 ES 7.8.0(一) 入门介绍
ES 7.8.0(一) 入门介绍
# 基础概念
- 索引(index)
ES 的索引类似于 MySQL 的库 - 类型(type)
在一个索引中可以有一个或多个类型,通常会为相同文档格式的归为一个类型,但在 ES7.x 默认不在支持索引类型的操作,文档和索引直接产生关系。 - 文档(doc)
文档就是我们的 JSON 数据,一个索引有多个文档 - 字段(field)
就是文档 JSON 中的属性 - 映射(mapping)
MySQL 表中会有相关的字段类型,是否为空,长度多少,是否索引,这些和 ES 中的 Mapping 相似,可以定义一个属性,以及他的类型,是否可以被索引等。 - 分片(Shards)
ES 的分片相当于 MySQL 的水平分表,比如 id % 5,不同结果落到各个被定义好的表中,可以扩展我们的存储容量,有效提高查询性能 - 副本(replicas)
分片可以把数据分布到各个节点上,统一提高服务,可某个节点崩溃就会导致数据的丢失,副本就是保证分片的数据高可用的一种方案,把数据在另一台服务器复制一份。副本也可以提升一定的性能,因为搜索可以在所有的副本上并运行。 - 分配(Allocation)
# 单机安装
官网地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch,需要用一些科学手段,否则内容加载不全,不好找到我么你需要的版。
# 下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-linux-x86_64.tar.gz
# 解压
tar -xvf elasticsearch-7.8.0-linux-x86_64.tar.gz
# 启动
cd elasticsearch-7.8.0/bin
./elasticsearch
# 报错,我得是jdk8,他需要jdk11
future versions of Elasticsearch will require Java 11; your Java version from [/opt/software/jdk/jre] does not meet this requirement
# 修改es配置文件
cd elasticsearch-7.8.0/bin
vim elasticsearch-env
# 找到有JAVA_HOME的判断,设置成 es 自带的jdk,如下是我的
if [ ! -z "$JAVA_HOME" ]; then
JAVA="/opt/software/elasticsearch-7.8.0/jdk/bin/java"
JAVA_TYPE="JAVA_HOME"
else
# 重新启动,然后又报错,意思是不能用root运行
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
# 创建用户,并赋予权限
adduser es
# 修改es用户的密码
passwd es
# 修改
chown -R es:es elasticsearch-7.8.0/
# 切换用户登录,启动程序
su es
# 如果遇到该类报错
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
# 需要修改一下参数,进入 vim /etc/security/limits.conf
# sandwich表示运行elasticsearch的用户,hard与soft表示限制的类型,nofile表示max number of open file descriptors,65536表示设置的大小。
# 这个值最终影响的是 ulimit 的open files的最大值
* hard nofile 65536
* soft nofile 65536
# 修改另一个文件, vim /etc/sysctl.conf,添加如下,后执行 sysctl -p
vm.max_map_count=655360
# 修改 vim elasticsearch.yml,配置远程访问,及修改以上问题
network.host: 0.0.0.0
discovery.seed_hosts: ["10.240.30.93"]
cluster.initial_master_nodes: ["master"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
端 9300 端口为 ES 集群间组件的通信口,9200 端口为浏览器访问的 http 协议 restful 端口。当 ES 启动成功后我们可以通过访问 http://localhost:9200 测试结果
# 数据格式简介
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们 Elasticsearch 里存储文档数据和关系型数据库 MYSQL 存储数据的概念进行一个类比
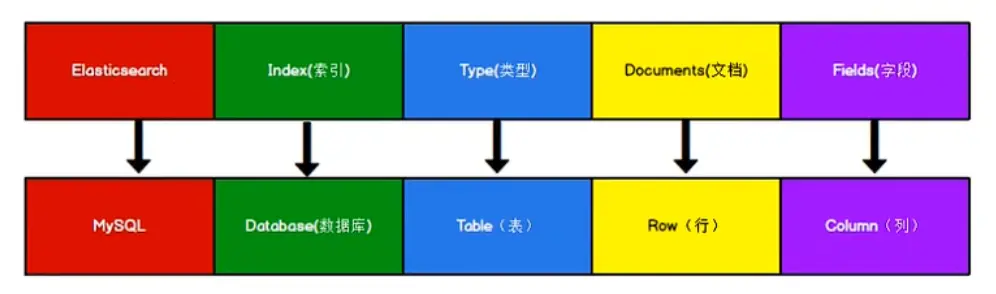
ES 里的 Index 可以看做一个库,而 Types 相当于表,Document 则相当于表的行。这里 Types 的概念已经被主键弱化,ES6.x 中,一个 Index 下已经只能包含一个 Type,ES7.x 中,Type 的概念已经被删除了。
在 MySQL 中索引是帮助查询进行快速检索,但在 ES 中为了能够坐高快速准确的查询,他使用了 倒排索引 ,有倒排索引则对应有 正排索引
- 正排(正向)索引 -> 在 MySQL 中,如 id,content 两个字段,通过 id 并赋予一定的索引,可以快速检索到该列满足条件的数据,但如果通过内容查询则比较麻烦,需要做模糊查询,每条数据都需要遍历,效率低下,而且还要区分内容的大小写等。
id content
-------------------------------------------
1001 my name is zs
1002 my name is ls
2
3
4
- 倒排索引 -> 倒排索引是实现 “单词 - 文档矩阵” 的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
keyword id
-------------------------------------------
my 1001,1002
ls 1002
zs 1001
2
3
4
5
# 基本操作
# 索引
# 创建索引
curl --location --request PUT 'http://10.240.30.93:9200/test_index'
# 查看索引
查询某个索引的信息
curl --location --request GET 'http://10.240.30.93:9200/test_index'
查看所有索引有哪些
curl --location --request GET 'http://10.240.30.93:9200/_cat/indices?v'
# 删除索引
curl --location --request DELETE 'http://10.240.30.93:9200/test_index'
# 文档操作
# 创建文档
创建一个随机生成 ID 的文档,索引是 test_index
curl --location --request POST 'http://10.240.30.93:9200/test_index/_doc' \
--header 'Content-Type: application/json' \
--data-raw '{
"min_position": 7,
"has_more_items": false,
"items_html": "Bike",
"new_latent_count": 5,
"data": {
"length": 21,
"text": "Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur."
},
"objArray": [
{
"class": "lower",
"age": 2
},
{
"class": "lower",
"age": 1
}
]
}‘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
创建一个自定义 ID 位 1003 的文档,
curl --location --request POST 'http://10.240.30.93:9200/test_index/_doc/1003' \
--header 'Content-Type: application/json' \
--data-raw '{
"min_position": 7,
"has_more_items": false,
"items_html": "Bike",
"new_latent_count": 5,
"data": {
"length": 21,
"text": "Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur."
},
"objArray": [
{
"class": "lower",
"age": 2
},
{
"class": "lower",
"age": 1
}
]
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 查询文档
通过 ID 查询文档
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/1003'
查看 test_index 下的所有文档
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search'
# 修改文档
完全覆盖以前文档的内容
curl --location --request PUT 'http://10.240.30.93:9200/test_index/_doc/1003' \
--header 'Content-Type: application/json' \
--data-raw '{
"data": {
"length": 26,
"text": "Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."
},
"numericalArray": [
30,
33,
31,
20,
30
],
"StringArray": [
"Carbon",
"Oxygen",
"Carbon",
"Oxygen"
]
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
只修改文档中某些属性的值
curl --location --request POST 'http://10.240.30.93:9200/test_index/_update/1003' \
--header 'Content-Type: application/json' \
--data-raw '{
"doc":{
"data":{
"text": "1111111111"
}
}
}'
2
3
4
5
6
7
8
9
通过 ID 删除某个文档
curl --location --request DELETE 'http://10.240.30.93:9200/test_index/_doc/1003'
# 条件查询
通过请求路径添加参数,注意附加 q(query) 条件的意思
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search?q=items_html:Bike'
通过 body 体附加条件进行查询
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"match":{
"items_html":"Bike"
}
}
}'
2
3
4
5
6
7
8
9
通过 body 体加条件查询索引下全部文档
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"match_all":{
}
}
}'
2
3
4
5
6
7
8
9
分页查询,from 为起始位置,size 为每页大小,分页 =(from-1)*size;_source 可以指定我们需要查询的具体属性值,类似于 mysql 我们只想看哪些列的数据。
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"match_all":{
}
},
"from": 0,
"size": 2,
"_source": ["min_position"]
}'
2
3
4
5
6
7
8
9
10
11
12
对数据进行排序
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"match_all":{
}
},
"sort":{
"new_latent_count": {
"order": "desc"
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
多条件查询,如下类似于 MySQL and 条件
- must,是 and
- should,是 or
- fileter,是范围查询 <<=> >=
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"bool":{
"must":[
{
"match":{
"items_html": "Bike"
}
},
{
"match":{
"has_more_items": false
}
}
]
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"bool":{
"filter":{
"range":{
"data.length": {
"gt": 19
}
}
}
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 全文检索 & 完全匹配 & 高亮查询 & 聚合查询
按照单词查询,只要包含这个单词全部查询出来,如果是汉子的话会把每个汉子放进倒排索引中,该方式称为全文检索。match 是全文匹配,更换为 match_phrase 则是完全匹配。
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"match":{
"data.text":"Duis"
}
}
}'
2
3
4
5
6
7
8
9
高亮查询,我们可以设置高亮来让匹配的内容进行明显的显示
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"match":{
"data.text":"Duis"
}
},
"highlight":{
"fields":{
"data.text": {}
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
聚合查询,对相同内容进行次数统计
curl --location --request GET 'http://10.240.30.93:9200/test_index/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"aggs":{ // 聚合操作
"min_position_count":{ // 聚合后的名称,可以随意起名
"terms": { // 分组操作
"field": "min_position" // 分组字段
}
}
},
"size": 0 // 表示不显示原始数据
}'
2
3
4
5
6
7
8
9
10
11
12
# 映射关系
有的属性可以分词查询,有的属性不能分词查询,这个分还是不分,我们是可以设置的。在 Mysql 中表的一个字段的类型、长度这些信息都属于表的结构信息,在 ES 中也有类似的概念,我们称之为映射。
# 创建一个 user 索引
curl --location --request PUT 'http://10.240.30.93:9200/user'
# 创建结构信息
curl --location --request PUT 'http://10.240.30.93:9200/user/_mapping' \
--header 'Content-Type: application/json' \
--data-raw '{
"properties": { // 定义结构化信息
// 定义一个name 属性
"name": {
"type": "text", // name类型为 text文本(可以被分词)
"index": true // 表示该字段可以被索引查询
},
"sex": {
"type": "keyword", // 表示不能被分词,需要完整匹配
"index": true // 表示该字段使用索引
},
"tel": {
"type": "keyword", // 表示不能被分词,需要完整匹配
"index": false // 表示不能被索引
}
}
}'
# 查看结构化信息
curl --location --request GET 'http://10.240.30.93:9200/user/_mapping' \
--data-raw ''
# 增加数据
curl --location --request POST 'http://10.240.30.93:9200/user/_doc/1003' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "张三",
"sex": "男",
"tel": "135xxxxxx05"
}'
# 有分词效果的查询
curl --location --request GET 'http://10.240.30.93:9200/user/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"match":{
"name":"张"
}
}
}'
# 全部匹配,sex只对应以上值能是 男,如果值是 男的,那么键入 男 也是查不到的,必须是男的
curl --location --request GET 'http://10.240.30.93:9200/user/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"match":{
"sex":"男的"
}
}
}'
# 不能被索引(index: false),索引该属性则会报错,因为不能被索引(查询)
curl --location --request GET 'http://10.240.30.93:9200/user/_doc/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query":{
"match":{
"tel":"135xxxxxx05"
}
}
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
# 分片及副本
创建 user 索引,并为其创建 3 个分片,以及各主分片都有 1 个副本
curl --location --request PUT 'http://10.240.30.93:9200/user' \
--header 'Content-Type: application/json' \
--data-raw '{
"settings":{
"number_of_shards": 3, // 对索引下的文档创建3个分片
"number_of_replicas": 1 // 每个主分片都有1个副本
}
}'
2
3
4
5
6
7
8
查询所创建的索引
curl --location --request GET 'http://10.240.30.93:9200/user'
{
"user": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1653730124456",
"number_of_shards": "3", // 分片
"number_of_replicas": "1", // 副本
"uuid": "E7Li_zHoRHWfsnkgOCy3Tg",
"version": {
"created": "7080099"
},
"provided_name": "user"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
修改副本的数量
curl --location --request PUT 'http://10.240.30.93:9200/user/_settings' \
--header 'Content-Type: application/json' \
--data-raw '{
"number_of_replicas": 2
}'
2
3
4
5
# 集群搭建
一个集群是由多个服务器节点组织在一起,共同持有整个的数据,并一起提供索引和搜索功能。一个 ES 集群有一个唯一的名字,整个名字默认就是 "Elasticsearch"。这个名字是重要的。因为一个节点只能通过指定某个集群的名字,来加入这个集群。
集群中包含很多的服务器,一个节点就是其中一个服务器。作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点也是由名字来标识的,默认情况下,这个名字是一个随机漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说很重要,因为在这个管理过程中,你回去确定网络中的哪些服务器对应于 Elasticsearch 集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做 "elasticsearch" 的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定他们能够相互发现彼此,他们将会自动形成并加入到一个叫做 "elasticsearch" 的集群中。
# node1 修改 elasticsearch.yml
cluster.name: elasticsearch-1 # 指定集群的名称
node.name: node1 # 指定节点的名称
node.master: true # 让该节点作为主节点
node.data: true # 让该节点作为数据节点
network.host: node1 # 指定本机的IP,我的在 host中做个映射
http.port: 9200 # http 请求地址
transport.tcp.port: 9300 # 集群通信端口
http.cors.enabled: true # 跨域配置
http.cors.allow-origin: "*"
http.max_content_length: 200mb # 单条数据最大内容为200Mb的数据
cluster.initial_master_nodes: ["node1"] # es7.x之后新增的配置,初始化个新的集群时需要此配置来选举master
discovery.seed_hosts: ["node1:9300","node2:9300","node3:9300"] # 节点发现
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
cluster.routing.allocation.cluster_concurrent_rebalance: 16 # 集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.node_concurrent_recoveries: 16 # 添加或删除节点及负载均衡时并发恢复的线程个数,默认4个
cluster.routing.allocation.node_initial_primaries_recoveries: 16 # 初始化数据恢复时,并发恢复线程的个数,默认4个
# node2 修改 elasticsearch.yml
cluster.name: elasticsearch-1 # 指定集群的名称
node.name: node2 # 指定节点的名称
node.master: true # 让该节点作为主节点
node.data: true # 让该节点作为数据节点
network.host: node2 # 指定本机的IP,我的在 host中做个映射
http.port: 9200 # http 请求地址
transport.tcp.port: 9300 # 集群通信端口
http.cors.enabled: true # 跨域配置
http.cors.allow-origin: "*"
http.max_content_length: 200mb # 单条数据最大内容为200Mb的数据
cluster.initial_master_nodes: ["node1"] # es7.x之后新增的配置,初始化个新的集群时需要此配置来选举master
discovery.seed_hosts: ["node1:9300","node2:9300","node3:9300"] # 节点发现
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
cluster.routing.allocation.cluster_concurrent_rebalance: 16 # 集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.node_concurrent_recoveries: 16 # 添加或删除节点及负载均衡时并发恢复的线程个数,默认4个
cluster.routing.allocation.node_initial_primaries_recoveries: 16 # 初始化数据恢复时,并发恢复线程的个数,默认4个
# node3 修改 elasticsearch.yml
cluster.name: elasticsearch-1 # 指定集群的名称
node.name: node3 # 指定节点的名称
node.master: true # 让该节点作为主节点
node.data: true # 让该节点作为数据节点
network.host: node3 # 指定本机的IP,我的在 host中做个映射
http.port: 9200 # http 请求地址
transport.tcp.port: 9300 # 集群通信端口
http.cors.enabled: true # 跨域配置
http.cors.allow-origin: "*"
http.max_content_length: 200mb # 单条数据最大内容为200Mb的数据
cluster.initial_master_nodes: ["node1"] # es7.x之后新增的配置,初始化个新的集群时需要此配置来选举master
discovery.seed_hosts: ["node1:9300","node2:9300","node3:9300"] # 节点发现
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
cluster.routing.allocation.cluster_concurrent_rebalance: 16 # 集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.node_concurrent_recoveries: 16 # 添加或删除节点及负载均衡时并发恢复的线程个数,默认4个
cluster.routing.allocation.node_initial_primaries_recoveries: 16 # 初始化数据恢复时,并发恢复线程的个数,默认4个
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
我们可以通过 ES 提供的接口 API 来查看集群的状态
# 查看节点
curl --location --request GET 'http://10.240.30.93:9200/_cat/nodes'
# 查看集群状态
curl --location --request GET 'http://10.240.30.93:9200/_cluster/health'
# 返回信息
{
"cluster_name": "elasticsearch-1", // 集群名称
"status": "yellow",
"timed_out": false,
"number_of_nodes": 1, // 有多少个节点
"number_of_data_nodes": 1, // 有多少个数据节点
"active_primary_shards": 2, // 分片
"active_shards": 2,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 2,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50.0
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
当你在同一台服务器上启动两个节点时,只要他和第一个节点的 cluster.name 配置相同,它就会自动发现集群并加入到其中。当若在不同服务器启动两个节点,如果要加到同一个集群中,你需要配置一个单播主机列表,之所以配置为使用单播,以防止节点无意加入到某个集群。只有在同一台服务器上运行的节点才会自动组成集群。
如果出现未被分出的副本,则集群状态会是(yellow),并不代表不健康,只是这些副本没有被有效的分配和使用,我们可以根据我们的副本数量来扩展服务器,新启动的节点会立马被安排均匀享有分片和副本数据,已达到每个分片和副本在不同的节点。
当集群中过的主节点故障,会从集群中选取一个节点为主节点,并且分片也为主分片,所有的写操作也都会进入到这个节点。