 Flink 时间语义及Watermark
Flink 时间语义及Watermark
# 时间语义
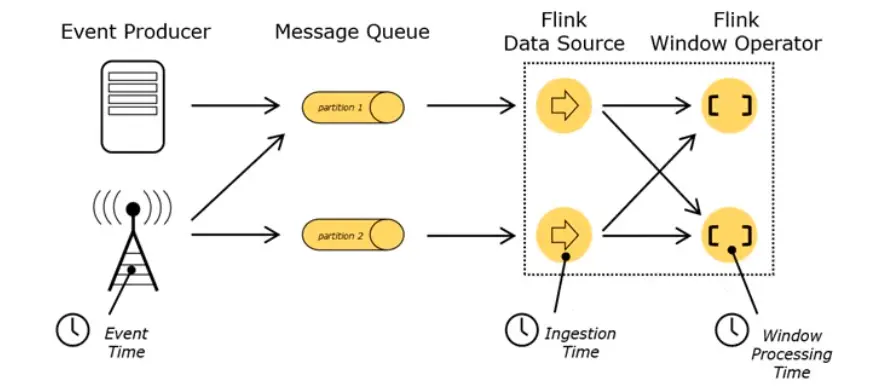
flink 有三种时间:EventTime,表示数据最初的触发时间;IngestionTime,数据进入 Flink 的时间,是 DataSource 拿到数据的时间;ProcessingTime,执行操作算子的本地系统时间,与机器相关。
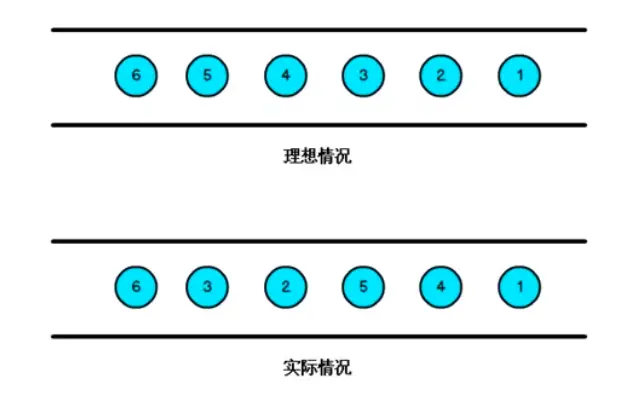
flink1.12 中默认时间语义是 EventTime,在实际处理数据,大多也都是以 EventTime 为主。因为数据可能受于网络的影响,或其他因素导致乱序数据的产生。
# Watermark
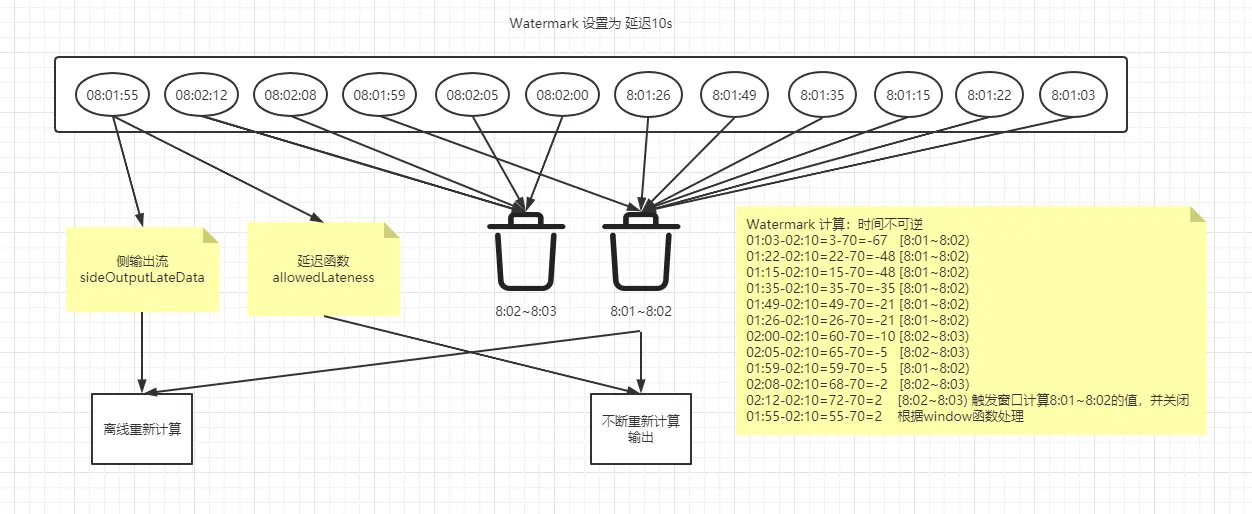
那对于乱序数据我们就可以使用 Watermark,我们来举个例子说明 flink 中的 Watermark 是什么:比如定点 9 点上车,但是往往有人 9.01 才来,那 Watermark 的做法就是把自己的时间调慢,也就是 8.59 分,9.01 的人来了 对于我来说还是 9 点。如果有人 9.02 来了,那其实可以配合 window 的延迟,我先输出数据开车,你来弯道超车,然后我重新计算输出新数据,但非有人,9.03 来呢,那我不管你了,我开车上高速,你可以坐下一辆车(侧输出流)。
Watermark 的时间不宜设置太大,因为拿到数据时间可能是准确的,但是拿到数据就会很慢。相当于 9 点发车,但我想等人到齐(数据),我设置到了 8.30,我需要在等 30 分钟才能发车,此时我到站 比别人还晚 30 分钟。
以下演示 Watermark 时间乱序处理,和配合 window 的函数处理
Watermark 在分区中会计算最小事件时钟,保证下游数据收到每个事件时钟,并根据自己的时钟得出是否计算结果并关闭窗口。Watermark 是以广播的形式把事件时钟传递给每个下游。
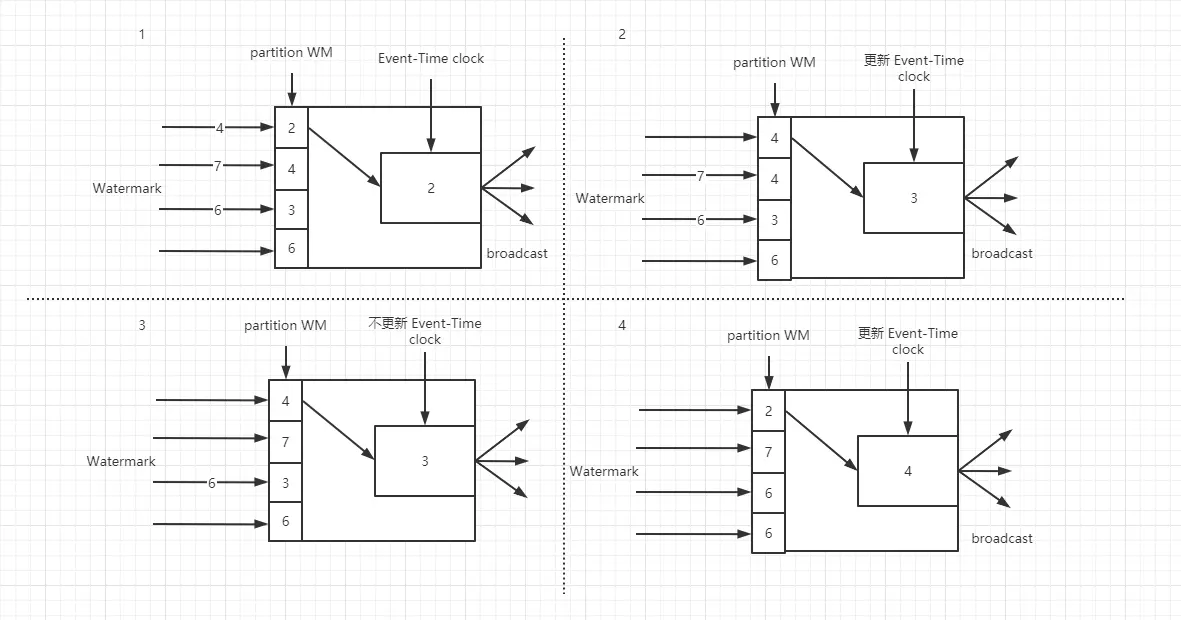
watermark 的特性主要有以下几点:
- 数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据都已经到达,因此 Window 的执行是由 Watermark 触发的
- Watermark 是一条特殊的数据记录
- Watermark 必须单调递增,以确保任务的事件时间时钟向前推进,不可逆
# 代码演示
public class EventData{
private Integer id;
private Long eventTime;
private String data;
private Integer num;
public EventData(){
};
public Integer getNum() {
return num;
}
public void setNum(Integer num) {
this.num = num;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Long getEventTime() {
return eventTime;
}
public void setEventTime(Long eventTime) {
this.eventTime = eventTime;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
@Override
public String toString() {
return "EventData{" +
"id=" + id +
", eventTime=" + eventTime +
", data='" + data + '\'' +
", num=" + num +
'}';
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<String> dataStream = env.socketTextStream("192.168.200.58", 7777);
// 数据转换
DataStream<EventData> stream = dataStream.map(new MapFunction<String, EventData>() {
@Override
public EventData map(String value) throws Exception {
String[] strs = value.split(",");
EventData eventData = new EventData();
eventData.setId(Integer.valueOf(strs[0]));
eventData.setEventTime(Long.valueOf(strs[1]));
eventData.setData(strs[2]);
eventData.setNum(Integer.valueOf(strs[3]));
return eventData;
}
// 处理时间乱序的水印 BoundedOutOfOrdernessTimestampExtractor,升序时间戳水印使用 AscendingTimestampExtractor
}).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<EventData>(Time.seconds(5)) {
//提取时间戳
@Override
public long extractTimestamp(EventData element) {
return element.getEventTime() * 1000L;
}
}
);
stream.print("WM: ");
// 基于事件时间的开窗聚合,统计15秒内数据的最小ID值
stream.keyBy(new KeySelector<EventData, Object>() {
@Override
public Object getKey(EventData value) throws Exception {
return value.getData();
}
})
.timeWindow(Time.seconds(15))
// .window(TumblingEventTimeWindows.of(Time.seconds(15)))
.sum("num")
.print("result: ");
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
setAutoWatermarkInterval 是设置 Watermark 的生成时间,默认是 0,也就是来一个数据我对这个数据生成一个 Watermark 时钟,用于去比较窗口函数的时间来触发计算。可以手动设置,在庞大的数据量,每生成一个 Watermark 有些费性能。以下为隔 100ms 生成一次。
env.getConfig().setAutoWatermarkInterval(100);
测试数据如下:
6,1623051400,test data,1
6,1623051401,test data,1
6,1623051402,test data,1
6,1623051405,test data,3
6,1623051406,test data,3
6,1623051409,test data,3
6,1623051410,test data,5
2
3
4
5
6
7
你会发现当你的 timestamp 为 1623051410,会触发窗口计算,但输出的 num=3,因为 Watermark 创建窗口是会自动创建,会根据你的第一个数据的 timestamp 以及 timeWindow 窗口的值计算窗口的 startTime,计算方式
# startTime
timestamp - (timestamp - offset + windowSize) % windowSize;
# endTime
startTime + windowSize
2
3
4
其中默认情况 offset = 0,根据以上计算得出如下
startTime timestamp
1623051390000 1623051400000
1623051390000 1623051401000
1623051390000 1623051402000
1623051405000 1623051405000
1623051405000 1623051406000
1623051405000 1623051409000
1623051405000 1623051410000
2
3
4
5
6
7
8
会看到 400000 (timestamp) 创建的 startTime 是 390000,405000 (timestamp) 创建的 startTime 是 405000,他们被分为了两个窗口。而他们的 405000-390000=15000=15s,刚好就是我们的 windowSize,也就是说 405000 的触发点在 420000 ,但我们还给 Watermark 延迟了 5s,也就是说正确的关闭第二个窗口的 timestamp = 1623051425000,得出结论
Watermark1=[390,405) Watermark2=[405,420)
以上结论并行度为 1
# Watermark 和 KeyBy 的关系
实体类
public class EventData{
private String id;
private Long eventTime;
private String data;
private Integer num;
public EventData(){
};
public Integer getNum() {
return num;
}
public void setNum(Integer num) {
this.num = num;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public Long getEventTime() {
return eventTime;
}
public void setEventTime(Long eventTime) {
this.eventTime = eventTime;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
@Override
public String toString() {
return "EventData{" +
"id=" + id +
", eventTime=" + eventTime +
", data='" + data + '\'' +
", num=" + num +
'}';
}
public EventData(String id, Long eventTime, String data, Integer num) {
this.id = id;
this.eventTime = eventTime;
this.data = data;
this.num = num;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
逻辑代码,并行度为 1
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<String> dataStream = env.socketTextStream("192.168.200.58", 7777);
// 数据转换
DataStream<EventData> stream = dataStream.map(new MapFunction<String, EventData>() {
@Override
public EventData map(String value) throws Exception {
String[] strs = value.split(",");
return new EventData(
strs[0],
Long.valueOf(strs[1]),
String.valueOf((Long.valueOf(strs[1])-5)),
Integer.valueOf(strs[3])
);
}
}).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<EventData>(Time.seconds(5)) {
//提取时间戳
@Override
public long extractTimestamp(EventData element) {
return element.getEventTime() * 1000L;
}
}
);
stream.print("WM: ");
// 基于事件时间的开窗聚合,统计15秒内数据的最小ID值
stream.keyBy(EventData::getId)
.window(TumblingEventTimeWindows.of(Time.seconds(15)))
.sum("num")
.print("result: ");
env.execute("test");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
数据
1a,1623051400,test data,1
2b,1623051402,test data,1
1a,1623051404,test data,2
2b,1623051405,test data,3
1a,1623051407,test data,6
3c,1623051417,test data,1
2
3
4
5
6
结果
WM: > EventData{id=1a, eventTime=1623051400, data='1623051395', num=1}
WM: > EventData{id=2b, eventTime=1623051402, data='1623051397', num=1}
WM: > EventData{id=1a, eventTime=1623051404, data='1623051399', num=2}
WM: > EventData{id=2b, eventTime=1623051405, data='1623051400', num=3}
WM: > EventData{id=1a, eventTime=1623051407, data='1623051402', num=6}
WM: > EventData{id=3c, eventTime=1623051417, data='1623051412', num=1}
result: > EventData{id=1a, eventTime=1623051400, data='1623051395', num=3}
result: > EventData{id=2b, eventTime=1623051402, data='1623051397', num=1}
2
3
4
5
6
7
8
数据里只有 id=1a 加上了相同 ID 的 num 值,但是 2b 却没有加,因为 1a 的事件时间开窗范围是 [390-405),2b 有两个开窗范围,分别是 402 对应 [390-405)、405 对应 [405-420)。简单说,就是每个数据的事件时间到来都会去做一次桶 (范围) 的计算 (包括是否需要新建一个桶),只有相同桶 (范围) 的在一起进行 keyBy 和 sum。输出两条数据,是因为分区有两个。
# Watermark 多并行
当并行度为 2,的时候。
测试数据
6,1623051400,test data,1
6,1623051401,test data,1
6,1623051402,test data,1
6,1623051405,test data,3
6,1623051406,test data,3
6,1623051409,test data,3
6,1623051410,test data,5
2
3
4
5
6
7
结果
WM: :1> EventData{id=6, eventTime=1623051400, data='1623051395', num=1}
WM: :2> EventData{id=6, eventTime=1623051401, data='1623051396', num=1}
WM: :1> EventData{id=6, eventTime=1623051402, data='1623051397', num=1}
WM: :2> EventData{id=6, eventTime=1623051405, data='1623051400', num=3}
WM: :1> EventData{id=6, eventTime=1623051406, data='1623051401', num=3}
WM: :2> EventData{id=6, eventTime=1623051409, data='1623051404', num=3}
WM: :1> EventData{id=6, eventTime=1623051410, data='1623051405', num=5}
WM: :2> EventData{id=6, eventTime=1623051410, data='1623051405', num=5}
result: :1> EventData{id=6, eventTime=1623051400, data='1623051395', num=3}
2
3
4
5
6
7
8
9
在并行任务中,桶(范围)会存在多个,但每个并行任务共享一个最小 (时间) 的桶(范围),只有每个并行任务都达到或超过最小桶的水位线,窗口才会触发。
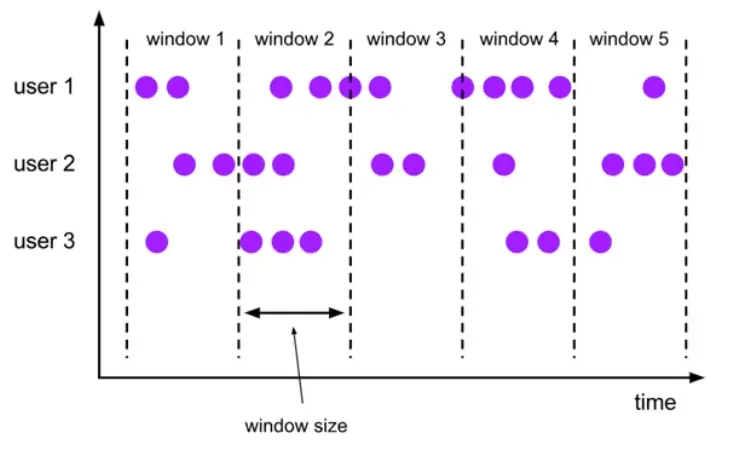
user1,2,3 就是并行任务,window1,2,3,4,5 都是桶,其中 window1 是最小 (时间) 的桶,只有 user1,2,3 数据的事件时间都大于 window1 的 windows size,window1 才会触发计算。
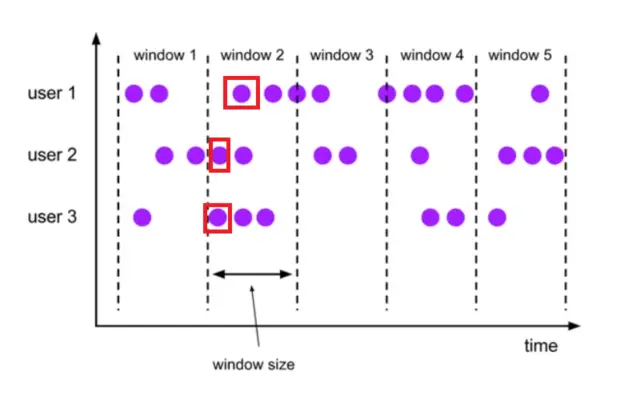
# 数据倾斜
数据倾斜的造成是因为,我 user1,user2,这两个一直都有数据的最新事件时间,但是 user3 的事件时间一直在 window1 的范围,导致我 user1,user2 都到了 window5 的窗口生成了,而没办法结束 window1 窗口。
# Trigger
flink 的 source 之后,假如需要窗口函数,我们就要使用一定的规则来判断或者决定该数据应该属于哪个窗口,然后看窗口要是基于事件时间的话我们还要提供时间戳抽取器和 watermark 分配器,最后还要指定满足何种条件触发窗口计算并输出结果。
那可能会说了触发窗口计算,不就是时间到窗口结束时间了直接输出不就行了吗?这样输出的频率可以直接由滑动间隔来控制了。
实际上,不行的,基于事件时间处理机制,数据会在有些意想不到的情况下滞后,比如 forward 故障等,这种情况,对于 flink 来说我们可以设置一些参数来允许处理滞后的元素,比如允许其滞后一小时,那么这个时候实际上窗口输出间隔就是要加上这个滞后时间了,这时候假如我们想要尽可能的实时输出的话,就要用到 flink 的 trigger 机制。
Trigger 定义了何时开始使用窗口计算函数计算窗口。每个窗口分配器都会有一个默认的 Trigger。如果,默认的 Trigger 不能满足你的需求,你可以指定一个自定义的 trigger ().
Flink 内部有一些内置的触发器:
- EventTimeTrigger:基于事件时间和 watermark 机制来对窗口进行触发计算。
- ProcessingTimeTrigger: 基于处理时间触发。
- CountTrigger: 窗口元素数超过预先给定的限制值的话会触发计算。
- PurgingTrigger 作为其它 trigger 的参数,将其转化为一个 purging 触发器。
- WindowAssigner 的默认触发器适用于很多案例。比如,所有基于事件时间的窗口分配器都用 * EventTimeTrigger 作为默认触发器。该触发器会在 watermark 达到窗口的截止时间时直接触发计算输出。
自定义 trigger,需要实现五个方法,允许 trigger 对不同的事件做出反应:
- onElement (): 进入窗口的每个元素都会调用该方法。
- onEventTime (): 事件时间 timer 触发的时候被调用。
- onProcessingTime (): 处理时间 timer 触发的时候会被调用。
- onMerge (): 有状态的触发器相关,并在它们相应的窗口合并时合并两个触发器的状态,例如使用会话窗口。
- clear (): 该方法主要是执行窗口的删除操作。
关于上述方法需要注意两点:
前三方法决定着如何通过返回一个 TriggerResult 来操作输入事件。
CONTINUE: 什么都不做。
FIRE: 触发计算。
PURE: 清除窗口的元素。
FIRE_AND_PURE: 触发计算和清除窗口元素。这些方法中的任何一个都可用于为将来的操作注册处理或事件时间计时器。
Trigger 描述来自 https://zhuanlan.zhihu.com/p/57939828