 ClickHouse 副本配置
ClickHouse 副本配置
本文及后续所有文章都以 21.7.3.14-2 做为版本讲解和入门学习
副本的目的主要是保障数据的高可用性,即使一台 Clickhouse 节点宕机,那么也可以从其他服务器获得相同的数据。
# 流程
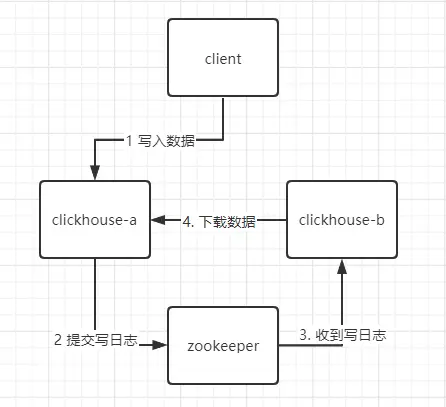
clickhouse 没有主从之分,每个节点都是主节点
# 配置
需要副本的话要启动 zookeeper,并在 clickhouse 配置 zookeeper。配置可以在 /etc/clickhouse-server/config.xml 中配置,也可以在 /etc/clickhouse-server/config.d/ 文件夹下创建配置文件 (xxx.xml) 来指定。
我选择创建文件配置方式 zookeeper.xml,zookeeper 非集群模式,配置一个就行。
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
修改所创建文件的权限,一般我们都是 root 操作的要改成 clickhouse
chown clickhouse:clickhouse zookeeper.xml
到 /etc/clickhouse-server/config.xml 中增加
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/zookeeper.xml</include_from>
2
以上配置同步到其他 clickhouse 节点上。
# 建表测试
副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表
create table t_order_rep (
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine = ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_104')
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
2
3
4
5
6
7
8
9
注意引擎为 ReplicatedMergeTree ,Replicated 支持合并树家族的所有方式,如 ReplicatedSummingMergeTree、ReplicatedReplacingMergeTree 等,具体可以查看官网 https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replication/
ReplicatedMergeTree 需要传入两个参数,zoo_path 为 ZooKeeper 中该表的路径,replica_name ZooKeeper 中的该表的副本名称。注意 replica_name ,在不同的 ck 中,名称不能一样。zoo_path 规则通常为 /clickhouse/table/ 分片数量 / 表名
建表成功后会在 zookeeper 多了一级 /clickhouse/table/01/t_order_rep/ 路径,如果有报错说不能在 zookeeper 建表,原因如下:
- 启动的时候是否加载了你的 config.xml 文件,一般直接使用 clickhouse-server 的方式不会加载配置文件。
- 加载 config.xml 的时候权限不足,ck 默认添加了 clickhouse 用户和组,所有相关文件都得让 clickhouse 用户执行。
- zookeeper 配置错误,证明 zookeeper 没问题只需要连接 zookeeper 是否能查看内容就好。
建表成功后,开启另一台 ck 测试建表,replica_name 记得要改一下,然后插入数据查看两遍是否同步数据。
insert into t_order_rep values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00');
2
3
4
5
6