 AI 基础知识
AI 基础知识
# ollama
ollama 是一个简明易用的本地大模型运行框架,只需一条命令即可在本地跑大模型。开源项目,专注于开发和部署先进的大型语言模型(LLM)。与 docker 类似
# ollama 命令
查看 ollama 所有命令
ollama -h
拉去大模型
ollama pull codellama
运行本地大模型
ollama run xxx
ollama run xxx:xxb
2
查看本地大模型
ollama list
查看模型信息
ollama show xxxx
删除大模型
ollama rm xxxx
停止大模型
ollama stop xxxx
# spring ai
# fine-tuning
微调,当有了数据之后,我们需要让大模型回答时附带我们自己的数据,那么就需要微调
# function-call
函数调用,解决一些实时性的问题,比如你问大模型今天天气怎么样?大模型此时数据比较久,可以调用函数
# 角色
角色分为用户 (user),系统 (system), 函数 (function), 助手 (Assistant)
@Bean
ChatClient chatClient(ChatClient.Builder builder){
return builder.defaultSystem("你现在是一个法务部主任,有关于所有的法律问题都能知晓,是世界顶级人物,回答的及专业又通俗易懂")
.build();
}
2
3
4
5
# 基本 api
# model
# ChatClient
用于聊天对话,流式对话,是所有大预言模型的通用组件,因为所有大语言模型基本都有对话功能,所以 spring ai 就封装了这么一个 API
# chatModel
为每个不同大模型建立的,不同大模型有可能在对话方面有些区别,可以用 charmodel 对象来,设置
# imageModel
生成图片的
# audioModel
生成语音或识别的大模型 api
# EmbeddingsModel
嵌入的工作原理是将文本、图像和视频转换成浮点数数组,称为向量。这些向量旨在捕获文本、图像和视频的含义。嵌入数组的长度称为向量维数。
在 Spring AI 配置中指定嵌入模型,意味着在应用程序中进行文本嵌入操作时,将使用这个模型来生成文本的向量表示。
具体来说,嵌入模型会对输入文本进行一系列复杂的处理,包括对文本进行分词、编码以及基于其预训练的权重和架构来生成一个固定维度的向量。这个向量能够捕捉到输入句子的语义特征,使得语义相近的句子生成的向量在向量空间中距离较近,而语义差异较大的句子生成的向量距离较远。
例如,假设有两句话:“我喜欢美丽的花朵” 和 “我喜爱漂亮的鲜花”,这两句话语义相近。使用嵌入模型将它们转换为向量后,这两个向量在向量空间中的距离会相对较近,通过计算向量之间的相似度(如余弦相似度),就可以量化这种语义上的相近程度。
在实际应用中,比如在一个问答系统里,当用户提出问题时,嵌入模型会将问题转换为向量,然后系统可以将这个向量与知识库中已有问题的向量表示进行比较,找出最相似的问题及其对应的答案,从而回答用户的问题。又如在文档检索系统中,嵌入模型将用户的查询语句和文档库中的文档分别转换为向量,通过向量相似度来找到与查询相关的文档。
# moderationModel
敏感词检测模型
# Multimodality
多模态 APi,可以接受语音,文本,图片等信息进行对话回复,比如你可以 上传一张图片,并问关于图片的内容,此时就包含了图片和文本两个信息
# function api
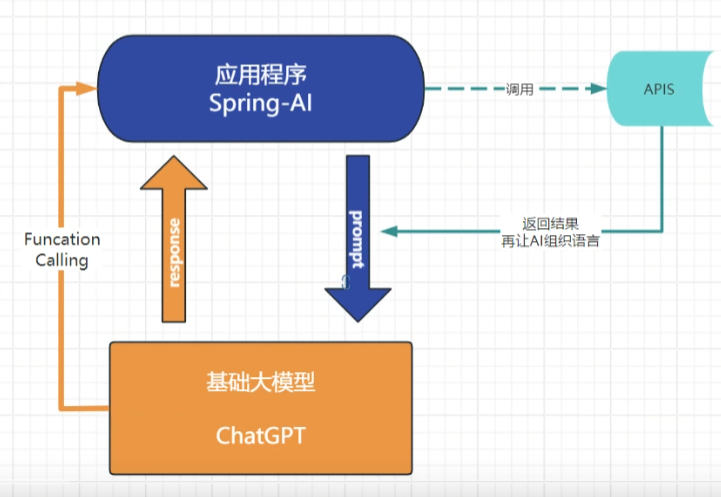
对于实时性的可以使用 function api。流程:把函数注册,然后用户提问,大模型会提取关键字传入 Request,调用注册方法,返回信息给大模型总结,使用方法如下:
// 查询天气,比我想知道一个地址
public class MockWeatherService implements Function<Request, Response> {
// C 是摄氏度(C°), F 是 华氏度(°F)
public enum Unit {C, F}
// 必须要写一个 Request,用于获取关键参数
@JsonClassDescription("Get the weather in location") // 和 @Description 功能一样
public record Request(String location, Unit unit) {
}
// 必须要写一个 Response,返回给大模型相关信息参数
public record Response(double temp, Unit unit) {
}
@Override
public Response apply(Request request) {
// 执行api调用
// 可以从 request 获取地点和单位
return new Response(30.0, Unit.C);
}
}
/**
* @Description 注解是可选的,它提供了一个函数描述,帮助模型了解何时调用函数。这是一个重要的属性,可帮助 AI 模型确定要调用的客户端函数。
* @return
*/
@Bean
@Description("Get the weather in location") // 想要让大模型知道什么时候调用函数,这里就要写好,以便大模型知道什么时候调用,比如要获取天气,可以是:某地区的当前天气
public Function<MockWeatherService.Request, MockWeatherService.Response> currentWeather() {
return new MockWeatherService();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
还有两一种注册方式
@Bean
public FunctionCallback weatherFunctionInfo() {
return FunctionCallback.builder()
.function("CurrentWeather", new MockWeatherService()) // (1) function name
.description("Get the weather in location") // (2) function description
.inputType(MockWeatherService.Request.class) // (3) function signature
.build();
}
2
3
4
5
6
7
8
具体使用,比如我们问:旧金山、东京和巴黎的气候有什么特征?
UserMessage userMessage = new UserMessage("What's the weather like in San Francisco, Tokyo, and Paris?");
ChatResponse response = this.chatModel.call(new Prompt(this.userMessage,
OllamaOptions.builder().function("CurrentWeather").build())); // Enable the function
log.info("Response: {}", response);
2
3
4
回复可能是:以下是申请城市的当前天气:- 加利福尼亚州旧金山:30.0°C - 日本东京:10.0°C - 法国巴黎:15.0°C
# ETL Pipeline
ETL 管道,对文本,图片,视频,音频等读取,转换为 List
# Structured Output Converter
结构化输出转换器
# AI Evaluation Testing
ai 评估测试,测试对加载到 Vector Store 中的 PDF 文档执行 RAG 查询,然后评估响应是否与用户文本相关。
# Observability
可观测性
# 微调
微调并不完全是对已有大模型内容进行简单的替换或修改,而是在已有大模型基础上,通过特定方式让模型学习新的知识和模式,以更好地适配所需业务。本质上微调是在预训练大模型的基础上,使用特定领域或任务的数据集对模型的参数进行进一步的调整和优化。预训练大模型已经在大规模的通用数据上学习到了丰富的语言知识、模式和特征表示。微调的目的是让模型在特定的任务或领域数据上进行学习,从而能够捕捉到这些数据的独特特征和规律,使模型在该特定场景下表现得更好
微调和 RAG 是两个概念,一个是微调原有基础大模型参数,已达到更好的效果;RAG 是依赖于外部数据,偏向实时一些的数据。
# rag 检索增强生成
RAG 的核心作用是在大语言模型生成回答时,引入外部数据源中的相关信息,以提高回答的准确性和相关性。他和 function api 容易混淆,function api 是为了获取精确的结果和执行特定的任务,比如:我们可以通过 function api 查询数据库(给与查询所需要特定的字段),或实时天气,数学计算等。
RAG 被称为检索增强生成,适用于需要准确回答特定问题、提供专业知识或最新信息的场景,如智能客服、知识问答系统等。可以把你的文本信息,资料等存储到数据库中,这个数据库可不是我们以前用的关系型数据库,而是向量数据库,这种名词叫做 Embedding(绑定) 。
# 数据切块
获取文件,数据切块
# 存向量库
转换为文档,存向量库
# 差向量库
把查询问题转换为向量,然后去数据库中查询最相似的向量,转换为文档
# 构建提示词
查询出来的文档内容拼接上下问,构建提示词,调用大模型