Flink Joining编程
Flink Joining编程
# Window Join
窗⼝ join 将共享相同 key 并位于同⼀窗⼝中的两个流的元素联接在⼀起。可以使⽤窗⼝分配器定义这些窗⼝,并根据两个流中的元素对其进⾏评估。然后将双⽅的元素传递到⽤户定义的 JoinFunction 或 FlatJoinFunction,在此⽤户可以发出满⾜联接条件的结果。
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
2
3
4
5
注意:
- 创建两个流的元素的成对组合的⾏为就像⼀个内部联接,这意味着如果⼀个流中的元素没有与另⼀流中要连接的元素对应的元素,则不会发出该元素。
- 那些确实加⼊的元素将以最⼤的时间戳(仍位于相应窗⼝中)作为时间戳。例如,以 [5,10)为边界的窗⼝将导致连接的元素具有 9 作为其时间戳。
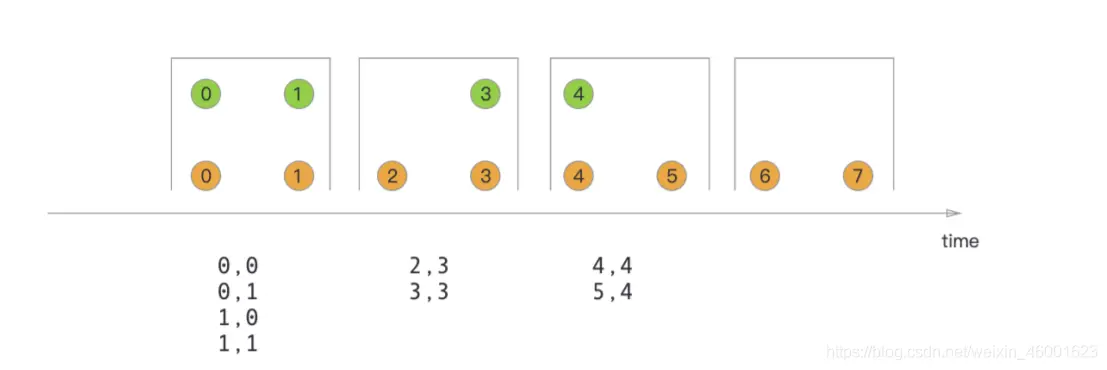
# Tumbling Window Join 滚动窗口 join
当执⾏滚动窗⼝联接时,所有具有公共键和公共滚动窗⼝的元素都按成对组合联接,并传递到 JoinFunction 或 FlatJoinFunction。因为它的⾏为就像⼀个内部联接,所以在其滚动窗⼝中不发射⼀个流中没有其他流元素的元素!
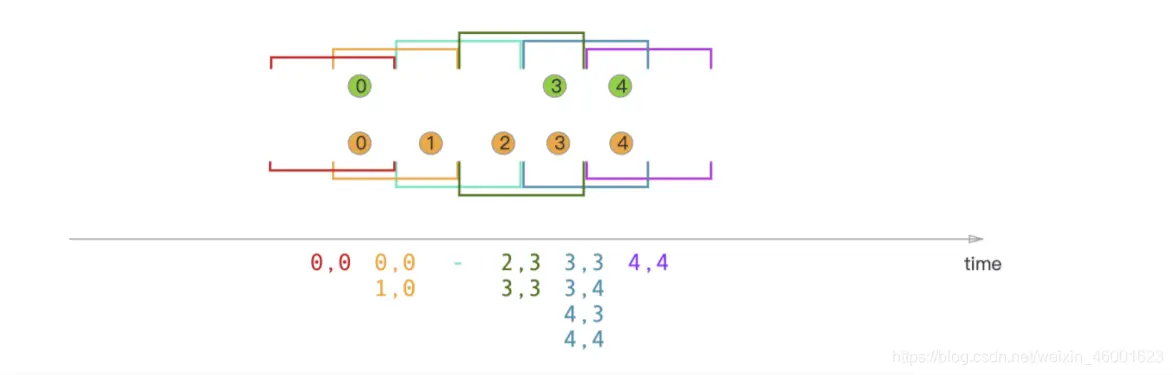
# Sliding Window Join 滑动窗⼝连接
执⾏滑动窗⼝连接时,所有具有公共键和公共滑动窗⼝的元素都按成对组合进⾏连接,并传递给 JoinFunction 或 FlatJoinFunction。在当前滑动窗⼝中,⼀个流中没有其他流元素的元素不会被发出!请注意,某些元素可能在⼀个滑动窗⼝中连接,但可能不能在另⼀个窗⼝中连接!
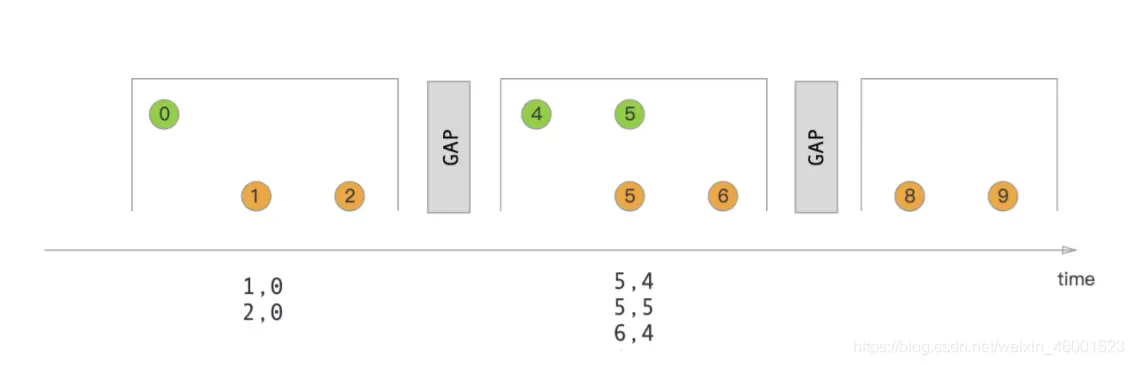
# Session Window Join 会话窗⼝连接
在执⾏会话窗⼝连接时,具有 “组合” 时满⾜会话条件的相同键的所有元素将以成对组合的⽅式连接在⼀起,并传递给 JoinFunction 或 FlatJoinFunction。再次执⾏内部联接,因此,如果有⼀个会话窗⼝仅包含⼀个流中的元素,则不会发出任何输出!
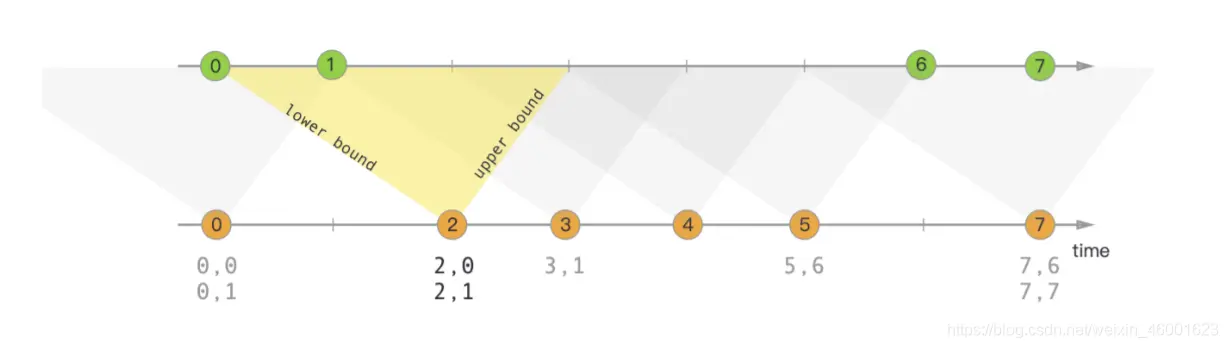
# Interval Join (区间 join)
间隔连接使⽤公共 key 连接两个流(现在将它们分别称为 A 和 B)的元素,并且流 B 的元素时间位于流 A 的元素时间戳的间隔之中,则 A 和 B 的元素就可以 join。
其中 a 和 b 是 a 和 b 的元素,它们共用一个键。只要下界总是小于或等于上界,下界和上界都可以是负的或正的。间隔连接目前仅执行内部连接。
当将一对元素传递给 ProcessJoinFunction 时,它们将被分配更大的时间戳 (可以通过 ProcessJoinFunction.Context 访问它) 这两个元素。
interval 连接目前只支持事件时间。