 Flink 容错,检查点,保存点
Flink 容错,检查点,保存点
# 一致性检查点(checkpoint)
flink 故障恢复机制的核心,就是应用状态的一致性检查点。有状态应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点(所有任务都刚好处理完同一个数据的时间点),应该是所有任务都恰好处理完一个相同的输入数据的时候。
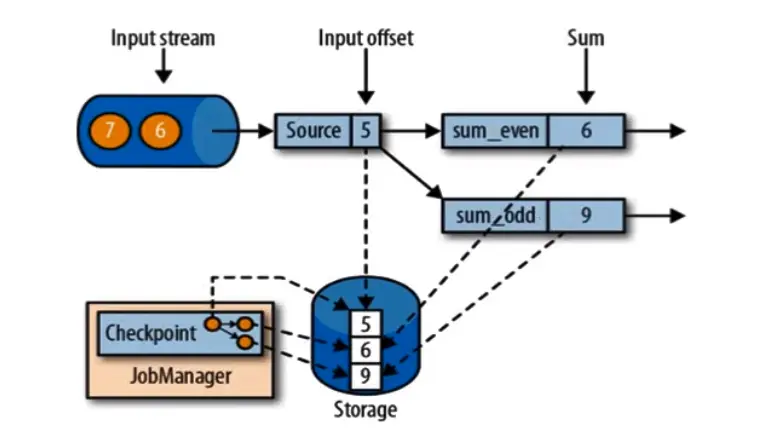
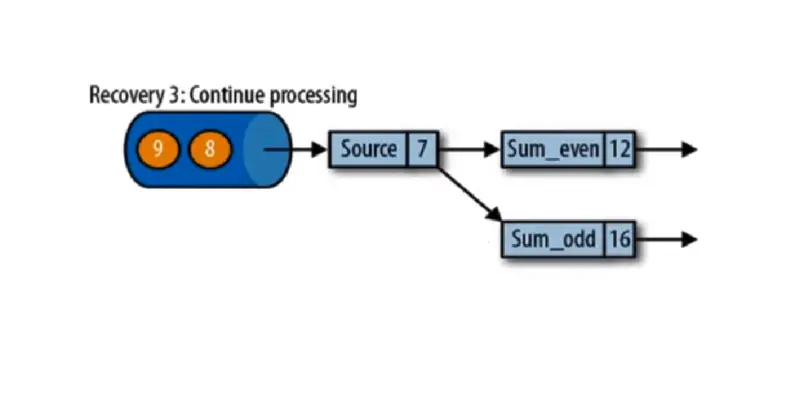
input stream = [1,2,3,4,5,6,7,8,9],sum_event = 求偶数和,sum_odd = 求奇数和,类似于于 source 到来的数据后 keyBy (data%2)。如果说 5 还没有被分配到 sum_odd 任务中,其实 sum_odd 应该还是 4=1+3,此时 5 在路上,source=6,突然挂掉,那么,storage 记录的要么是 source=6 sum_event =6 sum_odd =9,要么是 source=5 sum_event =6 sum_odd =4,它必须记录的是任务处理完成的状态,不是说 5 在路上没了你存的是 6 6 4,那么恢复肯定是错的,不如重新算一遍。
# 从检查点恢复状态
在执行应用程序期间,Flink 会定期保存状态的一致检查点,如果发生故障,Flink 将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程。
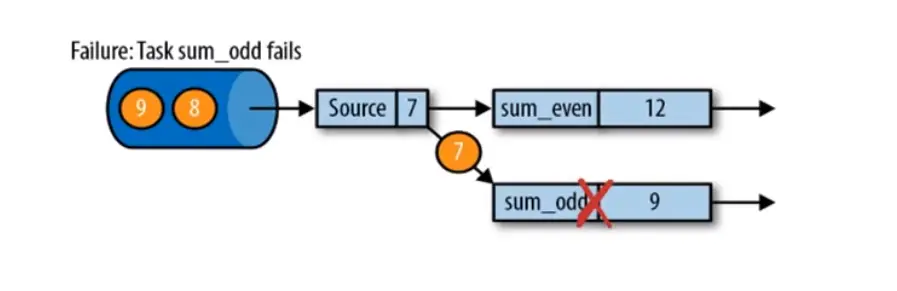
遇到故障之后,第一步就是重启应用,重启后的应用状态是空的,除非代码中有写死的状态。
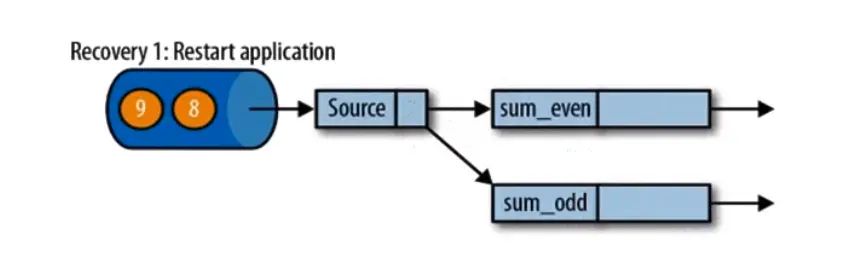
第二步是从 checkpoint 中读取状态,将状态重置。source 会记录消费数据的偏移量,从 storage 恢复的数据不一定是最近的一次计算,所以 source 记录的偏移量(offset)会恢复数据重新计算部分结果。
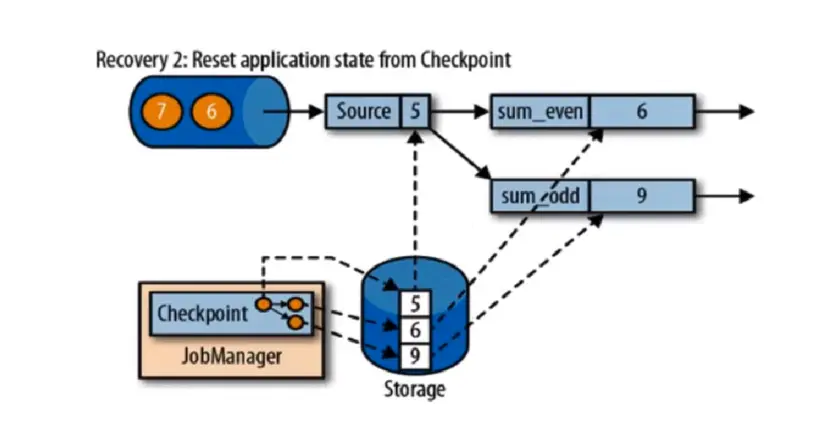
第三步,开始消费并处理检查点到发生故障之间的所有数据,这种检查点的保存和恢复机制可以为应用程序状态提供” 精确一次 “(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置。
# flink 检查点算法
基于 Chandy-Lamport 算法的分布式快照,将检查点的保存和数据处理分离开,不暂停整个应用。就像拼图一样,每个点都是不同时间处理完数据的状态快照,恢复我只需要按拓扑图(拼图原图)拼起来。
检查点分界线(Checkpoint Barrier),flink 的检查点算法用到一种称为分界线(barrier)特殊的数据形式,用来把一条流数据按照不同的检查点分开。分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中。
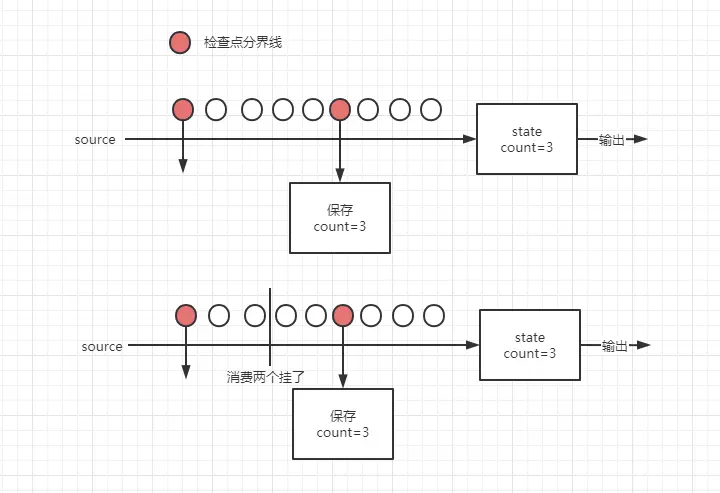
恢复的话,就会从第一个检查点分界线恢复,然后把数据,之后的数据回放。
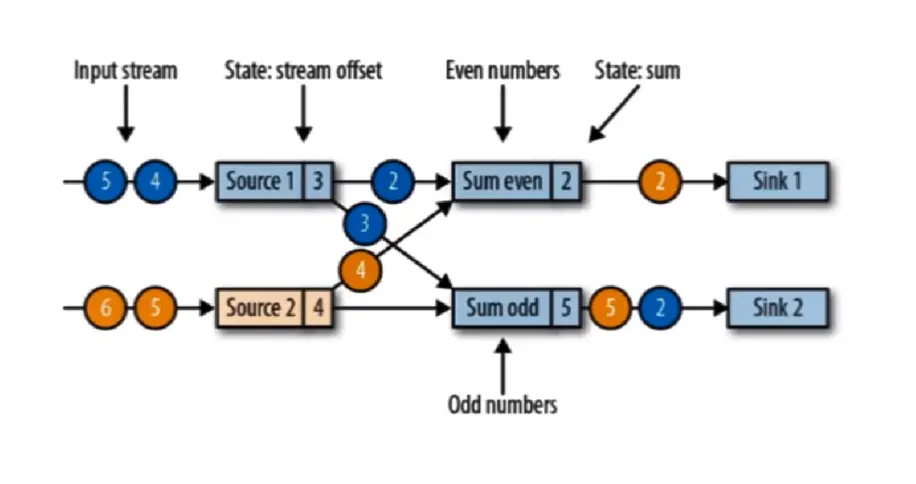
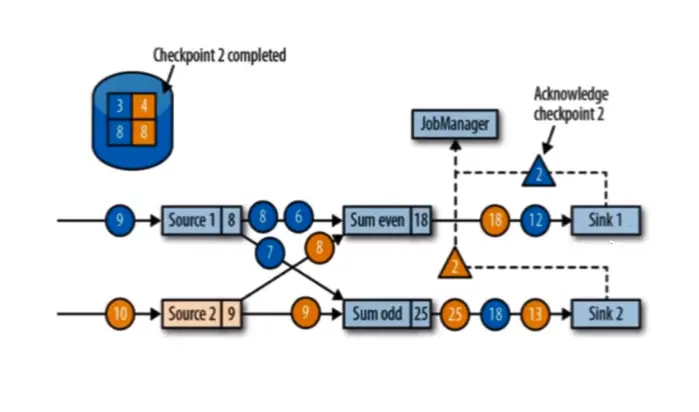
现在有两个输入流的应用程序,用并行的两个 source 任务来读取。sum_even = 黄 2,是因为 even (偶数) 接收到黄 2,odd (奇数) 输出蓝 2 和黄 5,它接收到的规律是先接受到 黄 1,加蓝 1 = 输出状态蓝 2,加黄 3 = 输出状态 黄 5。此时 黄 4 和 蓝 2,3 还在路上,source 的 offset 记录这 3 和 4。
JobManager 会向每个 source 任务发送一条带有新检查点 ID 的消息,通过这种方式来启动检查点。检查点被分配到 source1 数据的 3 和 4 之间,source2 数据的 4 和 5 之间,此时上一步的黄 2 和蓝 2 都被输出掉。
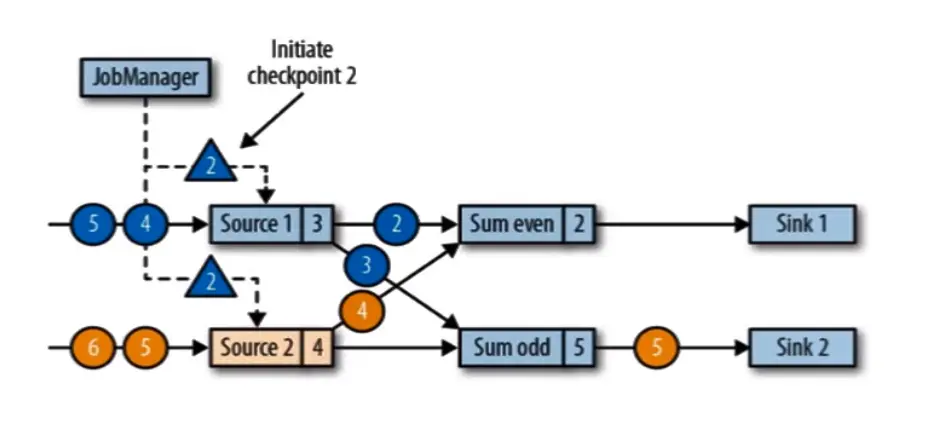
source(数据源)将他们的状态写入检查点,并发出一个检查点 barrier,状态后端在状态存入检查点之后,会返回通知给 source 任务,source 任务就会向 JobManager 确认检查点完成。完成后 source 会以广播的形式,把检查点广播给下游任务,并且 even=4 处理了蓝 2 odd=8 处理了蓝 3。even 和 oadd 会接收到两个 barrier,even 接收到蓝色 barrier,并不会去做状态的存入,蓝色 barrier 只是告诉 3 状态保存了,所以还需要等黄色 barrier 到齐才能进行状态的存入,告诉我 3 和 4 都存入到检查点才行。但是 黄 2 barrier,之前的 黄 4 数据还没有被处理,所以必须等黄 4 处理掉并等齐 蓝 2 和 黄 2 barrier,才能做任务的状态存入检查点。
等到所有的 barrier 到齐称为 分界线对齐:barrier 向下游传递,sun 任务会等待所有输入并行的 barrier 到达,对于 barrier 已经达到的,继续到达的数据会被缓存,而 barrier 尚未达到的,数据会被正常处理,只会处理 barrier 之前的数据。
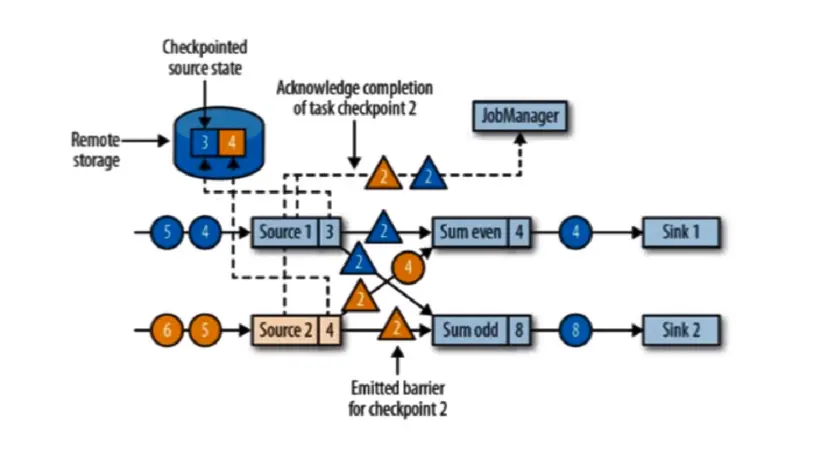
蓝 4,5 黄 6,5 会暂时存入缓存,等状态存入检查点
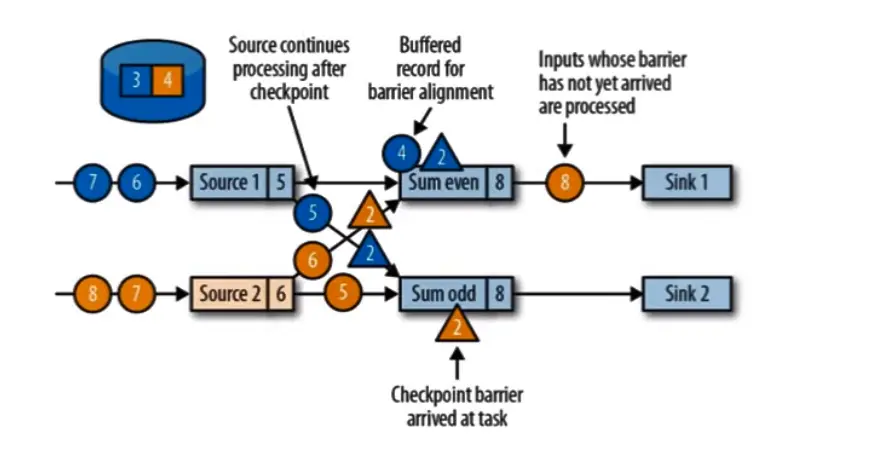
当收到所有输入分区的 barrier 时,任务就将其状态保存到状态后端的检查点中,然后将 barrier 继续向下游转发。任务 和 sink 会直传。
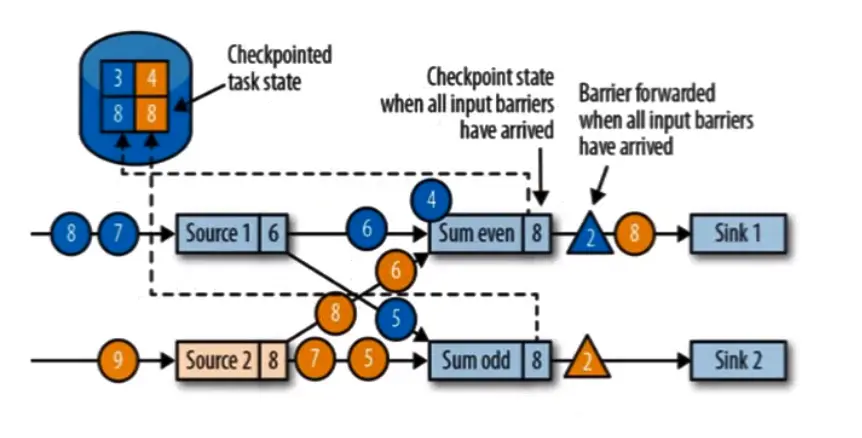
向下游转发检查点 barrier 后,任务继续正常的数据处理
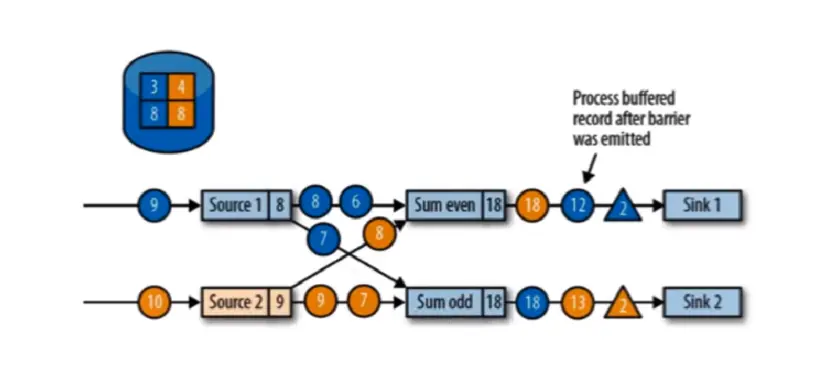
sink 任务向 JobManager 确认状态保存到 checkpoint 完毕,当所有任务都确认已成功状态保存到检查点时,检查点就真正完成了。
# 保存点(save point)
flink 提供了可以自定义的镜像保存功能,就是保存点(savepoints),原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以任务就是具有一些额外元数据的检查点。flink 不会自动创建保存点,因此用户(或者外部调度程序)必须明确触发创建操作,保存点是一个强大的功能。除了故障恢复外,保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停和重启应用等。
# 配置
默认情况下检查点是不开启的。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
// 1. 状态后端配置
env.setStateBackend(new FsStateBackend(""));
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new RocksDBStateBackend(""));
// 2. 检查点配置 时间间隔,周期性触发检查点保存 ms
env.enableCheckpointing(300);
// 设置级别 精确一次
env.enableCheckpointing(300, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointInterval(300);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 超时时间 checkpoint 存入超时的时间
env.getCheckpointConfig().setCheckpointTimeout(500);
// 最大同时进行的 checkpoint 前一个还没有保存,下一个又触发,怕堆积
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
// 两个checkpoint,前一个保存结束 到 下一个触发开始之间的 允许空闲时间 不能小于 100ms
// 如果说checkpoint比较慢,则很肯能没有太多数据处理而又要 checkpoint,我允许做完第一个休息 100ms 在做下一个
// 除非checkpoint非常的快速做完了,在100ms做完,那么此时我 只会按照正常的 300ms的间隔,休息200ms 然后去触发下一个checkpoint
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(100);
// 允许容忍 checkpoint 失败多少次,checkpoint 保存挂了,默认0 不容忍
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(3);
// 3. 重启策略配置
env.setRestartStrategy(RestartStrategies.noRestart()); // 不重启
env.setRestartStrategy(RestartStrategies.fallBackRestart()); // 回滚重启
// 固定延迟重启,每隔10s尝试重启,重启3次
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,10000));
// 失败率重启 10分钟之内最多3次重启,每次重启间隔1分钟
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.minutes(10),Time.minutes(1)));
DataStream<String> dataStream = env.socketTextStream("192.168.200.58", 7777);
dataStream.print();
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
checkpoint 是同步等待
用几句话总结一下:
- checkpoint 的侧重点是 “容错”,即 Flink 作业意外失败并重启之后,能够直接从早先打下的 checkpoint 恢复运行,且不影响作业逻辑的准确性。而 savepoint 的侧重点是 “维护”,即 Flink 作业需要在人工干预下手动重启、升级、迁移或 A/B 测试时,先将状态整体写入可靠存储,维护完毕之后再从 savepoint 恢复现场。
- savepoint 是 “通过 checkpoint 机制” 创建的,所以 savepoint 本质上是特殊的 checkpoint。
- checkpoint 面向 Flink Runtime 本身,由 Flink 的各个 TaskManager 定时触发快照并自动清理,一般不需要用户干预;savepoint 面向用户,完全根据用户的需要触发与清理。
- checkpoint 的频率往往比较高(因为需要尽可能保证作业恢复的准确度),所以 checkpoint 的存储格式非常轻量级,但作为 trade-off 牺牲了一切可移植(portable)的东西,比如不保证改变并行度和升级的兼容性。savepoint 则以二进制形式存储所有状态数据和元数据,执行起来比较慢而且 “贵”,但是能够保证 portability,如并行度改变或代码升级之后,仍然能正常恢复。
- checkpoint 是支持增量的(通过 RocksDB),特别是对于超大状态的作业而言可以降低写入成本。savepoint 并不会连续自动触发,所以 savepoint 没有必要支持增量。