 Flink 配置介绍及Demo
Flink 配置介绍及Demo
# 配置详解
flink 目录下配有
bin 执行文件
|-- flink 集群
|-- start-cluster.sh
|-- stop-cluster.sh
|-- 组件
|-- jobmanager.sh 作业管理者
|-- taskmanager.sh 任务管理者
|-- yarn-session.sh 跟yarn模式下相关的作业提交
|-- k8s 部署相关命令
|-- kubernetes-entry.sh 作业管理者
|-- kubernetes-session.sh 任务管理者
|-- 提交作业,查看状态,取消停止
|--flink
conf 配置文件
|-- flink-conf.yaml 执行需要配置
|-- master jm管理者的页面
|-- workers tm 任务管理者配置集群的地方
examples 示例
lib 所有的支持性jar包
licenses 开源协议
log 日志
opt
plugins 插件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
flink-conf.yaml 参数详解
- jobmanager.rpc.address:作业管理者远程通信地址
- jobmanager.rpc.port:作业管理者远程通信端口

- jobmanager.memory.process.size:对应到图中的 Total Process Memory,管理 JVM 堆内存(年轻代、老年代)和 堆外内存(堆外内存也叫永久代,但是在 java8 废弃了,替代的是元空间(MetaSpace),存储程序运行时长期存活的对象,比如类的元数据、方法、常量、属性等 )
- jobmanager.memory.heap.size:对应到图中的 JVM Head:JobManager 的 JVM 堆内存大小。
- jobmanager.memory.jvm-metaspace.size:默认值:256mb ,对应到图中的 JVM Metaspace。JobManager JVM 进程的 Metaspace。
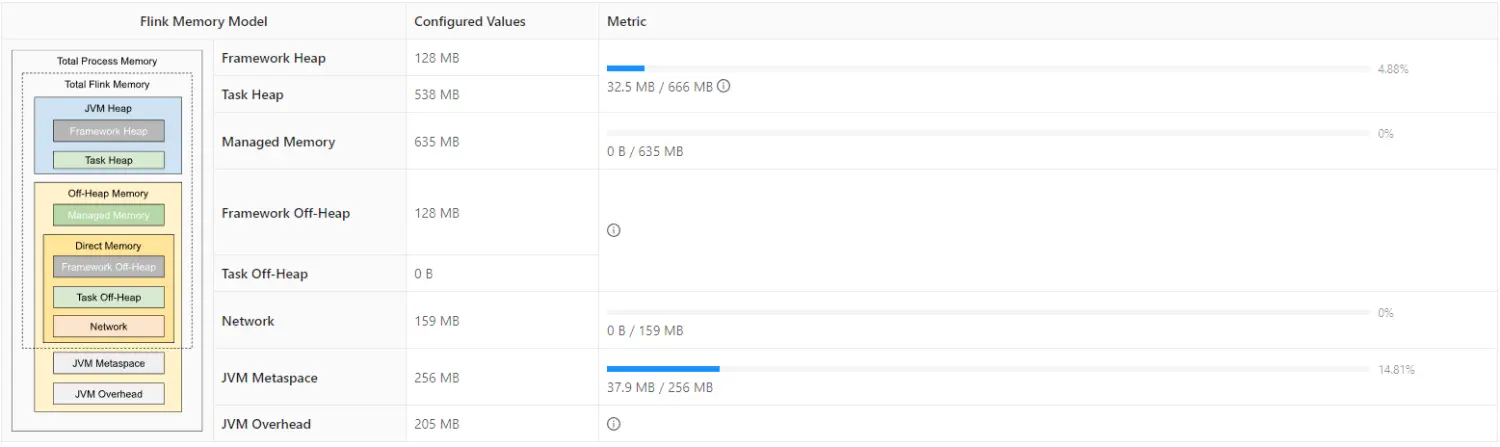
- taskmanager.memory.process.size:tm 任务管理者整个内存管理的大小。
- taskmanager.numberOfTaskSlots:任务管理者能跑几个线程并行,也指当前 Task 最大能执行的并行数量
- parallelism.default:真正执行的时候并行的数量
- web.upload.dir: /opt/flink/target:webUI 提交的 jar,重启 flink 是不会保存的,加上这个配置自己的路径会保存你提交的 jar
# 模拟实时 Stream
windows 开发的话,我们可以下载 nc,把其中的 nc.exe 拷贝到我们 C:\Users\ 当前登录的用户 下就可以。
然后 cmd 输入以下命令,-L 为监听,p 是端口,监听 7777,下载地址 https://eternallybored.org/misc/netcat/ (opens new window)
nc -Lp 7777
1
启动以下程序就可以模拟实时 stream
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.2</version>
</dependency>
</dependencies>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class EventData{
private Integer id;
private Long eventTime;
private String data;
private Integer num;
public EventData(){
};
public Integer getNum() {
return num;
}
public void setNum(Integer num) {
this.num = num;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Long getEventTime() {
return eventTime;
}
public void setEventTime(Long eventTime) {
this.eventTime = eventTime;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
@Override
public String toString() {
return "EventData{" +
"id=" + id +
", eventTime=" + eventTime +
", data='" + data + '\'' +
", num=" + num +
'}';
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
package com.example.demo;
import com.example.demo.bean.EventData;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author big uncle
* @date 2021/6/5 15:36
* @module
**/
public class EventTime {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 监听本地IP
DataStream<String> dataStream = env.socketTextStream("192.168.200.58", 7777);
// 数据转换
dataStream.map(new MapFunction<String, EventData>() {
@Override
public EventData map(String value) throws Exception {
String[] strs = value.split(",");
EventData eventData = new EventData();
eventData.setId(Integer.valueOf(strs[0]));
eventData.setEventTime(Long.valueOf(strs[1]));
eventData.setData(strs[2]);
eventData.setNum(Integer.valueOf(strs[3]));
return eventData;
}
}).print();
env.execute("test");
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
测试数据
1,1623051400,test data,1
1,1623051401,test data,1
1,1623051402,test data,1
1,1623051405,test data,3
1,1623051406,test data,3
1,1623051409,test data,3
1,1623051410,test data,5
1
2
3
4
5
6
7
2
3
4
5
6
7
# 适配 kafka 开发
# 创建应用 (项目)
你可以手动创建,也可以用 maven 命令创建,结构如下
|--project
|--src
|--main
|--java
|--com.example.demo
|--Demo.java
|--resources
|--log4j.properties
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
在工作目录下使用如下命令
mvn archetype:generate
-DarchetypeGroupId=org.apache.flink
-DarchetypeArtifactId=flink-walkthrough-datastream-java
-DarchetypeVersion=1.12.0
-DgroupId=frauddetection
-DartifactId=frauddetection
-Dversion=0.1
-Dpackage=spendreport
-DinteractiveMode=false
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# 引入依赖
引入的依赖版本最好和 flink 安装版本一致
<dependencies>
<!-- 必须要有 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
<!-- java flink 必须要有 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<!-- 如果将程序作为 Maven 项目开发,则必须添加 flink-clients 模块的依赖 必须要有 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<!-- 解决 Failed to load class "org.slf4j.impl.StaticLoggerBinder". -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 指定jdk版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- 一般项目打包是不会含有依赖的,使用这个可以帮你把依赖带上,不带的话提交到job是无法运行的 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<configuration>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<!-- 设置主入口 -->
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.example.demo.TestKafka</mainClass>
</transformer>
</transformers>
<!-- 自动将所有不使用的类全部排除掉,将 jar 最小化,导致不会引入所有依赖 -->
<!-- <minimizeJar>true</minimizeJar>-->
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
插件 maven-shade-plugin http://www.iigrowing.cn/maven-shade-plugin_ru_men_zhi_nan.html
# 代码
package com.example.demo;
import lombok.SneakyThrows;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
/**
* @author big uncle
* @date 2021/3/8 18:50
* @module
**/
public class TestKafka {
@SneakyThrows
public static void main(String[] args) {
// StreamExecutionEnvironment用于设置你的执行环境。任务执行环境用于定义任务的属性,创建数据源以及最终启动任务的执行。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置kafka信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.81.62:9092");
properties.setProperty("group.id", "test");
// 得到 kafka 实例
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<String>("topic2", new SimpleStringSchema(),properties);
// 尽可能从最早的记录开始
// myConsumer.setStartFromEarliest();
// 从最新的记录开始
myConsumer.setStartFromLatest();
// 从指定的时间开始(毫秒)
// myConsumer.setStartFromTimestamp();
// myConsumer.setStartFromGroupOffsets(); // 默认的方法
// 添加数据源
DataStream<String> stream = env.addSource(myConsumer).setParallelism(1);
// 简单得打印以下信息
// DataStream<Tuple2<String, Integer>> counts = stream.flatMap(new LineSplitter()).keyBy(0).sum(1);
stream.print();
//
env.execute("print-kafka-info");
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
collector.collect(new Tuple2<String, Integer>(s, 1));
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
以上是一个简单而完整 flink 整合 kafka 消费数据的例子,打包后提交到 flink 运行就行,会以无边界的形式持续运行。记得打包成功后,查看一下所打包的 jar 是否包含了所引用的依赖。
以上是我 flink-kafka 应用接收到的数据信息。
上次更新: 1/1/2026, 8:54:37 PM