 Flink 介绍及安装
Flink 介绍及安装
本文及后续所有文章都以 1.12 做为版本讲解和入门学习
# 概要
Flink 是一个可以帮助我们做实时计算的框架。实时计算分为两种,一种是 Stream,即可以一条一条处理;一种是 batch,即批处理,待数据存储到一定数量再处理。
Flink 提供了很好的故障恢复能力,当我们的一个流处理程序故障后,一个新的流程服务会自动启动并替代它继续执行。我们并不需要担心故障机当时的状态,因为 Flink 已经帮我们做了记录 (checkPoint)。
Flink 支持 (exactly-once) 一次而且仅一次地接收数据,保证收到数据而且不重复收到数据。支持 (EventTime) 把事件实际产生的时间做为处理数据的时间,除了 EventTime 还要 Ingestion Time (数据进入 Flink 时间)、Processing Time (flink 真正处理数据的时间)。支持有状态的计算。
Flink 的 window 可以将无限数据流切割为有限数据流,主要分为两类:TimeWingdow (又可分为 Tumbling Window 滚动出窗口、Sliding Window 滑动窗口) 和 CountWindow。
Flink 的 Watermark (水位线) 用于处理乱序事件,类似于一个延迟触发机制
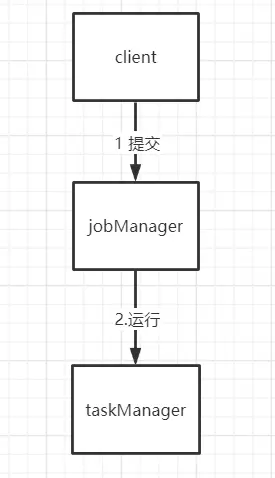
Flink 组件分为 jobManager (工作管理) 和 TaskManager (任务管理),听起来好像没什么不同,但程序真正运行在 TaskManager,JobManager 负责整个 Flink 集群任务的调度以及资源的管理。
# 安装
wget https://mirrors.bfsu.edu.cn/apache/flink/flink-1.12.2/flink-1.12.2-bin-scala_2.11.tgz
tar -xvf flink-1.12.0-bin-scala_2.11.tgz
cd flink-1.12.0-bin-scala_2.11
2
3
启动
[root@localhost flink-1.12.2]# ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host localhost.localdomain.
Starting taskexecutor daemon on host localhost.localdomain.
2
3
4
测试用例
# 执行一个测试程序
./bin/flink run examples/streaming/WordCount.jar
# 查看测试结果
tail log/flink-*-taskexecutor-*.out
2
3
4
停止运行
./bin/stop-cluster.sh
Flink 默认提供了 webUI,端口为 8081,可以直接在浏览器中访问
# 单机搭建
# 环境信息
| IP | 模式 |
|---|---|
| xx.xxx.xx.103 | master |
| xx.xxx.xx.104 | slave |
# ssh 免密登录
在集群的启动的时候 flink 会要求认证对方的登录密码,设置 ssh 免密登录可以为我们快速启动。
# 1. 为各服务器生成密钥
一路 enter 即可
# rea是一种加密规则
ssh-keygen -t rsa
2
查看密钥
[root@localhost /]# cd ~/.ssh/
[root@localhost .ssh]# ll
total 12
-rw-------. 1 root root 1679 Apr 17 14:46 id_rsa
-rw-r--r--. 1 root root 408 Apr 17 14:46 id_rsa.pub
2
3
4
5
id_rsa : 生成的私钥文件
id_rsa.pub : 生成的公钥文
# 2. 服务器之间交换密钥
生成的密钥两边文件名字一样,所以交换的时候需要更换文件名称,以防覆盖。
# 这种方式后可以直接测试连接 103 或 104
ssh-copy-id xx.xxx.xx.103
ssh-copy-id xx.xxx.xx.104
# 这种方式需要完整的执行以下步骤
scp id_rsa.pub root@xx.xxx.xx.103:/root/.ssh/104.id_rsa.pub
scp id_rsa.pub root@xx.xxx.xx.104:/root/.ssh/103.id_rsa.pub
2
3
4
5
6
7
# 3. 创建文件并赋权
在各服务机的~/.ssh 目录下创建一个文件 authorized_keys
touch authorized_keys
把 xxx.id_rsa.pub 内容追加到 authorized_keys 文件末尾(追加后可以把文件 xxx.id_rsa.pub 删除)
cat 103.id_rsa.pub >> authorized_keys
cat 104.id_rsa.pub >> authorized_keys
2
把本机生成的公钥也得 追加到 authorized_keys 文件
cat id_rsa.pub >> authorized_keys
赋权
chmod 600 authorized_keys
chmod 700 -R .ssh
2
测试 连接
ssh root@xx.xxx.xx.103
# workermanager
一个 Flink 应用会携带 JobManager 和 TaskManager 两个组件,我们可以部署两个 Flink 应用实现以下简单的 TaskManager 的集群模式,FlinkA 可以启动 Job 和 Task 两个组件,FlinkB 启动 Task 组件。
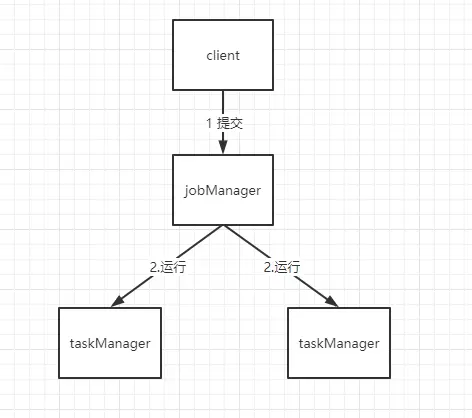
启动前每台服务器最好把 Hostname 改掉,并修改 hosts。这里还有一点需要注意,两台的 flink 配置都需要改掉,否则你会看到 Task 只有那台启动 job 的才有连接上。
# 103、104 操作
- 修改 jobmanager 工作地点
vim flink-conf.yaml
# 加入如下
jobmanager.rpc.address: xx.xxx.xx.103
jobmanager.rpc.port: 6123
2
3
4
- 修改 workers 文件,指定 workermanager 工作地点
vim workers
# 加入如下
xx.xxx.xx.103
xx.xxx.xx.104
2
3
4
- 启动 xx.xxx.xx.103 flink 节点
[root@node103 bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node103.
Starting taskexecutor daemon on host node103.
Starting taskexecutor daemon on host node104.
2
3
4
5
- 访问 http://xx.xxx.xx.103:8081/#/overview
建议修改一下属性值:
每个 JobManager 的可用内存值(jobmanager.memory.process.size)
每个 TaskManager 的可用内存值 (taskmanager.memory.process.size,并检查 内存调优指南 (opens new window))
每台机器的可用 CPU 数(taskmanager.numberOfTaskSlots)
集群中所有 CPU 数(parallelism.default)和 临时目录(io.tmp.dirs)
命令运行 jar,可以到 flink/bin 目录下,执行
./flink run -c com.example.demo.SocketStreamWordCount -p 3 /opt/software/flink-1.12.2/examples/xxxxxx.jar --host 10.xxx.xx.103 --port 7777
- -c 是程序的主入口
- -p 是并行度
- --host --port 是 args 参数
查看当前运行的所有 jobs,-a 可以查看被取消运行的 job
./flink list [-a]
取消 JobID 的运行
./flink cancel JobID
# jobManager 高可用
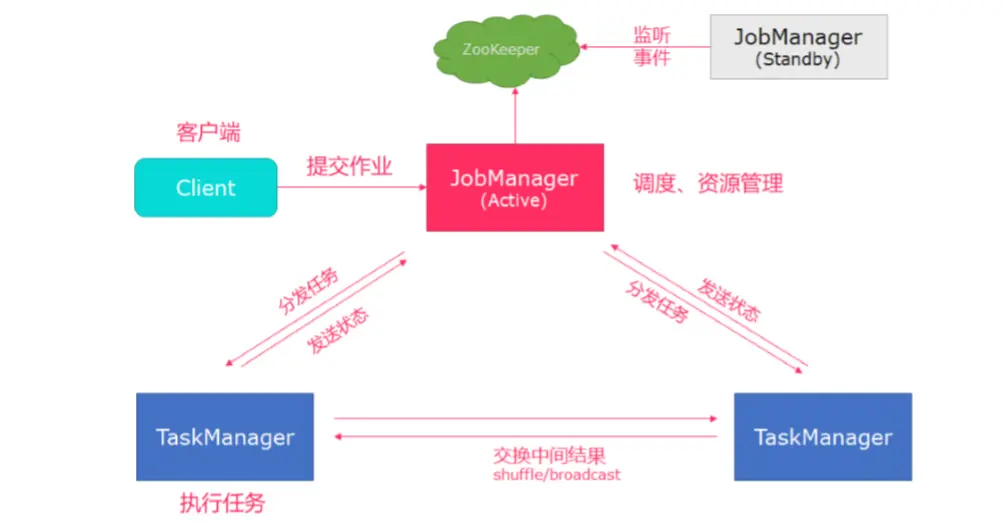
- 在 flink-1.12.2/conf 下的 flink-conf.yaml 中添加 zookeeper 配置
# 1. 配置jobmanager rpc 地址
jobmanager.rpc.address: xx.xxx.xx.103
# 2. 修改taskmanager内存大小,可改可不改
taskmanager.memory.process.size: 2048m
# 3. 修改一个taskmanager中对于的taskslot个数,可改可不改
taskmanager.numberOfTaskSlots: 4
# 4. 修改并行度,可改可不改
parallelism.default: 4
# 5. 配置状态后端存储方式
state.backend:filesystem
# 6. 配置启用检查点,可以将快照保存到HDFS
state.backend.fs.checkpointdir: hdfs://192.168.244.129:9000/flink-checkpoints
# 7. 配置保存点,可以将快照保存到HDFS
state.savepoints.dir: hdfs://192.168.244.129:9000/flink-savepoints
# 8. 使用zookeeper搭建高可用
high-availability: zookeeper
# 9. 配置ZK集群地址
high-availability.zookeeper.quorum: xx.xxx.xx.103:2181
# 10. 存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://xx.xxx.xx.103:9000/flink/ha/
# 11. 配置zookeeper client默认是 open,如果 zookeeper security 启用了更改成 creator
high-availability.zookeeper.client.acl: open
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
- 将配置过的 HA 的 flink-conf.yaml 分发到另外节点
- 分别到另外两个节点中修改 flink-conf.yaml 中的配置
- 在 masters 配置文件中添加多个节点
- 分发 masters 配置文件到另外两个节点
- 配置每个 flink 下的 zoo.cfg 文件
# 新建snapshot存放的目录,在flink-1.12.2目录下建
mkdir tmp
cd tmp
mkdir zookeeper
#修改conf下zoo.cfg配置
vim zoo.cfg
#snapshot存放的目录
dataDir=/opt/software/flink-1.12.2/tmp/zookeeper
#配置zookeeper 地址
server.1=xx.xxx.xx.103:2888:3888
2
3
4
5
6
7
8
9
10
- 下载 hadoop 依赖包,每个 flink 节点都需要
下载地址:https://flink.apache.org/downloads.html#additional-components
将包复制到flink-1.13.2/lib目录下
2
- 启动 flink 集群
./start-cluster.sh
# Yarn 模式
以 Yarn 模式部署 Flink 任务时,要求 Flink 是有 Hadoop 支持的版本,Hadoop 环境需要保证版本在 2.2 以上,并且集中安装有 HDFS 服务以及配置了相关 flink、hadoop 的环境变量。yarn 部署有两种方式,如下图介绍:
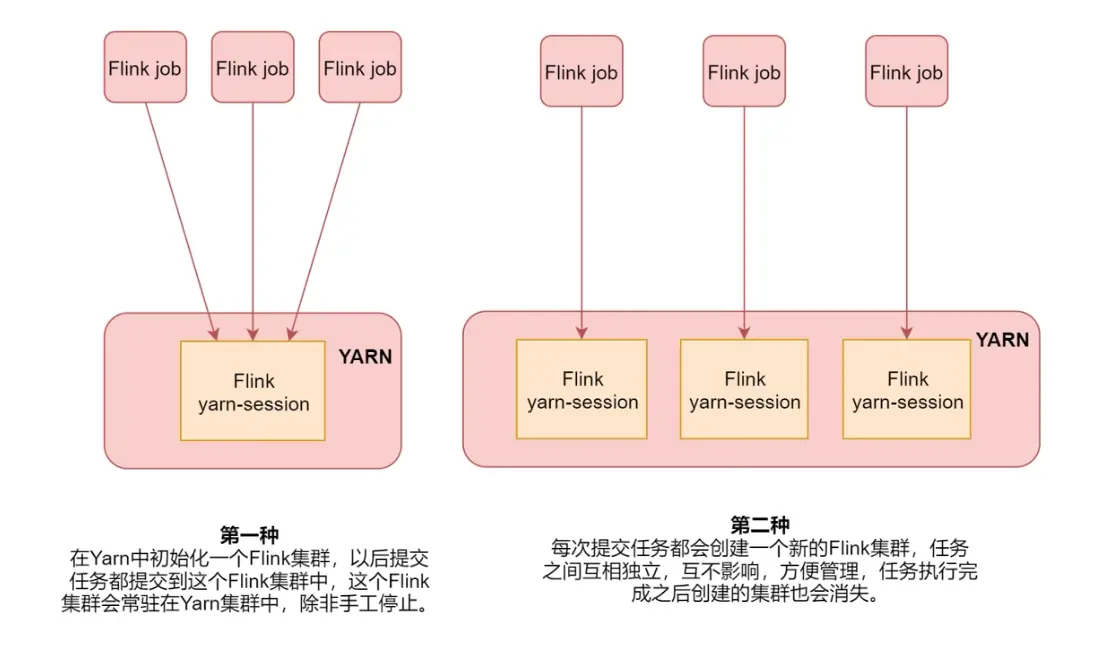
实际工作过程中推荐第二种方式进行部署,比较方便管理。
# 方式一
- 检查 hadoop 环境变量是否配置 HADOOP_CLASSPATH
HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`
- 启动 flink/bin/yarn-session.sh
bin/yarn-session.sh -jm 1024m -tm 1024m -d
- jm jonmanager 的内存
- tm 每个 taskmanager 的内存
- d 后台运行
- 额外参数 -D <arg> 动态属性
- 额外参数 -j,--jar <arg> 指定 Flink 任务依赖的 jar 包
- 额外参数 -nm,--name 在 yarn 上为一个自定义的应用设置一个名字
- 额外参数 -q,--query 显示 yarn 中可用的资源 (内存,cpu 核数)
- 额外参数 -qu,--queue <arg> 指定 yarn 队列
- 额外参数 -s,--slots <arg> 每个 taskManager 使用的 slots 数量
- 停止集群
yarn application -kill (yarn的flink id)
# 方式二
直接在 flink/bin 下运行命令即可,运行完成后会在 yarn 集群中创建一个临时的 flink 集群,当任务结束后对应的临时集群结束。
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./要运行任务的jar
- -m,--jobmanager host:port 动态指定 jobmanager (主节点) 地址
- -c,--class <classname> 动态指定 jar 包入口
- -p,--parallelism <parallelism> 动态指定程序的并行度,可以覆盖配置文件中的默认值
bin/flink run ./examples/batch/WordCount.jar 会从本机 /tmp.yarn-properties-root 中的节点中找到 applicationId 来找到对应的那个 Flink 集群,提交到对应的 Flink 集群中
bin/flink run -m hostname:port ./examples/batch/WordCount.jar 通过 - m 来指定 Flink 集群里面主节点的主机名,端口号,就是指定 jobmanager 的 host 和 port,表示你已知一个 Flink 集群了,提交到这个集群中
bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar 表示在 yarn 集群里面去创建一个临时的 Flink 集群,并且把这个任务提交到临时的 Flink 集群中执行。
# flink-yarn 的好处
- 提高大数据集群中机器的利用率
- 一套集群,可以执行 MR 任务,Spark 任务,Flink 任务等