 Flink 状态管理
Flink 状态管理
Flink 中的状态是由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务状态,可以认为状态就是一个本地变量,可以被任务的业务逻辑访问。Flink 会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑。
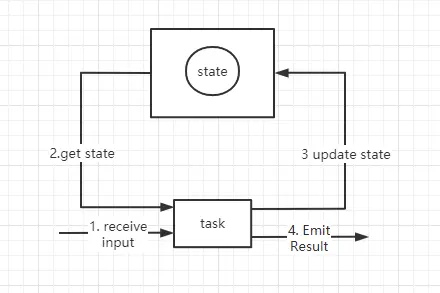
在 Flink 中,状态始终于特定算子相关联,为了使运行时的 Flink 了解算子的状态,算子需要预先注册其状态。flink 不能跨任务访问状态,状态会被分配到一个插槽里,所以根据特定的算子和特定的任务关联在一起的。
算子和任务是一个概念,如 map、flatMap 等,都属于一个算子或一个任务
flink 中的状态分为:算子状态(Operatior State)、键控状态(Keyed State)、状态后端(State Backends)
# 算子状态 Operatior State
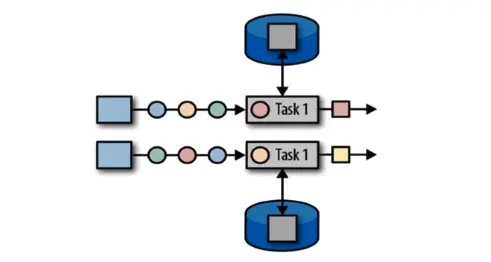
算子状态的作用范围限定为算子任务,由同一并行任务所处理的所有数据都可以访问当相同的状态。状态对于同一子任务而言是共享的,算子状态不能由相同或不同算子的另一个子任务访问。简单说,并行下各自的并行的算子有各自的状态,如果对并行的数据 keyBy 操作,他们的不同的分区也访问的是同一个状态。
算子状态数据结构:列表结构(List State),将状态表示为一组 数据的列表;联合列表状态(Union List State),也将状态表示为数据的列表,它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复;广播状态(Broadcast State),如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态(配置项比较适合)。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> dataStream = env.socketTextStream("192.168.200.58", 7777);
// 数据转换
DataStream<EventData> stream = dataStream.map(new MapFunction<String, EventData>() {
@Override
public EventData map(String value) throws Exception {
String[] strs = value.split(",");
return new EventData(Integer.valueOf(strs[0]),Long.valueOf(strs[1]),strs[2],Integer.valueOf(strs[3]));
}
});
//定义一个有状态的Map操作,统计不同分区 num字段 累加值,每个分区都会有独立的 状态
stream.map(new MySumMap()).print();
env.execute("test");
}
private static class MySumMap implements MapFunction<EventData,Integer>, ListCheckpointed<Integer> {
// 定义一个本地变量,做为算子状态
private Integer sum = 0;
@Override
public Integer map(EventData value) throws Exception {
return sum += value.getNum();
}
// 快照 保存到 checkpoint
@Override
public List<Integer> snapshotState(long checkpointId, long timestamp) throws Exception {
return Collections.singletonList(sum);
}
// 故障恢复
@Override
public void restoreState(List<Integer> state) throws Exception {
for(Integer n: state){
sum += n;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 键控状态 Keyed State
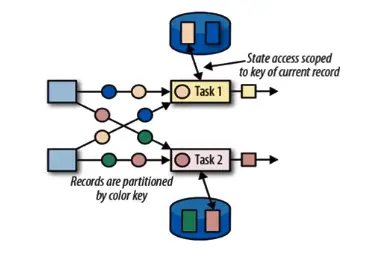
根据输入数据流中定义的键 (key) 来维护和访问的,Flink 为每个 key 维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个 key 对应的状态,当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key。
键控状态的数据结构分为:值状态(value state),将状态表示为单个的值;列表状态(list state),将状态表示为一组数据的列表;映射状态(map state),将状态表示为一组 key-value 对;聚合状态(Reducing state & Aggregating state),将状态表示为一个用于聚合操作的列表。
简单来说,key 和 分区 (并行) 会进行绑定,同一个 key 或相同的 hashcode 值绑定同一个分区,使用一个状态,和上面算子状态相反。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(1);
DataStream<String> dataStream = env.socketTextStream("192.168.200.58", 7777);
// 数据转换
DataStream<EventData> stream = dataStream.map(new MapFunction<String, EventData>() {
@Override
public EventData map(String value) throws Exception {
String[] strs = value.split(",");
return new EventData(Integer.valueOf(strs[0]),Long.valueOf(strs[1]),strs[2],Integer.valueOf(strs[3]));
}
});
//定义一个有状态的Map操作,统计不同分区 num字段 累加值,每个分区都会有独立的 状态
stream.keyBy(new KeySelector<EventData, String>() {
@Override
public String getKey(EventData value) throws Exception {
return value.getData();
}
}).map(new MySumMap()).print();
env.execute("test");
}
private static class MySumMap extends RichMapFunction<EventData,Integer> {
private ValueState<Integer> skey_um;
private ListState<String> myListState;
private MapState<String,Integer> mapState;
private ReducingState<EventData> reducingState;
@Override
public void open(Configuration parameters) throws Exception {
skey_um = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("key-sum",Integer.class));
myListState = getRuntimeContext().getListState(new ListStateDescriptor<String>("my-list-state",String.class));
mapState = getRuntimeContext().getMapState(new MapStateDescriptor<String, Integer>("map-state",String.class,Integer.class));
reducingState = getRuntimeContext().getReducingState(new ReducingStateDescriptor<EventData>("reduce-state",new SumReduceFunction(),EventData.class));
}
@Override
public Integer map(EventData value) throws Exception {
Integer sum = skey_um.value();
if(sum ==null){
sum = new Integer(0);
}
Integer s = Integer.sum(sum,value.getNum());
skey_um.update(s);
// 其他状态的使用
// Iterable<String> strings = myListState.get();
// myListState.add();
// myListState.update();
// myListState.addAll();
//
// mapState.put();
// mapState.get();
// reducingState.add(value);
return s;
}
// 可以操作很多逻辑
private class SumReduceFunction implements org.apache.flink.api.common.functions.ReduceFunction<EventData> {
@Override
public EventData reduce(EventData value1, EventData value2) throws Exception {
return null;
}
}
@Override
public void close() throws Exception {
skey_um.clear();
myListState.clear();
mapState.clear();
reducingState.clear();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# 状态后端(State Backends)
每传入一条数据,有状态的算子任务都会读取和更新状态,由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会载本地维护其状态,以确保快速的状态访问。状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端,状态后端只要负责两件事:本地状态管理,以及将检查点(checkpoint)状态写入远程存储(快照,容错)。
flink 提供了三种不同类型的状态后端:
- MemoryStateBackend
内存级的状态后端,会将键控状态作为内存中的对象进行管理,将他们存储在 TaskManager 的 JVM 堆上,而将 checkpoint 存储在 JobManager 的内存中。特点是:快速、低延迟,但不稳定。 - FsStateBackend
将 checkpoint 存到远程的持久化文件系统(FileSystem)上,而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上。同事拥有内存级的本地访问速度,和更好的容错保证。 - RocksDBStateBackend
将所有状态序列化后,存入到本地的 RocksDB 中存储。
# 配置 flink-conf.yaml
# 配置 checkpoint 存储位置 jobmanager、filesystem、rocksdb
state.backend: filesystem
# filesystem 存储路径
state.checkpoints.dir: hdfs://node103:port/flink-checkpoints
state.savepoints.dir: hdfs://node103:port/flink-checkpoints
# 增量化报错 checkpoint
state.backend.incremental: false
# 区域重启
jobmanager.execution.failover-strategy: region
2
3
4
5
6
7
8
9
区域重启,意思是如果某个 taskmanager 挂掉,之前的做法是停掉所有任务并重启,而区域重启只需要和挂掉相关的 taskmanager 停掉重启即可。
# 代码配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>1.12.2</version>
</dependency>
2
3
4
5
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
env.setStateBackend(new FsStateBackend(""));
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new RocksDBStateBackend(""));
DataStream<String> dataStream = env.socketTextStream("192.168.200.58", 7777);
dataStream.print();
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
# 重点声明
当一个算子 或 sink 任务,再设置并行度为 >1 的情况下,算子 或 sink 中的 open 函数(该函数只有继承当有 RichxxxxFunction 等类才有),会根据并行度执行相等的次数,比如我并行度设置 5,我的 open () 就会被调用 5 次。而该算子的构造器函数,只会被调用一次。构造器中一般不允许传不可序列化的对象,所以构造器一般用于传入 缓存数据 或 状态 或 初始化值。
当 invoke 接收到数据的时候,如果修改缓存数据或状态,那修改的是属于自己线程的,也就是通过构造器所传来的 缓存数据 或 状态 或 初始化值,他们是并行度之间隔离的,每个并行线程都有一份。
缓存数据不要过大,否则容易造成溢出,对于超大数据可以使用 redis 或 clickhouse 等。
如果在这里需要连接 Mysql,建议单独为 sink 或算子设置连接数,因为每个线程独一份的特性,连接数不宜设置过大,避免不必要的连接。