTime,avg(eventTime) as ev from inputTable group by id,eventTime");
//打印输出
tableEnv.toAppendStream(inputTable, Row.class).print("inputTable");
tableEnv.toAppendStream(resultTable, Row.class).print("resultTable");
// group by 操作会让数据发生改变,所以不是普通的 append 追加操作
tableEnv.toRetractStream(aggTable, Row.class).print("aggTable");
tableEnv.toAppendStream(rt, Row.class).print("rt");
tableEnv.toRetractStream(at, Row.class).print("at");
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
toAppendStream doesn't support consuming update changes which is produced by node GroupAggregate (groupBy=[id], select=[id, COUNT (id) AS EXPR$0, AVG (eventTime) AS EXPR$1]) 这句话的意思是 使用到 groupy by 有 count 操作等都是值更新操作,不是 append 追加操作结果,所以输出 toRetractStream ,toRetractStream 是撤回流,会把上一次结果撤回改成 false,输出新的结果 true。
# 用例数据输出到另一个文件
对于数据的写入在某些是有要求的,聚合操作的结果集就没办法写到文件,聚合操作会输出两条结果,一个上一次结果的撤回 false,一次新结果的输出 true,是没办法追加到文件系统的。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 连接外部系统读取数据
String path = "D:\\workspace\\spring\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt";
// 类似于 source
tableEnv.connect(
new FileSystem().path(path)
// 类似于 split
).withFormat(
// 引入 flink csv 依赖,默认 , 分割
new Csv()
// 类似于 map 转换
).withSchema(
new Schema().field("id", DataTypes.STRING())
.field("eventTime", DataTypes.BIGINT())
.field("data", DataTypes.STRING())
.field("num", DataTypes.INT())
).createTemporaryTable("inputTable");
Table inputTable = tableEnv.from("inputTable");
inputTable.printSchema();
// 简单查询转换
Table resultTable = inputTable.select($("id"), $("eventTime"))
// 大于 1623051405
.filter($("eventTime").isGreater(1623051405))
// id = 1
.where($("id").isEqual("1"));
// 聚合统计
Table aggTable = inputTable.groupBy($("id"))
.select($("id").count().as("ct"),$("eventTime").avg().as("et"));
// 输出到另一个文件
String outPutPath = "D:\\workspace\\spring\\middleware\\flink\\flink-test\\src\\main\\resources\\out.txt";
// 类似于 source
tableEnv.connect(
new FileSystem().path(outPutPath)
// 类似于 split
).withFormat(
// 引入 flink csv 依赖,默认 , 分割
new Csv()
// 类似于 map 转换
).withSchema(
new Schema().field("id", DataTypes.STRING())
.field("eventTime", DataTypes.BIGINT())
).createTemporaryTable("outPutTable");
// 写道另一个文件,如果是 aggTable 是不能写入到文件的
resultTable.executeInsert("outPutTable",false);
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# flink table api 之 kafka
KafkaTableSinkBase 实现的是 AppendStreamTableSink 所以也没办法把聚合数据写进去,就像以上 CSVTableSInkBase 也是实现了 AppendStreamTableSink ,都无法去写入聚合的数据。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 建立源
tableEnv.connect(
// 需要引入flink-connector-kafka_2.12<
new Kafka()
// kafka 版本
.version("0.12")
.topic("topic_consumer")
.property("zookeeper.connect","localhost:2181")
.property("bootstrap.servers","localhost:9092")
).withFormat(
new Csv()
).withSchema(
new Schema().field("id", DataTypes.STRING())
.field("eventTime", DataTypes.BIGINT())
.field("data", DataTypes.STRING())
.field("num", DataTypes.INT())
).createTemporaryTable("inputTable");
// 简单转换
Table inputTable = tableEnv.from("inputTable");
// 输出kafka
tableEnv.connect(
// 需要引入flink-connector-kafka_2.12<
new Kafka()
// kafka 版本
.version("0.12")
.topic("topic_producer")
.property("zookeeper.connect","localhost:2181")
.property("bootstrap.servers","localhost:9092")
).withFormat(
new Csv()
).withSchema(
new Schema().field("id", DataTypes.STRING())
.field("eventTime", DataTypes.BIGINT())
.field("data", DataTypes.STRING())
.field("num", DataTypes.INT())
).createTemporaryTable("outPutTable");
// KafkaTableSinkBase 实现的是 AppendStreamTableSink 所以也没办法把聚合数据写进去
inputTable.executeInsert("outPutTable");
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
对于流式查询,需要声明如何在表和外部连接器之间执行转换,与外部系统交换的消息类型,由更新模式(update mode)指定。
- 追加(Append)
表制作插入操作,和外部连接器只交换插入(insert)消息 - 撤回(Retract)
表和外部连接器交换添加(Add)和撤回(Retract)消息。插入操作(insert)编码为 Add 消息;删除(Delete)编码为 Retract 消息;更新(Upsert)编码为上一条的 Retract 和吓一跳的 Add 消息。 - 更新插入(Upsert)
更新和插入都被编码为 Upsert 消息;删除编码为 Delet 消息
kafka 和 文本不支持,但 支持 ES(ElasticSearchUpsertTableSinkBase 类)、Mysql(需要引入 flink-jdbc_2.12)
# 将 Table 转换成 DataStream
表可以转换为 DataStream 或 DataSet,这样自定义流处理或批处理程序就可以继续在 Table API 或 SQL 查询的结果上运行了。将表转换为 DataStream 或 DataSet 时,需要指定生成的数据类型,即要将表的每一行转换成指定数据类型。表作为流式查询的结果,是动态更新的,转换有两种转换模式:追加(Append)模式和撤回(Retract)模式
追加模式,用于表只会被插入(insert)操作场景
DataStream<Row> resultStream = tableEnv.toAppendStream(resultTable,Row.class)
撤回模式,用于任何场景。有些类似于更新模式中 Retract 模式,他只有 insert 和 Delete 两类操作。得到的数据会增加一个 Boolean 类型的标识位(返回的第一个字段),用它来表示到底是新增的数据(insert),还是被删除的数据(Delete)
DataStream<Tuple2<Boolean,Row>> aggResultStream = tableEnv.toRetractStream(aggResultTable,Row.class)
流转换成表
// 3 创建表得执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 4 基于流创建一个table
Table table = tableEnv.fromDataStream(map);
2
3
4
默认转换后的 Table schema 和 DataStream 中的字段定义一一对应,也可以单独指定出来
Table table = tableEnv.fromDataStream(map,"id,eventTime as et,data,num");
基于 DataStream 创建临时视图
tableEnv.createTemporaryView("view_name",dataStream);
tableEnv.createTemporaryView("view_name",dataStream,"id,eventTime as et,data,num");
2
基于 Table 创建临时视图
tableEnv.createTemporaryView("view_name",table);
查看执行计划
tableEnv.explain(resultTable);
# 动态表(Dynamic Tables)
动态表是 Flink 对流数据的 Table API 和 SQL 支持的核心概念,它表示批处理数据的静态表不同,动态表是随时间变化的。
动态表可以像静态的批处理一样进行查询,查询一个动态表会产生持续查询(Continuous Query),连续查询永远不会终止,并会生成另一个动态表,查询会不断更新其动态结果表,以反映其动态输入表上的更改。
流式表查询的处理过程:1. 流被转换为动态表;2. 对动态表计算连续查询,生成新的动态表;3. 生成的动态表被转换回流

一常规数据库表一样,动态表可以通过插入(Insert)、更新(Update)和删除(Delete)更改,进行持续的修改,将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码:追加流(Append-only)、撤回流(Retract)、更新插入流(Upsert)
# 时间特性(Time Attributes)
基于时间的操作(比如 Table API 和 SQL 中窗口操作),需要定义相关的时间语义和时间数据来源的信息。
Table 可以提供一个逻辑上的时间字段,用于在表处理程序中,指示时间和访问相应的时间戳。
时间属性,可以是每个表 schema 的一部分。一旦定义了时间属性,他就可以作为一个字段引用,并且可以在基于时间的操作中使用。时间属性的行为类似于常规的时间戳,可以访问,并且进行计算。
# 定义处理时间(Processing Time)
处理时间语义下,允许表处理程序根据机器的本地时间生成成果。它是时间的最简单概念。它既不需要提取时间戳,也不需要生成 watermark。
由 DataStream 转换成表时指定。在定义 Schema 期间,可以使用 .proctime,指定字段名定义处理时间字段。这个 proctime 属性只能通过附加逻辑字段,来扩展物理 schema。因此,只能 schema 定义的末尾定义它。
Table table = tavleEnv.fromDataStream(dataStream,"id,eventTime,data,num.pt.proctime");
connect 中使用
.withSchema(
new Schema().field("id", DataTypes.STRING())
.field("eventTime", DataTypes.BIGINT())
.field("data", DataTypes.STRING())
.field("num", DataTypes.INT())
.field("pt", DataTypes.TIMESTAMP(3))
.proctime()
2
3
4
5
6
7
mysql 中定义,PROCTIME 只有 blink 中支持,要引入 blink api
String sinkDDL = "create table dataTable( "+
"id varchar(20) not null, "+
"eventTime bigint, "+
"data varchar(30), "+
"num int, "+
"pt as PROCTIME(), "+
") with ( "+
" 'connector.type' = 'filesystem' "+
" 'connector.path' = '/test.tct' "+
" 'format.type' = 'csv' ";
tableEnv.sqlUpdate(sinkDDL)
2
3
4
5
6
7
8
9
10
11
# 定义事件事件(Event Time)
事件时间语义,允许表处理程序根据每个记录中包含的时间生成结果。这样即使在有序乱序事件或延迟事件时,也可以获得正确的结果。
为了处理无须事件,并区分流中的准时和迟到事件;Flink 需要从事件数据中,提取时间戳,并用来推进事件时间的进展。
定义事件事件,同样有三种方法:由 DataStream 转换成表时指定;定义 Table Schema 时指定;在创建表的 DDL 中定义。
// 将 DataStream 转换位Table,并指定时间字段
Table table = tableEnv.fromDataStream(dataStream,"id,eventTime.rowtime,data,num");
// 或者,直接追加时间字段
Table table = tableEnv.fromDataStream(dataStream,"id,eventTime,data,num,rt.rowtime");
2
3
4
5
connect 中定义
.withSchema(
new Schema().field("id", DataTypes.STRING())
.field("eventTime", DataTypes.BIGINT())
.field("data", DataTypes.STRING())
.field("num", DataTypes.INT())
.rowtime(
new Rowtime()
// 从字段中提取时间戳
.timestampsFromField("eventTime")
// waternark 延迟1s
.watermarksPeriodicBounded(1000)
)
)
2
3
4
5
6
7
8
9
10
11
12
13
sql ddl 定义,需要 blink api
String sinkDDL = "create table dataTable( "+
"id varchar(20) not null, "+
"eventTime bigint, "+
"data varchar(30), "+
"num int, "+
"rt as TO_TIMESTAMP( FROM_UNIXTIME(eventTime) ), "+
"watermark for rt as rt - interval '1' second "+
") with ( "+
" 'connector.type' = 'filesystem' "+
" 'connector.path' = '/test.tct' "+
" 'format.type' = 'csv' ";
tableEnv.sqlUpdate(sinkDDL)
2
3
4
5
6
7
8
9
10
11
12
# 窗口
时间语义,要配合敞口操作才能发挥作用,在 Table API 和 SQL 中,主要有两种装口:group Windows(分组窗口),根据时间或行计数间隔,将行聚合到有限的组(Group)中,并对每个组的数据执行一次聚合函数;Over Windows,针对每个输入行,计算相邻行范围内的聚合。
# Group Windows
Group Windows 时使用 window 定义的,并且必须又 as 子句指定一个别名。为了按窗口进行分组,窗口的别名必须在 greop by 子句中,像常规的分组字段一样引用。
Table aggTable = inputTable
.window([w:GroupWindow] as "w") // 定义窗口,别名为 w
.groupBy("w,a") // 按照字段a和窗口 w分组
.select("a,b.sum"); // 聚合
2
3
4
Table API 提供了一组具有特定语义的预定义 Window 类,这些类会被转换为底层 DataStream 或 DataSet 的窗口操作。
滚动窗口
// 开了一个10分钟的滚动窗口,指定一个字段 rowtime,as 别名
.window(Tumble.over($("10.minutes")).on($("rowtime")).as("w"))
// 处理时间
.window(Tumble.over($("10.minutes")).on($("proctime")).as("w"))
// 计数窗口 10.rows 10行
.window(Tumble.over($("10.rows")).on($("proctime")).as("w"))
2
3
4
5
6
滑动窗口
// 事件事件滑动窗口,长度是10分钟,5分钟滑动一次
.window(Slide.over($("10.minutes")).every($("5.minutes")).on("rowtime").as("w"))
// 处理时间滑动窗口
.window(Slide.over($("10.minutes")).every($("5.minutes")).on("proctime").as("w"))
// 计数滑动窗口
.window(Slide.over($("10.rows")).every($("5.rows")).on("proctime").as("w"))
2
3
4
5
6
会话窗口
// 最小间隔时间
.window(Session.withGap($("10.minutes")).on("rowtime").as("w"))
.window(Session.withGap($("10.minutes")).on("proctime").as("w"))
2
3
sql 中的定义,在查询的 group by 子句中使用
// 定义一个滚动窗口,第一个参数是时间字段,第二个参数是长度
TUMBLE(time_attr,interval)
// 定义一个滑动窗口,第一个参数是时间字段,第二个参数是滑动长度,第三个是窗口长度
HOP(time_attr,interval,interval)
// 定义一个会话窗口,第一个参数是时间字段,第二个参数窗口间隔
SESSION(time_attr,interval)
2
3
4
5
6
# 基于 ddl 开窗代码演示
ddl 更多操作 (opens new window),1.12 中不推荐 connect,推荐使用 ddl 来操作。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 连接外部系统读取数据
String path = "D:\\workspace\\spring\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt";
// 类似于 source
tableEnv.connect(
new FileSystem().path(path)
// 类似于 split
).withFormat(
// 引入 flink csv 依赖,默认 , 分割
new Csv()
// 类似于 map 转换
).withSchema(
new Schema().field("id", DataTypes.STRING())
.field("data", DataTypes.STRING())
.field("num", DataTypes.INT())
.field("eventTime", DataTypes.TIMESTAMP(3))
).createTemporaryTable("inputTable");
String ddl = "CREATE TABLE MyUserTable ( " +
" id STRING, " +
" eventTime BIGINT, " +
" data STRING, " +
" num INTEGER, " +
" rt as TO_TIMESTAMP( FROM_UNIXTIME(eventTime) ), " +
" watermark for rt as rt - interval '5' second " +
") WITH ( " +
" 'connector.type' = 'filesystem'," +
" 'connector.path' = 'D:\\workspace\\spring\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt', " +
" 'format.type' = 'csv' " +
")";
tableEnv.executeSql(ddl);
String sql = "select " +
"count(id) as ct,id,tumble_start(rt,interval '15' second) as st,tumble_end(rt,interval '15' second) as ed " +
"from MyUserTable " +
"group by id,tumble(rt,interval '15' second) ";
// 第一种方式
Table table = tableEnv.sqlQuery(sql);
tableEnv.toRetractStream(table, Row.class).print("sql1");
// 第二种方式 打印sqk结构
tableEnv.executeSql(sql).print();
// 第三种方式 使用api
Table myUserTable = tableEnv.from("MyUserTable");
Table select = myUserTable.window(Tumble.over(lit(15).seconds()).on($("rt")).as("w"))
.groupBy($("id"), $("w"))
.select($("id").count().as("ct"),$("w").start().as("st"),$("w").end().as("ed"));
tableEnv.toAppendStream(select, Row.class).print("api");
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
# Over Windows
Over Window 聚合是标准 SQL 中已有得(over 子句),可以在查询的 SELECT 子句中定义;Over Window 聚合,会针对每个输入行,计算相邻行范围内的聚合;Over Window 使用 windows (w:overwindows*) 子句定义,并在 select () 方法中通过别名来引用。
table table = input.window([e:OverWindow] as "w").select("a,b.sum over w,c.min over w");
Table API 提供了 Over 类,来配置 Over 窗口的属性。
# 无界 Over Windows
可以在事件事件或处理事件,以及指定为时间间隔、或行计数的范围内,定义 Over Window,无界的 over window 是使用常量指定的。
// 无界的事件时间
.window(Over.partitionBy("a").orderBy("rowtime").preceding(UNBOUNDED_RABGE).as("w"))
// 无界的处理时间
.window(Over.partitionBy("a").orderBy("proctime").preceding(UNBOUNDED_RABGE).as("w"))
// 无界的事件时间
.window(Over.partitionBy("a").orderBy("rowtime").preceding(UNBOUNDED_RABGE).as("w"))
// 无界的处理时间
.window(Over.partitionBy("a").orderBy("proctime").preceding(UNBOUNDED_ROW).as("w"))
.window(Over.partitionBy("a").orderBy("rowtime").preceding(UNBOUNDED_ROW).as("w"))
2
3
4
5
6
7
8
9
# 有界 Over Windows
// 有界的事件时间
.window(Over.partitionBy("a").orderBy("rowtime").preceding("1.minutes").as("w"))
// 有界的处理时间
.window(Over.partitionBy("a").orderBy("proctime").preceding("1.minutes").as("w"))
.window(Over.partitionBy("a").orderBy("rowtime").preceding("10.rows").as("w"))
.window(Over.partitionBy("a").orderBy("proctime").preceding("10.rows").as("w"))
2
3
4
5
6
# sql 中的 Over Window
用 Over 做窗口聚合时,所有聚合必须在同一窗口上定义,也就是说必须是相同的分区、排序和范围;目前仅支持在当前行范围之前的窗口;Order By 必须在单一的时间属性上指定。
select count(id) over(
partition by id
order by eventTime
// 当前行以及前两行
row between 2 preceding and current row
) from table
2
3
4
5
6
# 代码演示
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 连接外部系统读取数据
String path = "D:\\workspace\\spring\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt";
// 类似于 source
tableEnv.connect(
new FileSystem().path(path)
// 类似于 split
).withFormat(
// 引入 flink csv 依赖,默认 , 分割
new Csv()
// 类似于 map 转换
).withSchema(
new Schema().field("id", DataTypes.STRING())
.field("data", DataTypes.STRING())
.field("num", DataTypes.INT())
.field("eventTime", DataTypes.TIMESTAMP(3))
).createTemporaryTable("inputTable");
String ddl = "CREATE TABLE MyUserTable ( " +
" id STRING, " +
" eventTime BIGINT, " +
" data STRING, " +
" num INTEGER, " +
" rt as TO_TIMESTAMP( FROM_UNIXTIME(eventTime) ), " +
" watermark for rt as rt - interval '5' second " +
") WITH ( " +
" 'connector.type' = 'filesystem'," +
" 'connector.path' = 'D:\\workspace\\spring\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt', " +
" 'format.type' = 'csv' " +
")";
tableEnv.executeSql(ddl);
Table myUserTable = tableEnv.from("MyUserTable");
Table select = myUserTable.window(Over.partitionBy($("id")).orderBy($("rt")).preceding(rowInterval(2L)).as("w"))
.select("id,rt,id.count over w,num.sum over w");
String sql = "select id,rt,count(id) over w,sum(num) over w "+
" from MyUserTable "+
" window w as ( partition by id order by rt rows between 2 preceding and current row ) ";
Table Table = tableEnv.sqlQuery(sql);
tableEnv.executeSql(sql).print();
tableEnv.toAppendStream(Table, Row.class).print("sql");
tableEnv.toRetractStream(select, Row.class).print("api");
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
数据
1,1623051400,test data,1
2,1623051401,test data,3
3,1623051402,test data,5
1,1623051405,test data,7
2,1623051406,test data,9
3,1623051409,test data,2
1,1623051415,test data,4
2,1623051416,test data,6
3,1623051417,test data,7
1,1623051418,test data,9
2,1623051419,test data,3
3,1623051420,test data,2
1,1623051421,test data,2
1,1623051422,test data,3
1,1623051423,test data,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
结果
+----+--------------------------------+-------------------------+----------------------+-------------+
| op | id | rt | EXPR$2 | EXPR$3 |
+----+--------------------------------+-------------------------+----------------------+-------------+
| +I | 1 | 2021-06-07T15:36:40 | 1 | 1 |
| +I | 2 | 2021-06-07T15:36:41 | 1 | 3 |
| +I | 3 | 2021-06-07T15:36:42 | 1 | 5 |
| +I | 1 | 2021-06-07T15:36:45 | 2 | 8 |
| +I | 2 | 2021-06-07T15:36:46 | 2 | 12 |
| +I | 3 | 2021-06-07T15:36:49 | 2 | 7 |
| +I | 1 | 2021-06-07T15:36:55 | 3 | 12 |
| +I | 2 | 2021-06-07T15:36:56 | 3 | 18 |
| +I | 3 | 2021-06-07T15:36:57 | 3 | 14 |
| +I | 1 | 2021-06-07T15:36:58 | 3 | 20 |
| +I | 2 | 2021-06-07T15:36:59 | 3 | 18 |
| +I | 3 | 2021-06-07T15:37 | 3 | 11 |
| +I | 1 | 2021-06-07T15:37:01 | 3 | 15 |
| +I | 1 | 2021-06-07T15:37:02 | 3 | 14 |
| +I | 1 | 2021-06-07T15:37:03 | 3 | 6 |
+----+--------------------------------+-------------------------+----------------------+-------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
partition by id order by rt rows between 2 preceding and current row, 是以 id 分组,计算当前行的前 2 行,也就是一共 3 行,的值的计算。第一条数据进来,对于他来说就是当前行,前两行没有。
更详细的 over 概念可以看这篇文章 (opens new window)
# 函数
Flink Table API 和 SQL 为用户提供了一组用于数据转换的内置函数,sql 中支持的很多函数,Table API 和 SQL 都已经做了实现。
比较函数 逻辑函数 算数函数
SQL: SQL: SQL:
value1 = value2 boolean1 or boolean2 numeric1+numeric2
value1 > value2 boolean1 is false power(numeric1,numeric2)
not boolean
Table API: Table API:
ANY1 === ANY2 boolean1 || boolean2 numeric1+numeric2
ANY1 > ANY2 boolean.isFalse numeric1.power(numeric2)
!boolean
字符串函数 时间函数 聚合函数
SQL: SQL: SQL:
string1 || string2 date string count(*)
upper(string) timestamp string sum(expression)
char_length(string) current_time rank()
interval string range row_number()
Table API: Table API: Table API:
string1 + string2 string.toDate field.count
string.upperCase() string.toTimestamp field.sum
string.charLength() currentTime()
numeric.days
numeric.minutes
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 用户自定义函数(UDF)
用户自定义函数(User defined Functions,UDF)是一个重要得特性,他们显著地扩展了查询的表达能力。
在大多数情况下,用户定义的函数必须先注册,然后才能在查询中使用;函数通过调用 registerFunctionn () 方法在 TableEnvironment 的函数目录中,这样 Table API 或 SQL 解析器就可以识别并正确地解释它。
# 标量函数(Scalar Functions)
用户自定义的标量函数,可以将 0、1 或多个标量值,映射到新的标量值;为了定义标量函数,必须在 org.apache.flink.table.functions 中扩展基类 Scalar Function,并实现(一个或多个)求值(eval)方法。简单来说,就是把一个表的字段传入解析,列中可以显示这个被解析的字段的结果。
标量函数的行为由求值方法决定,求值方法必须公开声明并名命为 eval。
public static void main(String[] args) {
// 执行环境创建
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取数据
DataStream<String> dataStream = env.readTextFile("D:\\workspace\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt");
// 转换数据
DataStream<EventData> map = dataStream.map(i -> {
String[] strs = i.split(",");
return new EventData(
strs[0],
Long.valueOf(strs[1]),
String.valueOf((Long.valueOf(strs[1]) - 5)),
Integer.valueOf(strs[3])
);
});
// 将流转换成表
Table dataTable = tableEnv.fromDataStream(map, $("id"), $("eventTime"), $("data"), $("num"));
HashCode hashCode = new HashCode(20);
// 创建一个临时UDF 注册到环境中
tableEnv.createTemporarySystemFunction("hashCode",hashCode);
// table api 使用自定义函数
dataTable.select($("id"),call("hashCode",$("id"))).execute().print();
tableEnv.createTemporaryView("event_data",map);
tableEnv.sqlQuery("select id,hashCode(id) from event_data").execute().print();
}
public static class HashCode extends ScalarFunction{
private int factor = 10;
// 可以定义构造函数来传标准配置
public HashCode(int factor){
this.factor = factor;
}
// 必须是 public 返回类型和参数类型随便定,但方法名必须交 eval
public int eval(String id){
return id.hashCode() % factor;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 表函数(Table Functions)
用户定义的表函数,也可以将 0、1 或多个标量值作为输入参数;与标量函数不同的是,它可以返回任意数量的行为作为输出,而不是单个值。简单来说就是把表的字段传入解析,一行变多行。
为了定义一个表函数,必须扩展 org.apache.flink.table.functions 中的基类 TableFuntion 并实现 (一个或多个) 求值方法;表函数的行为由其求值方法决定,求值方法必须是 public 的,并命名为 eval。
public static void main(String[] args) {
// 执行环境创建
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取数据
DataStream<String> dataStream = env.readTextFile("D:\\workspace\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt");
// 转换数据
DataStream<EventData> map = dataStream.map(i -> {
String[] strs = i.split(",");
return new EventData(
strs[0],
Long.valueOf(strs[1]),
strs[2],
Integer.valueOf(strs[3])
);
});
// 将流转换成表
Table dataTable = tableEnv.fromDataStream(map, $("id"), $("eventTime"), $("data"), $("num"));
Split split = new Split(" ");
// 创建一个临时UDF 注册到环境中
tableEnv.createTemporarySystemFunction("split",split);
// table api 使用自定义函数
dataTable.joinLateral(call("split",$("data")).as("word","length"))
.select($("id"),$("data"),$("word"),$("length"))
.execute()
.print();
tableEnv.createTemporaryView("event_data",map);
tableEnv.sqlQuery("select id,data,word,length from event_data,lateral table(split(data)) as aplitid(word,length)")
.execute()
.print();
}
public static class Split extends TableFunction<Tuple2<String,Integer>> {
private String mark = ",";
// 可以定义构造函数来传标准配置
public Split(String mark){
this.mark = mark;
}
// 必须是 public 返回类型和参数类型随便定,但方法名必须交 eval
public void eval(String data){
for(String str : data.split(mark)) {
collect(new Tuple2<String, Integer>(str,str.length()));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 聚合函数(Aggregate Functions)
用户定义聚合函数(User Defined Aggregate Functions,UDAGGs)可以把一个表中的数据,聚合成一个标量值;用户定义的聚合函数,是通过继承 AggregateFunction 抽象类实现的。对表分组聚合,相同组的会聚合成一条数据。
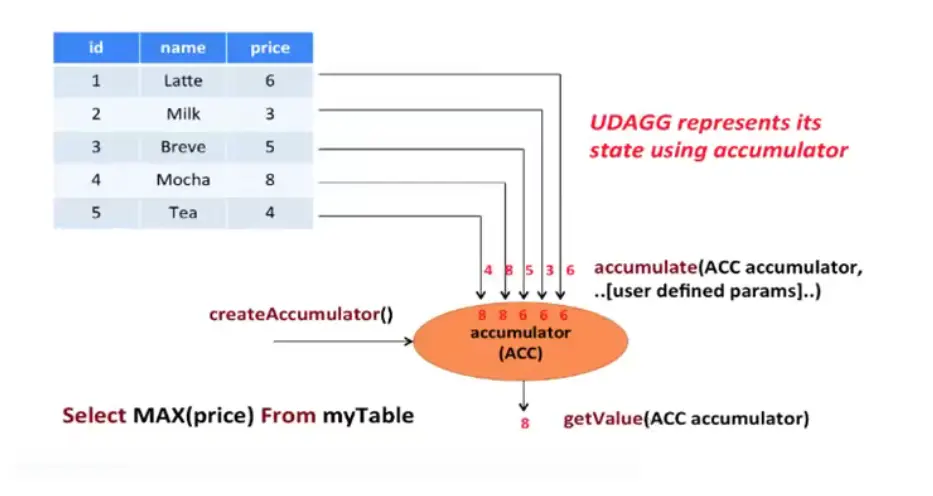
AggregateFunction 要求必须实现的方法:createAccumulator ()、Accumulate ()、getValue ();
AggregateFunction 的工作原理:首先,它需要一个累加器(Accumulate),用来保存聚合中间结果的数据结构,可以通过调用 createAccumulator () 方法创建空累加器;随后,对每个输入行调用函数的 Accumulate () 方法来更新累加器;处理完所有行,将调用函数的 getValue () 方法来计算并返回最终结果。
public static void main(String[] args) {
// 执行环境创建
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取数据
DataStream<String> dataStream = env.readTextFile("D:\\workspace\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt");
// 转换数据
DataStream<EventData> map = dataStream.map(i -> {
String[] strs = i.split(",");
return new EventData(
strs[0],
Long.valueOf(strs[1]),
strs[2],
Integer.valueOf(strs[3])
);
});
// 将流转换成表
Table dataTable = tableEnv.fromDataStream(map, $("id"), $("eventTime"), $("data"), $("num"));
Avg avg = new Avg();
// 创建一个临时UDF 注册到环境中
tableEnv.createTemporarySystemFunction("avg_0",avg);
// table api 使用自定义函数
dataTable.groupBy($("id"))
.select($("id"),call("avg_0",$("num").as("avg_num")))
.execute()
.print();
tableEnv.createTemporaryView("event_data",map);
tableEnv.sqlQuery("select id,avg_0(num) as avg_num from event_data group by id ")
.execute()
.print();
}
// 求 num 平均值
public static class Avg extends AggregateFunction<Double,Tuple2<Double,Integer>> {
// 求平均值
@Override
public Double getValue(Tuple2<Double, Integer> doubleIntegerTuple2) {
return doubleIntegerTuple2.f0 / doubleIntegerTuple2.f1;
}
// 初始化状态
@Override
public Tuple2<Double, Integer> createAccumulator() {
return new Tuple2<>(0.0,0);
}
// 必须实现 accumulate 方法,来数据之后更新状态,acc 为当前状态,tmp 为输入数据
public void accumulate(Tuple2<Double, Integer> acc,Double tmp){
acc.f0 += tmp;
acc.f1 += 1;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# 表聚合函数
表聚合函数 和 聚合函数的区别是,对表分组聚合,相同组的会聚合成多行多列的结果表;表聚合函数通过继承 TableAggregateFunction 抽象类来实现的。
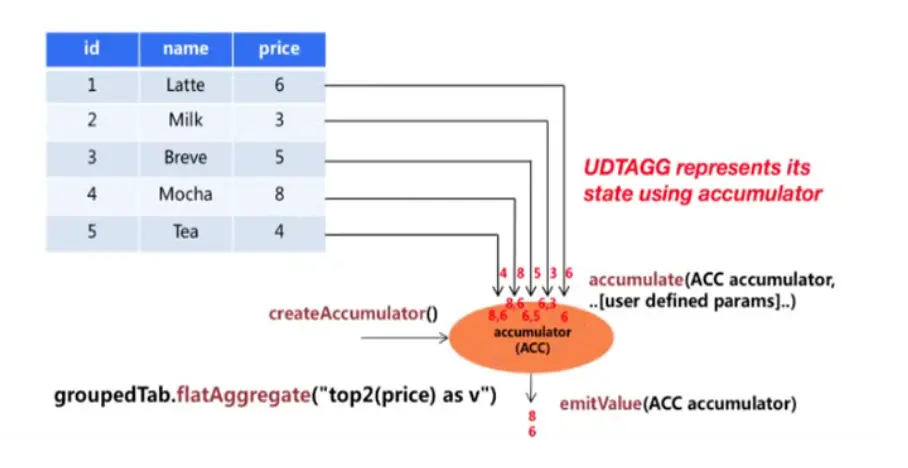
public static void main(String[] args) {
// 执行环境创建
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取数据
DataStream<String> dataStream = env.readTextFile("D:\\workspace\\middleware\\flink\\flink-test\\src\\main\\resources\\hello.txt");
// 转换数据
DataStream<EventData> map = dataStream.map(i -> {
String[] strs = i.split(",");
return new EventData(
strs[0],
Long.valueOf(strs[1]),
strs[2],
Integer.valueOf(strs[3])
);
});
// 将流转换成表
Table dataTable = tableEnv.fromDataStream(map, $("id"), $("eventTime"), $("data"), $("num"));
// Top2 top2 = new Top2();
// 创建一个临时UDF 注册到环境中
// tableEnv.createTemporarySystemFunction("top2",top2);
tableEnv.registerFunction("top2", new Top2());
// table api 使用自定义函数
dataTable.groupBy($("id"))
.flatAggregate("top2(num) as (TOP1, TOP2)")
.select($("id"),$("TOP1"),$("TOP2"))
.execute()
.print();
}
// 求 num 平均值
// 第一个泛型是输出,第二个泛型是状态
public static class Top2 extends TableAggregateFunction<Tuple2<Integer,Integer>,Tuple2<Integer,Integer>> {
// 输出
public void emitValue(Tuple2<Integer, Integer> acc, Collector<Tuple2<Integer, Integer>> out){
out.collect(acc);
}
// 初始化状态
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return new Tuple2<>(0,0);
}
// 必须实现 accumulate 方法,来数据之后更新状态,acc 为当前状态,tmp 为输入数据
public void accumulate(Tuple2<Integer, Integer> acc,Integer tmp){
// 如果 tem 大于 f0,且 f0 > f1 那么
// 三个数降序 取前两个
List<Integer> doubles = Arrays
.asList(acc.f0, acc.f1,tmp)
.stream()
.sorted(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1,o2);
}
}.reversed())
.collect(Collectors.toList());
acc.f0 = doubles.get(0);
acc.f1 = doubles.get(1);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69