 ES 7.8.0(二) 读、写和写索引流程以及文档分析过程
ES 7.8.0(二) 读、写和写索引流程以及文档分析过程
# 读写及更新流程
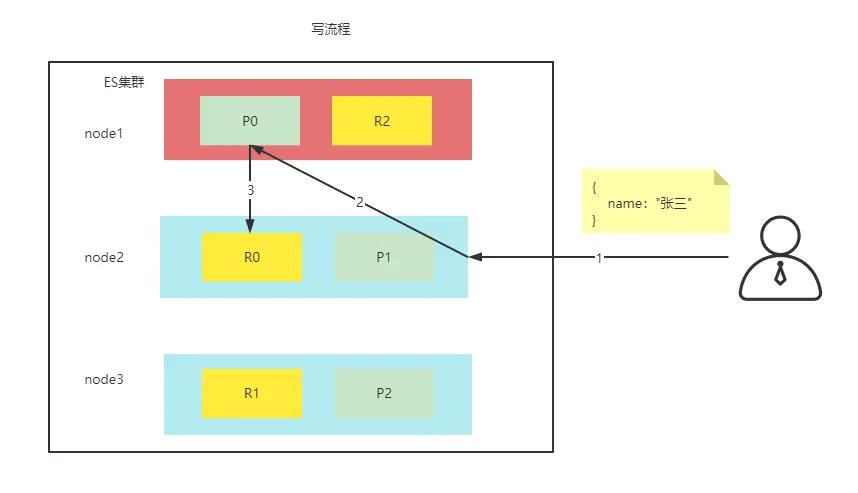
P 代表着分片,R 代表着副本,从图中可以看出有 2 个分片,每个分片在不同的节点上,而一个节点上有其他分片的副本,ES 为内部会把分片和副本均匀的散在节点上。具体写流程如下:
- 客户端请求集群(任意)节点,找到的节点会被称为协调节点,图中为指定 node2 为协调节点
- 协调节点将请求经过对数据 hash (id) % 分片数量 得到结果后请求到另个节点或自己,图中为 P0
- 主分片会将请求的数据进行保存
- 主分片会将数据发送给拥有该分片副本的节点,进行数据同步
- 副本保存完后进行成功反馈
- 主分片得到反馈后,把自己的结果一并反馈给客户端
| 参数 | 描述 |
|---|---|
| consistency | 默认值:quorum,即大多数的分片副本状态没问题就允许执行写操作;one,只要主分片状态 ok 就允许执行写操作;all,必须所有主分片和所有副本的状态没问题才允许执行写操作 |
| timeout | 如果没有足够的副本,ES 会等待,希望更多的副本出现,默认情况下是 1 分钟,你可以任意更改如 30s |
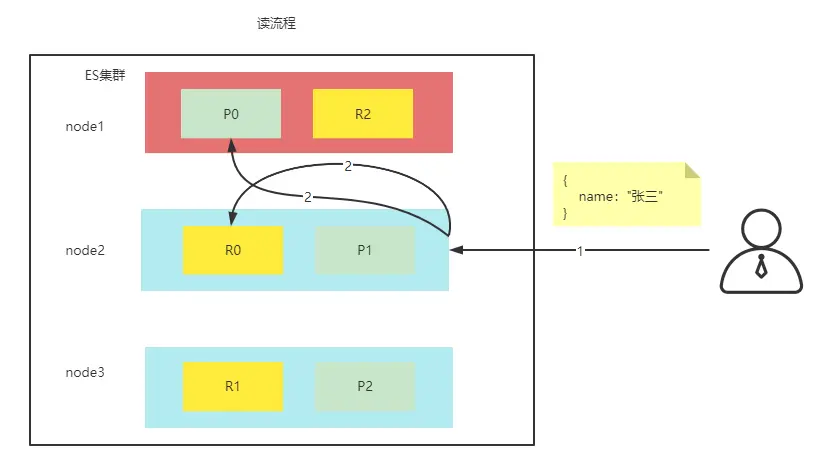
- 客户端发送请求到协调节点
- 协调节点计算得到数据所在的分片位置以及全部的副本位置
- 得到分片位置和副本所有的位置,为达到负载均衡,进行轮训,找到一个不是很忙的节点。
- 把请求转发给节点,节点得到数据并返回给客户端。
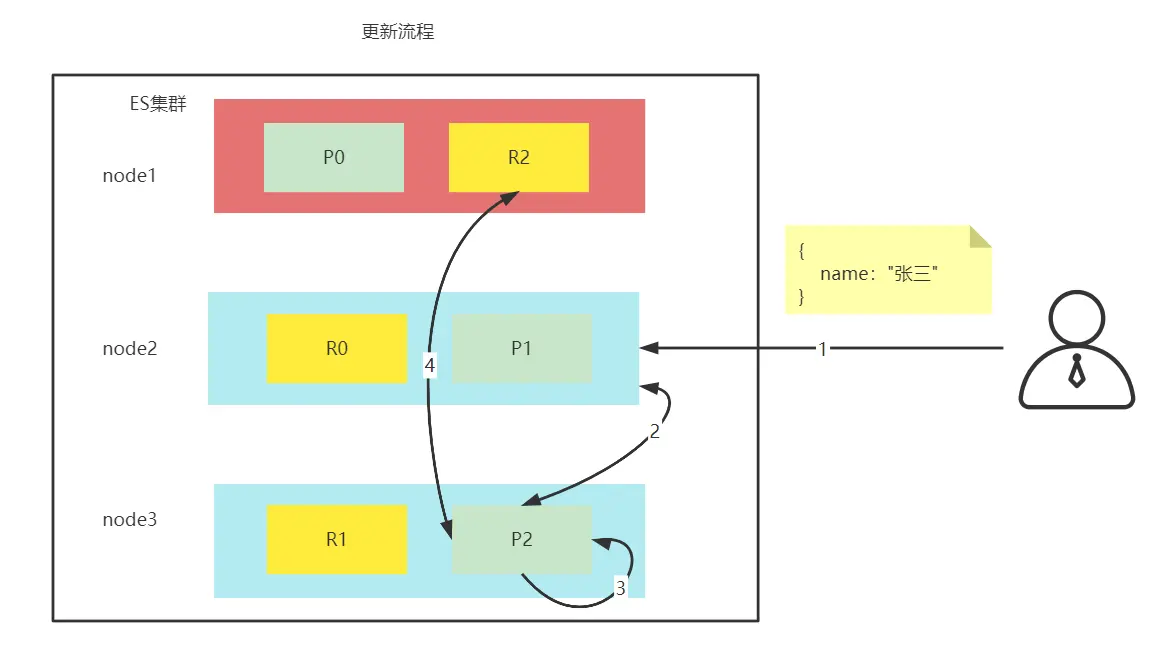
- 客户端发送请求到协调节点
- 协调节点计算得到数据所在的分片位置以及全部的副本位置
- 修改,为防止多个线程修改,他会不停的尝试修改
- 修改成功后修改副本,副本修改成功后会通知主分片,主分片在反馈给客户端
# ES 写索引流程
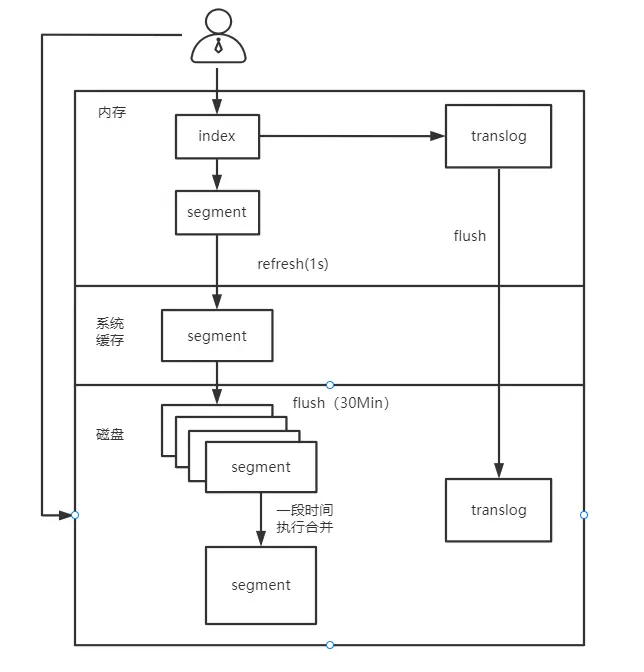
- 用户创建了一个新文档,新文档被写入内存中;
- refresh 操作提交缓存,这时缓存中数据会以 segment 的形式被先写入到文件缓存系统。这是因为,提交一个新的 segment 到磁盘需要一个 fsync 来确保 segment 被物理性地写入磁盘,这样在断电的时候就不会丢失数据。 但是 fsync 操作代价很大,如果每次索引一个文档都去执行一次的话会造成很大的性能问题,但是这里新 segment 会被先写入到文件系统缓存,这一步代价会比较低;
- 新的 segment 被写入到文件缓存系统,这时内存缓存被清空。在文件缓存系统会存在一个未提交的 segment。虽然新 segment 未被 commit(刷到磁盘),但是文件已经在缓存中了,此时就可以像其它文件一样被打开和读取了;
- 到目前为止索引的 segment 还未被刷新到磁盘,如果没有用 fsync 把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。如上图所示,一个文档被索引之后,就会被添加到内存缓冲区,并且同时追加到了 translog;
- 每隔一段时间,更多的文档被添加到内存缓冲区和追加到事务日志(translog),之后新 segment 被不断从内存缓存区被写入到文件缓存系统,这时内存缓存被清空,但是事务日志不会。随着 translog 变得越来越大,达到一定程度后索引被刷新,在刷新(flush)之后,segment 被全量提交(被写入硬盘)。
# 文档分析
分析器包含 将一块文本分成合适于倒排索引的独立的词条,将这些词条统一化为标准格式以提高它们的"可搜索"性,或者recall。 分析器做着如上的工作,但分析器只包含了三个主要的功能:
- 字符过滤器
首先,字符串按顺序通过每个字符过滤器,它们的任务是在分词前整理字符串。一个字符串过滤器可以用来去掉 HTML,或者将 & 转化为 and。 - 分词器
其次,字符串被分词器分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。 - Token 过滤器
最后,词条按顺序通过每个 Token 过滤器。这个过程可能会改变词条(例如,小写化 Quick),删除词条(例如,像 a,and,the 等无用词),或者增加词条(例如,像 jump 和 leap 这种同义词)
# 内置分析器
Elasticsearch 还附带了可以直接使用的预包装的分析器。接下来我们会列出最重要的分析器:
- 标准分析器
标准分析器是 Elasticsearch 默认使用的分析器。它是分析各种语言文本最常用的选择。他根据 Unicode 联盟定义的单词边界划分文本。删除绝大部分标点。最后,将细条小写。 - 简单分析器
简单分析器在任何不是字母的地方分割文本,将词条小写。 - 空格分析器
空格分析器在空格的地方划文本。 - 语言分析器
特定语言分析器可用于很多语。他们可以考虑指定语言的特点。例如,英语分析器附带了一组英语无用词(常用单词,例如 and 或者 the,他们对相关性没有多少影响),他们会被删除。由于理解英语语法的规则,这个分词器可以提取英语单词的词干。
# 测试分析器
标准分析器
curl --location --request GET 'http://10.240.30.93:9200/user/_analyze' \
--header 'Content-Type: application/json' \
--data-raw '{
"analyzer":"standard",
"text": "Text to analyzer"
}'
{
"tokens": [
{
"token": "text", // token 分解后的词条
"start_offset": 0, // 偏移量
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0 // 位置
},
{
"token": "to",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "analyzer",
"start_offset": 8,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 2
}
]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
IK 分词器,这款分词器是 ES 自带,并不是理想的那么好
curl --location --request GET 'http://10.240.30.93:9200/user/_analyze' \
--header 'Content-Type: application/json' \
--data-raw '{
"text": "测试用例"
}'
{
"tokens": [
{
"token": "测",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "试",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "用",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "例",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# ik_max_word
curl --location --request GET 'http://10.240.30.93:9200/user/_analyze' \
--header 'Content-Type: application/json' \
--data-raw '{
"analyzer":"ik_max_word",
"text": "测试用例"
}'
{
"tokens": [
{
"token": "测试",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "试用",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "例",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 2
}
]
}
# ik_smart
curl --location --request GET 'http://10.240.30.93:9200/user/_analyze' \
--header 'Content-Type: application/json' \
--data-raw '{
"analyzer":"ik_smart",
"text": "测试用例"
}'
{
"tokens": [
{
"token": "测",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "试用",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "例",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 2
}
]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
ES 中也可以进行扩展词汇,首先进入 ES 根目录中的 plugins 的 ik 文件夹下,进入 config 目录,创建 custom.dic 文件,写入关键词。之后打开 IKAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中,重启 ES 服务器。
如:张一健
# 创建 custom.dic 文件,键入关键词,并保存退出
# 在 IKAnalyzer.cfg.xml 指定文件
<entry key="ext_dict">custom.dic</entry>
1
2
3
2
3
测试
# 配置之前
curl --location --request GET 'http://10.240.30.93:9200/user/_analyze' \
--header 'Content-Type: application/json' \
--data-raw '{
"analyzer":"ik_max_word",
"text": "张一健"
}'
{
"tokens": [
{
"token": "张",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "一",
"start_offset": 1,
"end_offset": 2,
"type": "TYPE_CNUM",
"position": 1
},
{
"token": "健",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
}
]
}
# 自定义后
{
"tokens": [
{
"token": "张一健",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "一",
"start_offset": 1,
"end_offset": 2,
"type": "TYPE_CNUM",
"position": 1
},
{
"token": "健",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
}
]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
上次更新: 1/1/2026, 8:54:37 PM